Маркетинг • 28 июня 2022 • 5 мин чтения
Что такое семантическое ядро: зачем нужно, как собрать, как использовать
Оптимизация сайта и его структуры — процесс в несколько этапов. Разбираем первый, подготовительный этап по сбору и анализу семантического ядра. Сначала расскажем, что такое семантическое ядро и как оно связано со структурой сайта. Потом покажем, что делать с готовым семантическим ядром: как парсить и подходить к кластеризации.
- Что такое семантическое ядро
- Семантическое ядро или структура сайта — с чего начать
- Какие бывают ключевые слова
- Как подобрать ключевые слова для семантического ядра
- Как отфильтровать и сгруппировать ключи
- Что делать дальше
Что такое семантическое ядро
Семантическое ядро (СЯ, «семантика») — это набор ключевых запросов, которые описывают сайт и то, что на нём размещается. Семантическое ядро есть у каждой страницы на сайте. Из всех ключевых слов формируется большое СЯ сайта.
Ключевой запрос («ключ») — это обычные запросы, которые пользователи вбивают в поисковик, когда ищут что-то в интернете. «Ключ» — одно из словосочетаний из семантического ядра, по нему работает SEO-выдача. «Ключи» продвигают сайты на первые страницы поиска в поисковиках.
Разберём на примере, как собрать семантическое ядро. Есть интернет-магазин, где продаётся мороженое. Опишем ассортимент: «эскимо в шоколаде», «пломбир в стаканчике», «рожок», «торт-мороженое», «низкокалорийное мороженое», «пломбир без сахара», «протеиновое мороженое». В кавычках ключевые запросы сайта, всё вместе — это семантическое ядро.
Все эти ключевые запросы не нужно придумывать самостоятельно. Иначе можно сделать искусственное СЯ: вроде бы запросы хорошие, но их никто не использует. Стоит обращаться к специальным инструментам, о них расскажем позже.
Семантическое ядро запросов — это ядро продвижения. Важно правильно собрать его, иначе не получится продвигаться, вести контекстную рекламу и приводить клиентов. Составление и анализ семантического ядра — основа для работы в контекстной рекламе и SEO-продвижении.
Семантическое ядро или структура сайта — с чего начать
Правильное семантическое ядро помогает структурировать сайт. Есть два основных способа работать с СЯ: с нуля и «по факту».
Структура семантического ядра с нуля
Допустим, ещё нет интернет-магазина с мороженым, он только планируется. Владелец бизнеса начал работу над сайтом, обратился к разработчику и SEO-оптимизатору. Вводные — ассортимент интернет-магазина, под которые будет собираться СЯ.
Вот как будем действовать:
-
Первым шагом занимаемся составлением семантического ядра сайта. Это та «материя», из которой начнём лепить структуру сайта. Для этого проанализируем поисковые запросы пользователей и соберём СЯ под все страницы будущего сайта. Собирать ключевые запросы будем в Wordstat — почитайте нашу статью про этот инструмент.
-
Следующий этап — кластеризация запросов по страницам продуктов и категориям.
Кластеризация — это деление ключевых запросов из семантики на кластеры. Каждый кластер — своя тема.
Важно кластеризовать запросы, чтобы не попасть в свою же ловушку. Может получиться так, что дважды рассказывается об одном и том же продукте на разных страницах. Значит, мы сами себе конкуренты.
Интернет-ресурс будет использоваться эффективнее, если он подстроен под запросы пользователей. А ещё будет проще интерпретировать аналитику по сайту, если страницы оптимизированы под свои «ключи».
- Наконец рисуем карту сайта и расписываем по ней ключевые запросы.
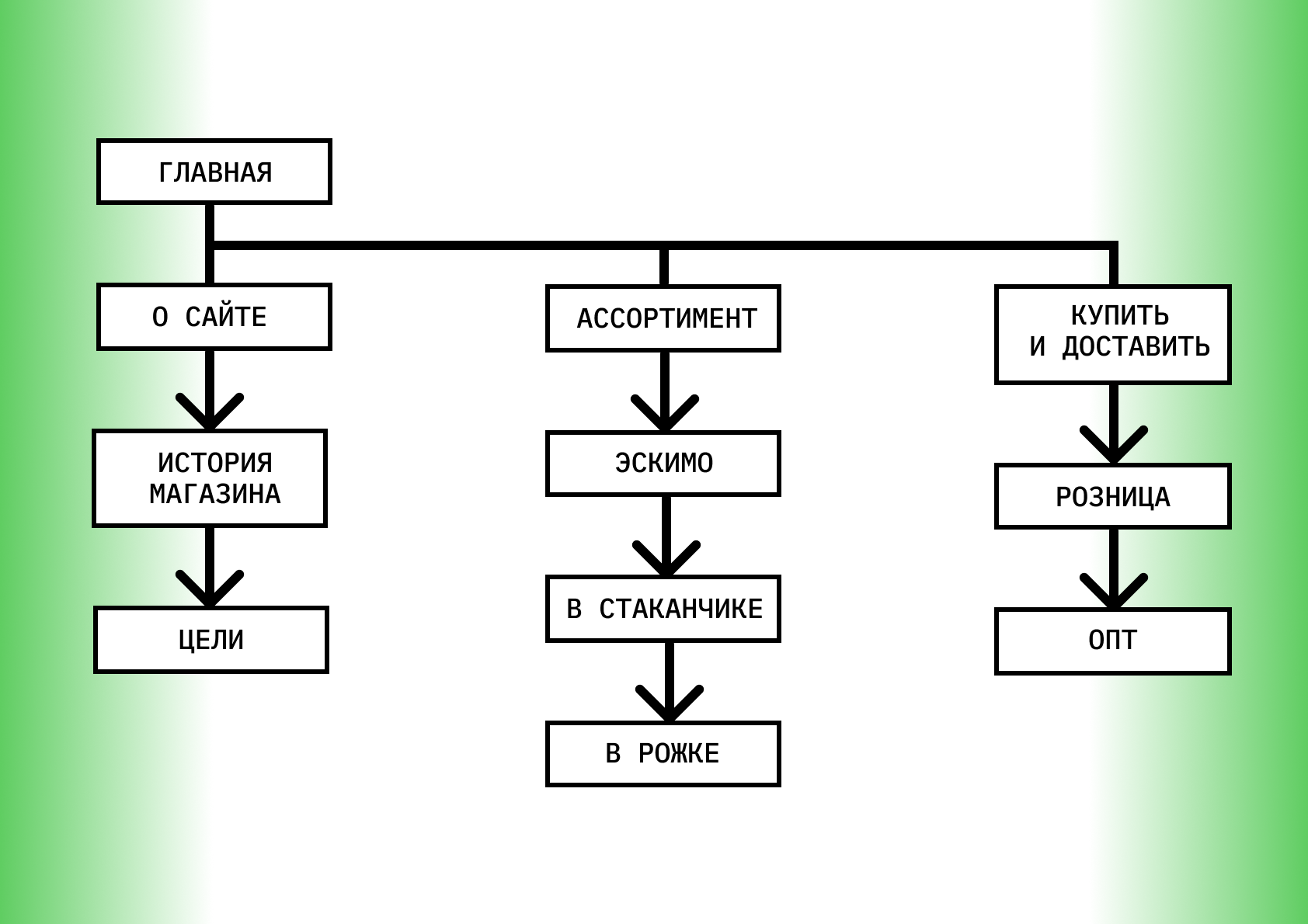
С таким подходом ресурс будет использоваться эффективнее — потому что подстроен под запросы пользователей. Можно легко заметить, что страницы ранжируются по разным запросам, каждая страница оптимизирована под свои «ключи». Это влияет на SEO-продвижение. Например, не стоит продвигать запрос «купить холодильник» вместе с запросом «купить холодильник с морозильной камерой» с одной страницы. Это неверный подход. Правильно будет создать под эти ключевые запросы отдельные посадочные страницы и отдельные кластеры запросов.
Составление семантического ядра под структуру
Если сайт с мороженым существует, остаётся проводить подбор семантического ядра под готовые страницы и разделы. А ещё параллельно можно составлять план по расширению страниц. Например, на сайте есть эскимо и страница под него. При поиске ключевых слов нашлась группа «клубничное эскимо». Значит, если такое эскимо есть в интернет-магазине, под него нужна отдельная разводящая страница со всеми товарами, которые подходят под «клубничное эскимо».
Статистика запросов в Яндекс Wordstat: узнать, что спрашивают люди, и подстроиться под спрос
Какие бывают ключевые слова
Есть несколько признаков, по которым можно классифицировать ключевые слова. Начнём с популярности. Бывают высоко-, средне- и низкочастотные запросы:
● высокочастотные запросы — частота показов от 1 000 либо от 5 000/10 000 показов;
● среднечастотные запросы — до 1 000 либо до 5 000 показов;
● низкочастотные запросы — до 100 либо до 1 000 показов в месяц.
Оценка частоты запроса зависит от тематики сайта, который продвигается. Для интернет-магазина мороженого фраза «купить эскимо шоколадное» с частотой показов около 6 000 в месяц среднечастотная. А для небольшого сайта с домашними мороженицами запрос «сделать мороженое дома» с частотой показов от 1 000 высокочастотный.
Часть поисковых запросов всегда будет низкочастотной. И это хорошо. Когда составляете семантическое ядро, не бегите за высокочастотными запросами, по ним продвигаться труднее. Лучше сфокусироваться на низко- и среднечастотных. Когда займёте хорошие места в выдаче по таким запросам, сможете приблизиться к топу и по высокочастотным ключевым словам.
Станьте универсальным специалистом в интернет-рекламе
Попробуйте себя в роли трафик‑менеджера: пройдите бесплатную вводную часть курса.

Ещё ключевые слова можно разделить по потребностям пользователей:
● Информационные запросы. Это запросы, чтобы найти ответ на определённый вопрос, узнать информацию о чём-то. Например, «почему трава зелёная», «как стать интернет-маркетологом», «плюсы и минусы жизни у моря», «сколько калорий в яйце».
● Транзакционные запросы. Это запросы-действия. Когда вы хотите поздравить племянницу с днём рождения, вы вводите в поисковике «купить конструктор», «заказать шарики», «скачать сценарий детского праздника».
● Навигационные запросы. В таком запросе пользователь указывает домен, сайт, бренд или фирму. Например, «официальный сайт ВДНХ», «курсы Яндекс Практикума».
● Другие запросы. По этим ключам сложно определить, что хочет сделать пользователь. Например, запрос «фикус» может быть и про покупку цветка, и про разведение, и про уход, и про разные сорта фикусов.
Таких запросов лучше избегать при подборе СЯ. Старайтесь делать их более конкретными. При запросе «фикус» не очень понятно, что пользователь ищет и что мы можем ему предложить на странице.
Теперь нужно определиться, как собрать семантическое ядро для сайта. Будем «парсить».
Как подобрать ключевые слова для семантического ядра
Парсинг — это сбор ключевых слов, которые описывают тематику сайта и бизнеса. Берём одну страницу сайта и начинаем «сажать» на неё ключевые слова. Расскажем, как составить семантическое ядро.
Парсить можно разными способами. Например:
● Устроить мозговой штурм. Нужно описать, про что сайт и услуги. Дальше — сформировать запросы, по которым этот сайт можно будет найти.
● Добавить синонимы. Низкокалорийное мороженое могут называть диетическим. Оцените, вбивают ли такой запрос в поисковик. Если да, добавьте в семантическое ядро.
● Изучить конкурентов. Например, через SEMrush.
● Подобрать с помощью сервисов. Мы будем подбирать базовые ключевые слова через Яндекс Wordstat.
Начнём сбор семантического ядра с мозгового штурма. Будем отталкиваться от ассортимента или услуг. Далее под каждую страницу создадим своё детальное СЯ. Например, под «низкокалорийное мороженое»: «пломбир без сахара», «диетическое мороженое», «низкокалорийное мороженое».
Дальше вобьем один из запросов в Вордстат , выберем регион и соберем «ключи». Ориентироваться будем на тему страницы. У нас про готовое мороженое. Значит, не будем брать запросы «рецепт», «как сделать дома». Нам понадобятся запросы «купить низкокалорийное мороженое», «низкокалорийное мороженое цена». В общем, всё, что ищут покупатели, которые хотят купить мороженое.

Ищем «низкокалорийное мороженое» по Москве и области
Как парсить:
● Старайтесь не брать более 10—15 запросов на одну посадочную страницу. Скорее всего, не получится оптимизировать страницу под большее число ключевых слов.
● Учитывайте тематику выдачи по запросу. Оцените выдачу топ-5 по страницам конкурентов. Так будет понятно, стоит ли брать запрос.
● Все ключи нужно подбирать под содержимое страницы. Если страница про эскимо без сахара, её не подстроить под запрос «шоколадное мороженое в стаканчике». Страница не отранжируется, а ещё будет большой процент отказов. На сайт придёт сладкоежка, а потом расстроится и закроет вкладку.
💡 SEO-оптимизация может казаться трудной. На курсе «Интернет-маркетолог» мы помогаем в изучении: занимаемся созданием семантического ядра сайта, проводим технический аудит сайта и учим повышать органический трафик. А ещё рассказываем про другие инструменты диджитал-маркетинга. Начните учиться с бесплатной вводной части.
Парсить и делать семантическое ядро через Wordstat легче с инструментами. Таких инструментов много, мы поделимся двумя.
Расширение для браузера Google Chrome
По умолчанию в Wordstat нельзя формировать списки ключевых слов. Ассистент помогает это делать и создаёт семантическое ядро сайта. Можно добавлять «ключи» вручную, проверять на дубли, по-разному сортировать подборку.
Один из сервисов для парсинга поисковых подсказок. Когда вы что-то вбиваете в поисковую строку Яндекса, вам предлагается несколько запросов в выпадающем окне — это и есть поисковые подсказки.
Инструмент создаст структуру семантического ядра, расширит его и адаптирует под разных пользователей. Познакомьтесь с работой сервиса.
Как отфильтровать и сгруппировать ключи
Мы определили, как выглядит семантическое ядро. Остаётся решить, что с ним делать. Переходим к кластеризации ключевых слов, мы говорили о ней в начале статьи. Напомним, что это.
Кластеризация — деление ключевых запросов из семантики на кластеры. Каждый кластер — своя тема.
С кластеризацией проще структурировать сайт. Так получается древовидная структура — как у интернет-магазинов. Каждый тематический кластер ведёт на свою страницу.
В основе кластеризации лежит интент — от английского intent, «намерение». Это желание пользователя найти что-то в интернете. Интент и приведёт на страницу.
Мы можем разбивать интенты по логике, по семантической схожести и по топам выдачи. Для последнего способа идём в Яндекс и собираем семантику с сайтов из топа выдачи.
Самый надёжный метод кластеризации семантики — ручной. Открываете таблицу и вручную разбиваете ключевые слова на кластеры. Но этот метод и самый затратный, а ещё лучше подойдёт для небольших сайтов. На них не так много ключевых запросов — обычно в пределах 500.
Если у вас большой сайт или мало времени на кластеризацию, можно обращаться к сервисам-помощникам, а вручную уже проверять или дополнять.
Key Collector — популярная программа для контекстологов и SEO-специалистов. Поможет со сбором семантического ядра для сайта и сделает отчёты по запросам.
Это платная программа. Умеет собирать поисковые фразы со шлейфом по запросу, группировать кластеры. Встроены фильтры для подбора лучших запросов. Можно сразу сформировать структуру — сложить «дерево сайта». А ещё в Key Collector легко искать дубли ключевых запросов.
«Словоёб» — бесплатный аналог Key Collector. В этом приложении меньше функций, чем в предыдущем. Но «Словоёб» подойдёт для работы с семантикой на маленьких сайтах. А ещё на нём можно учиться собирать семантическое ядро.
Один из инструментов кластеризации, в котором можно группировать запросы. «Разбивка по Кулакову» не собирает СЯ. В сервис стоит приходить с готовым списком запросов. Инструмент разобьёт их на группы на основании поисковой выдачи по этим запросам и проведёт анализ семантического ядра сайта. Это онлайн-сервис, попробуйте на сайте.
Интерфейс «Разбивки по Кулакову»
Что делать дальше
Подведём итоги:
● Семантическое ядро — это набор ключевых запросов по странице, который описывает её. По таким запросам пользователи находят эту страницу в интернете.
● Ключевые запросы нужны при работе с контекстной рекламой и для SEO-продвижения сайта.
● При составлении семантического ядра ориентируйтесь на поисковую выдачу. Работайте с разными среднечастотными и низкочастотными ключевыми словами.
● Правильно кластеризуйте запросы по структуре сайта и не «сажайте» на одну страницу более 10—15 запросов.
● Развивайте структуру сайта — ориентируйтесь на Wordstat и на ваш ассортимент, добавляйте новые категории страниц и запросы под них в СЯ.
● Собирайте поисковые подсказки к запросам: так страница будет лучше ранжироваться в выдаче.
Итак, есть описанная древовидная структура интернет-магазина с мороженым. К каждой странице или категории собраны запросы. Все запросы разбиты по кластерам и не пересекаются. Инструменты парсинга применены. Готово — можно запускать.
В этой статье мы обсудили, как создать семантическое ядро и что с ним делать. Это не всё с поисковой оптимизацией. Для органического продвижения сайта нужно ещё написать метатеги, сделать перелинковку, скорректировать тексты. Но вся работа по SEO-оптимизации страницы начинается со сбора семантического ядра.
Редактор направления маркетинга

Целевая аудитория:
примеры, определение, портрет ЦА
Что такое ретаргетинг: как воспользоваться вторым шансом на показ
Привет. Я занимался сбором семантического ядра для своего сайта с разными перерывами на протяжении последних 3 лет. До этого лет 10 меня тошнило от самой идеи. Я приступал к этому процессу, бросал, потом пробовал снова и снова бросал. SEO казалось чем-то таким заоблачным. Типа, пришёл какой-то волшебник и что-то там насеошил.
К моему большому сожалению, обилие тренингов, статей, лекций и видосов на YouTube не сильно облегчают понимание процесса сбора и обработки семантики. Перелопачивать все эти тонны воды могут лишь не все😊 А сеошники любят налить воды, мы все про это прекрасно знаем. Смотришь вот так разные тренинги, а у преподов в голове сплошная каша. Когда человек не может сформулировать свои мысли в краткой статье, ему явно не стоит преподавать. Я решил попробовать. Кратко не получилось 😊
На данный момент я занимаюсь внедрением собранной семантики на сайт и решил написать эту статью. Возможно, она поможет тем, кто только начинает в этом разбираться. Мне бы точно очень помогла. Это, по сути, пошаговое руководство. Что, за чем, как и в каком порядке стоит делать. «Делать» никуда не денется, работать придётся много, но зато теперь с пониманием, куда и как двигаться и где вообще конец этого бесконечного тоннеля.
Но, хватит предисловий, приступим к алогоритму.
Важная ремарка. Здесь не будет конкретных рекомендаций по работе с Excel. Будем считать по умолчанию, что интернет маркетолог хорошо знаком с этим инструментом. Key Collector тоже не должен быть для вас чем-то новым.
Также должен сказать, что читать этот мануал по диагонали бесполезно, т.к. он представляет из себя конкретный набор шагов, которые нужно выполнять. Без выполнения, всё это чтение «по буллетам» вам ничего не даст. Делюсь, потому что понимаю, что этот каторжный труд осилят единицы.
Итак, для сбора и обработки семантического ядра вам понадобится:
Доступы:
· Google search console
· Yandex метрика
· Yandex webmaster
Программы:
· Key Collector
· SEO Screaming Frog
· MS Excel
· Надстройка для парсинга yandex webmaster в google chrome
Платные сервисы и услуги:
· 10 прокси для Key Collector
· Pixeltools
· Just Magic
Cбор семантического ядра представляет из себя систему воронок, через которые просеиваются запросы. На каждом из этапов фильтрации вы постепенно избавляетесь от мусора.
Вам предстоит много ручной работы, много часов труда. Чем выше ваша вовлеченность в бизнес и понимание тематики, тем проще вам будет отделить мусор от полезных запросов.
Вводные данные: у вас уже есть сайт, который вы создали по своему усмотрению и пониманию того, каким должен быть идеальный поисковый спрос. Пора столкнуться с суровой реальностью. Сайт приносит какие-то деньги, но хочется больше.
Источники семантики / запросов:
· Keyso — сервис видимости конкурентов
· Счётчики на вашем сайте (метрика, вебмастер, сёрч консоль)
· Yandex wordstat
· Метатеги сайтов конкурентов
· Подсказки в Yandex и Google
ШАГ 1. Сервисы видимости
1. Находите на kwork или подобной бирже человека, который делает выгрузки из keyso за деньги. Покупаете у него выгрузку по 15 основным конкурентам. 15 будет достаточно. Если вы занимаетесь своей темой давно, 15 основных конкурентов у вас уже будут на слуху. Это будет большущая таблица с запросами.
2. Делаем выгрузку из метрики и сёрч консоли
3. Собираем с помощью плагина для google chrome информацию из вебмастера
Где смотреть:
· Метрика: стандартные отчеты — источники — поисковые запросы
· Вебмастер: поисковые запросы — управление группами — все запросы
· Сёрч консоль: эффективность — запросы
Делаете выгрузку за 1 год из этих источников.
ШАГ 2. Парсинг конкурентов
Находите сайты конкурентов. Чем больше найдёте, тем лучше.
Осматриваете сайты на предмет оптимизации. Обычно сразу видно, ведется над сайтом работа или он сделан лишь бы как и не стоит внимания.
Парсите все отобранные сайты с помощью программы SEO Screaming Frog. Вам нужны данные из полей title и h1.
Как правило, у большинства сайтов эти теги сделаны по шаблонам и не составит большого труда удалить из тегов лишнюю информацию и оставить только ключевые слова.
Обрабатываете title и h1 конкурентов в Excel. Собираете всё это в одну большую таблицу.
ШАГ 3. Фильтрация по частотности
Загружаете результаты ваших сборов в Key Collector.
Настройки в KC — вашего региона, если бизнес сильно к нему привязан. Если он универсальный, выставляйте Москву. Там будет больше статистики.
Можно предварительно перед загрузкой в Key Collector заменить в вашей базе слов точки, запятые, тире, дефисы и слэши на знак пробела и почистить фразы от двойных пробелов.
Можно предварительно почистить вашу базу от мусора. На ваше усмотрение. Но я на этом этапе не советую этим заниматься, т.к. база очень большая и проще сначала убрать из неё всё, что можно, автоматически.
К этому моменту вам понадобятся платные прокси. Покупаете их и прописываете в настройках программы Key Collector. Настройки для парсинга не привожу. Нагуглите сами. Вы уже большие.
Итак, вы загружаете в KC вашу базу ключевых слов и парсите базовую частотность с помощью прокси. С вашего основного IP парсить бесполезно. Это пустая трата времени и потенциальный бан от поисковой системы.
Если частотность собирается слишком долго, можно воспользоваться платными сервисами типа https://moab.tools/Parse/CheckWordstat
Ваша задача на этом этапе избавиться от нулевых запросов.
После парсинга базовой частотности переносите нулевые запросы в отдельную мусорную папку в Key Collector. Вы НЕ удаляете запросы. Это нужно для того, чтобы в дальнейшем мусор не попадал в вашу базу по второму кругу.
В вашем проекте в KC теперь будет три папки для мусора:
1. базовая частотность = 0
2. «точная частотность» = 0
3. «!точная !частотность» = 0
Как вы уже поняли, после того, как вы уберете запросы по первому параметру, нужно будет спарсить частотности по двум остальным
После каждого из этапов чистки, запросов в вашей семантике будет оставаться всё меньше, а мусора будет становиться всё больше.
При сборе базовой частотности может оказаться, что для каких-то запросов она не собирается. Это нормально. Запускайте сбор частотности повторно. То, что не собралось, соберется. Останутся:
· запросы слишком длинные (больше 7 слов).
· запросы со спец символами
Кто-то заморачивается и пытается оставить длинные запросы в ядре. У меня не настолько конкурентная тематика, поэтому я их просто переношу в мусор. Поверьте, вам хватит работы и без них. И при желании в дальнейшем к ним можно будет вернуться.
ШАГ 4. ГЕО
После того, как в вашей базе остались запросы с «!точной !частотностью» > 0, мы чистим их по ГЕО. Удаляем гео запросы.
Для этого вы лично формируете свою первую базу минус слов для KC – ГЕО.
Там будут города, населенные пункты, регионы, области, страны в различных вариантах склонений и описаний. Для склонения можно использовать сервис https://morpher.ru/Opt/
ШАГ 5. Мусор, часть 1
После чистки по ГЕО вы составляете собственный словарь мусорных «минус слов». Вы собираете ваш персональный список минус слов, таких как: порно, скачать, форум и прочее.
Список будет постепенно расширяться, упрощая вам первичную фильтрацию в дальнейшем. Не ленитесь добавлять в него частотные мусорные слова. Для каждой тематики такой список минус слов свой собственный. Поэтому не стоит искать какие-то универсальные списки. Создавайте свой собственный.
Слова, которые наиболее часто встречаются в вашем списке запросов можно посмотреть с помощью инструмента «анализ групп» в KC. Да, там можно искать не только что-то полезное, но и мусор. Вообще именно с поиска мусора в этом инструменте и стоит начать. Сканировать список запросов глазами – так вы далеко не уедете.
Удаляем из нашего списка самый очевидный мусор.
ШАГ 6. Бренды
Отделяем брендовые и товарные запросы от чистых категорийных. Для этого вы составляете собственный список брендовых «минус слов». Сюда входят различные варианты написания брендов, транслит, опечатки.
Отсеиваете список запросов по брендам, вынося все такие запросы в отдельную папку «Брендовые запросы».
ШАГ 7. Инфо
Отделение инфо запросов. Составляете ваш собственный словарь минус слов, которые позволят отделить информационные запросы от коммерческих. Сюда входя такие слова как отзывы, топ, рейтинг, лучший, обзор, и т.д.
Убирайте информационку в отдельную папку «информационные запросы»
ШАГ 8. Товарка
Отделяете бренды от товаров. Часто в названиях товаров используются цифры — это один из простейших способов отделить бренды от товаров.
Если брендовый трафик для вас имеет большое значение, работайте с этой папкой в KC.
Используйте возможности KC для поиска: «анализ групп» — это очень мощный инструмент
Также вам пригодятся инструменты фильтрации, такие как «фраза содержит / не содержит»:
· цифры
· латинские буквы
· буквы кириллицы
· повторы слов
ШАГ 9. Первичная структура
Составление первичной структуры сайта в Key Collector. Это необходимо для упрощения дальнейшей фильтрации.
Создавая структуру сайта в KC, вы также упрощаете себе в дальнейшем парсинг и обработку запросов, т.к. они будут собираться примерно из одной и той же темы / группы запросов и отсеять мусор из одной такой пачки намного проще, чем пытаться убрать его из одной большой общей кучи.
Чем детальнее вы создадите структуру проекта в KC, тем проще вам будет работать
Данная структура нужна только для парсинга и фильтрации. То, что вы будете внедрять на сайт, от этой предварительной структуры будет очень сильно отличаться
ШАГ 10. Сортировка
Работаете со «структурой», сортируя запросы по папкам, параллельно избавляясь от мусора. Это самый длительный и занудный процесс, но его нужно пройти.
Параллельно вы будете находить гео, мусор, информационку, брендовые и товарные запросы, а ваши словари минус слов будут пополняться. Структура будет становиться более детальной и понятной. У проекта начнут вырисовываться черты, вы наконец-то поймете, сколько всего вы упустили.
Вы научитесь работать с «анализом групп» и фильтрами в KC, помимо структуры создадите необходимые лично вам подпапки в KC.
В целом уже начнёт складываться понимание как это всё работает, что удобно, а что — нет.
Заодно, поковырявшись в меню КС, вы найдете способы простого перемещения списков запросов по папкам. и в целом поднатореете в тематике.
Заодно увидите сколько новых вариантов написания уже известных вам запросов существует, а вы о них и не догадывались.
ШАГ 11. Отдохните
Итак вы разгребли вот это всё: метрика, вебмастер, сёрч консоль, keyso, метатеги конкурентов.
Это уже большое достижение. У вас уже также создана структура сайта в KC для парсинга запросов, которая позволит эффективно собирать вам нужные группы запросов.
К этому моменту вы должны уже ненавидеть KC и его мелкие буковки, правая рука — стонать от приближающегося тоннельного синдрома, а глаза — просить пощады.
Ну что, же, приступим к парсингу.
ШАГ 12. Парсинг запросов
Благодаря сформированной структуре, вы можете зайти в любую из папок с запросами, включить анализ групп и найти там все существительные.
Существительные — это основа маркеров для парсинга.
«Анализ групп» позволяет легко найти самые частотные слова и легко составить небольшой список маркерных фраз для последующего парсинга Wordstat.
Итак вы составили список маркеров для конкретной папки. Берете их и все запросы, которые уже есть в этой папке и собираете вордстат по всем этим фразам.
Далее повторяете перечисленные выше этапы с чисткой. Теперь чистка будет проходить уже намного проще, ведь вы работаете с небольшими участками сем ядра. И мусор в таких условиях чистить гораздо проще. Ведь то, что является мусором в одной категории, в другой – совсем не мусор. В общем, вы меня поймете, когда поработаете в KC хоть немного.
Чистку опять начинаете с частотности, потом гео, мусор, бренды, информационка. В итоге останется не так много рабочих запросов.
При парсинге сюда будут прилетать запросы из других групп, сортируем всё это дело по своим местам.
ШАГ 13. Глубокий парсинг
Если вы хотите максимально глубоко погрузиться в тему, вы берете высокочастотные слова и парсите их в таких вариантах
· «слово слово слово слово слово слово»
· «слово слово слово слово слово»
· «слово слово слово слово»
· «слово слово слово»
· «слово слово»
· «слово»
Таким образом вы максимально обходите ограничения Wordstat по выводу слов, ведь глубина просмотра статистики у него всего лишь 41 страница и в больших тематиках этого часто не хватает.
Для этого вы и парсите 6-5-4-3-2-1-словники по-отдельности.
ШАГ 14. Сбор подсказок
После того как пройдены все 13 предыдущих этапов, вы берете все запросы из любой папки и парсите по ним подсказки.
Далее чистите, фильтруете и сортируете.
Работа довольно муторная как и всё что связано с сем ядром, но зато вы можете быть уверены, что мало кто из конкурентов способен пройти через весь этот ад. Ну и фильтровать подсказки по конкретным группам – это детский сад по сравнению с тем, что вы уже проделали ранее.
ШАГ 15. Just Magic
Ура. вы собрали сем ядро. Радоваться, однако, рано. Собранная и внедрённая семантика — это две больших разницы. Приступим к следующему этапу.
На данном этапе основная работа с KC закончена и мы переносим собранное сем ядро / а точнее ту часть, с которой вы решаете работать, в Excel.
Работайте с отдельными группами, относительно большими кластерами, которые вы бы вынесли на первый / максимум на второй уровень в меню вашего сайта.
Не стоит сильно углубляться в подпапки но и не стоит сразу хвататься за весь сайт.
Берём группу запросов, с которой мы решили работать.
Регистрируемся в Just Magic и парсим там частотность [«!слово !слово»] — это самая точная словоформа и порядок слов, именно её стоит использовать в работе.
JM любит сортировать запросы по алфавиту. Учитывайте это и используйте формулы Vlookup / ВПР в Excel.
Убираем из нашего списка в Excel все запросы, у которых [«!слово !слово»] = 0.
Создаём новый пустой (!) проект в KС.
Загружаем в него оставшиеся запросы и супер точную частотность, полученную в Just Magic.
Используя инструмент KC «анализ неявных дублей», отмечаем в списке «неявные дубли».
Выгружаем полученный список в Excel, вставляем эти данные в нашу таблицу
Убираем из списка запросов в Excel неявные дубли.
Вы только что сократили вашу табличку примерно на 30-40%.
Для оставшихся запросов используем сервис «тематический классификатор» Just Magic.
Он позволяет еще более точно просеять оставшийся список и найти потенциально проблемные запросы, которые стоит убрать из ядра.
Проходимся по списку глазами/руками еще раз, отмечая лишнее.
ШАГ 16. PixelTools
Итак у нас остались запросы без дублей, с максимальной точной частотностью, просеянные через тематический классификатор.
Регистрируемся в Pixeltools и собираем там параметры «Гео/коммерциализация», а также делаем кластеризацию запросов в Just magic.
Это всё платные инструменты. Но если вы когда-нибудь сливали деньги в контексте, суммы за эти услуги не должны вас шокировать. Экономить тут не стоит. И стоит это совсем не космических денег, ведь вы делаете семантику для себя любимого.
Почему кластеризация в JM? Потому что там очень удобно за один проход делается кластеризация на нескольких уровнях. Это очень наглядно и выглядит в Excel позволяет быстро перегруппировать запросы в случае необходимости, не прибегая к повторной кластеризации.
Не нужно возиться с кучей настроек в Key Assort, не нужно по нескольку раз перекластеризовывать ядро, ища подходящий вариант, в Pixeltools тоже кластеризация не наглядная. JM на данный момент в табличном виде мне кажется самым удобным.
Почему идёт работа с 2 сервисами? Это упрощает аналитику и помогает сделать выбор, основываясь на показаниях в 2 разных источниках. В таблицах с такими данными работать намного проще.
В итоге у вас будут собраны вот эти параметры:
Pixel tools:
· геозависимость
· локализация
· комерциализация
· витальный ответ
Just Magic:
· «[!проверяемая !фраза]»
· тематика
· группировка по 4 уровням
· наличие главных страниц в выдаче
· комерциализация
· геозависимость
К сожалению, в JM нет возможности собрать гео и коммерцию отдельно, это работает только при кластеризации. Ну, работаем с тем, что есть.
ШАГ 17. Excel
Обработка таблиц с полученными данными в Excel. Сортируете всё это чудо, используете условное форматирование столбцов с необходимыми вам данными, чтобы проще их читать.
На этом этапе из списков ваших запросы отсеются потенциальные инфо запросы, которые вы посчитали коммерцией.
А также вы быстро пройдётесь по названиям групп, которые уже были выгружены из KC и сравните их с данными, полученными в JM.
Это первичная кластеризация с первой ручной корректировкой данных
ШАГ 18. Чистовая кластеризация
После отсева мусора в результате первичной кластеризации, берете оставшийся у вас список запросов из разных подгрупп одного большого раздела, сваливаете их в кучу и на этот раз делаете кластеризацию уже всего списка запросов в JM.
Она пройдёт более качественно, т.к. мусор вы уже убирали руками. Он всё равно будет, но уже в единичных случаях. В целом это и есть ваш финальный список запросов.
Далее вы проходитесь по нему вручную и решаете, нужно ли дробить какие-то кластеры на отдельные, переносить ли какие-то запросы из одной группы в другую.
Сортировка по группам в JM + ваша личная сортировка запросов по группам, которую вы сначала сделали в KC, а потом перепроверили в Excel, сделает обработку финального списка запросов простой и наглядной.
В итоге у вас получится таблица, которая называется «карта релевантности». В ней будут сгруппированы запросы для каждого из кластеров. Вам останется только проставить для них продвигаемые URL.
У многих групп запросов таких URL / страниц не будет, их придётся создавать на сайте.
Проанализировав получившиеся группы / кластеры, вы поймете для каких из них нужны отдельные страницы, а для каких хватит настроек в фильтрах категорий на сайте.
Далее, работая уже с конкретным ассортиментом на сайте, вы поймете, что некоторые из полученных в результате кластеризации групп просто нельзя использовать, потому что в каталоге нет таких товаров, соответственно, список рабочих кластеров станет еще меньше.
Всё. Создаете страницы и следите за апдейтами.
В итоге у вас есть:
1. Проект в KC который вы можете пополнять новыми запросами, ведь конкуренты не спят и стоит периодические заглядывать к ним, смотреть, что у них новенького. Парсить их и ваши маркеры.
2. Карта релевантности — вещь, которая есть далеко не у каждого.
3. Благодаря карте релевантности у вас есть чёткое понимание, какие страницы нужно создать, какого ассортимента не хватает на сайте, как его стоит там разместить, как изменить структуру каталога для удобства навигации, какие страницы наиболее популярны и значит должны быть наиболее заметны в меню и навигации. Всё это было бы невозможно без описанных выше шагов.
4. Если вы захотите написать инфо статью, у вас уже будут собраны инфо запросы в вашем проекте. Останется только немного их доработать.
Если сайт и ассортимент большой, эти все описанные шаги нужно будет проделать для каждого из больших разделов. Невозможно осилить всё сразу, но у вас уже есть очень мощная база, к работе над которой вы можете вернуться в любой момент, как только у вас появится вдохновение.
Пример предварительной группировки одной большой группы товаров в KC для мотивации. По цифрам в мусоре вы можете понять сколько всего пришлось отсеять.
Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как это сделать, читайте в инструкции по составлению семантического ядра от eLama.
Семантическое ядро для поисковых кампаний
1 этап. Сбор базовых ключевых слов
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.

Если у вас закончились идеи, то зайдите в yandex.wordstat.ru и посмотрите, что ищут при вводе, например, iPhone.

К собранному в Excel списку добавим слово «Цена».
Далее, найденные слова нужно скомпоновать. Это можно сделать через инструмент eLama «Комбинатор ключевых фраз»:

Полученные фразы мы будем использовать на следующем этапе.
Бесплатные кампании в Директе для старта
Для тех, кто раньше не запускал рекламу в Директе через eLama
Получить кампании
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее:

Итак, получился список и одна свободная колонка, которая нужна для списка минус-слов.

Этап 3. Чистка семантического ядра
Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их. Как работать с инструментом, читайте в другом нашем материале.
Можно продолжить работу в таблице, но так будет посложнее.

Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.

Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».

По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
В списке могут появиться фразы с минимальным различием, например, «iphone 8 в москве» и «iphone 8 купить спб». Для того, чтобы система показывала объявления, релевантные запросу, нужно провести кросс-минусацию, например, через eLama.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.

Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Для экономии времени используйте «Комбинатор ключевых фраз», который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:

Если нужны типы соответствия/операторы, которых нет в «Комбинаторе ключевых фраз», то используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Полный список операторов Яндекс.Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Подбор ключевых слов для КМС и РСЯ
Ключевые фразы для РСЯ и КМС не нужно уточнять. Достаточно создать семантическое ядро с широкими ключевыми фразами, которые взаимосвязаны между собой. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, то воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но в то же время сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.
Термин «семантическое ядро» входит в число часто употребляемых специалистами по продвижению сайтов. В этом нет ничего удивительного, так как он фактически обозначает фундамент любого успешного интернет-ресурса и становится ответом на вопрос, зачем нужна работа СЕО-оптимизатора.
С теоретической точки зрения СЯ представляет собой набор ключевых запросов, которые содержатся в контенте сайта и обеспечивают его высокое положение в выдаче поисковых систем. Практическая сторона вопроса состоит в обеспечении необходимого объема трафика и, что важно для коммерческих ресурсов, его трансформации в конкретные заказы.
Оба параметра – количество посетителей и их конверсия в продажи – заслуженно считаются главными критериями эффективности интернет-ресурса. Поэтому добиться успешной работы сайта без правильно составленной семантики в виде списка ключей попросту невозможно.
Содержание
- Требования к правильному СЯ
- Основные инструменты для подбора семантики
- Этапы формирования семантики
- Шаг №1. Подготовка
- Шаг №2. Составление общего списка ключевых запросов
- Шаг №3. Оптимизация или настройка базы
- Шаг №4. Кластеризация (группировка) запросов
- Что дальше?
- Анализ существующего семантического ядра
- Несколько полезных лайфхаков
- Как проверить КПД собранного ядра?
- Примеры составления семантического ядра
- Как организовать работу по оптимизации и продвижению интернет-ресурса?
- Подход №1. SEO своими силами
- Подход №2. Сотрудничество со специалистами
- Плюсы обращения к нам
- Как оформить заказ?
Требования к правильному СЯ
Определения основных терминов и базовые правила формирования семантики детально описаны в специальном разделе нашего сайта.
Здесь же необходимо перечислить наиболее значимые требования к семантическому ядру, выполнение которых становится обязательным условием успешной раскрутки. К ним относятся:
- Полнота полученного на выходе списка поисковых фраз. Достигается за счет правильного баланса групп запросов разной частотности и вниманию ко всем возможным источникам трафика. Это необходимо, чтобы создать полноценную семантику нового сайта.
- Отсутствие минус-слов. Термин означает ключевые фразы или отдельные слова, присутствие которых среди ключей искажает восприятие запроса целевой аудиторией. В качестве пример можно указать такой: актуальная поисковая подсказка «доставка еды» делается бесполезной с коммерческой точки зрения при добавлении ключевого слова «бесплатно».
- Учет информационной (новостной) и коммерческой составляющей сайта. Первый вид онлайн-ресурсов ориентирован на трафик, второй – на финансовые показатели в виде продаж. Серьезная разница в целеполагании приводит к необходимости задействования разных инструментов, в том числе – ключей и поисковых фраз.
- Акцент на частотность запросов. Базовый параметр, влияющий на оптимальную семантику ключей. Дополняется помесячной разбивкой для товаров или услуг сезонного спроса.
- Структурирование или кластеризация запросов. Выражается разными способами, в том числе – построением структуры в виде дерева. Позволяет отобрать основные поисковые фразы и повысить общую эффективность СЯ.
Последний пункт списка особенно актуален для многостраничных интернет-ресурсов. Их итоговый КПД в значительной степени определяется грамотным построением структуры, которая базируется на предварительной кластеризации поисковых подсказок, часто – многоступенчатой.
Основные инструменты для подбора семантики
Перед тем, как приступить к непосредственному описанию процесса сбора семантического ядра, необходимо выделить еще один крайне важный момент. Работа SEO-оптимизатора любого уровня – как новичка, так и профессионала – в обязательном порядке предусматривает использование разнообразных вспомогательных инструментов.
Выполнять многочисленные и часто рутинные операции сбора/разбора ключей вручную попросту нерационально, так как это требует огромных трудозатрат и чревато частыми ошибками. Важно не переходить к другой крайности, полностью доверяя работу онлайн-сервисам и специализированному софту. Такой подход также сложно назвать рациональным, так как ни одна машина не способна заменить человека. Тем более в таком сложном деле, как сбор семантического ядра и отбор оптимальных для продвижения ключей.
Самые популярные и востребованные инструменты в области СЕО-продвижения указываются в описании отдельных этапов составления СЯ. Здесь же необходимо отметить, что подобные продукты делятся на несколько категорий:
- онлайн-сервисы, представляющие собой набор инструментов для сбора, анализа и оптимизации информационных запросов, работа с которыми ведется непосредственно в интернете;
- специализированное ПО с аналогичным функционалом поиска ключей, эксплуатация которого требует предварительно скачать и установить продукт на компьютере;
- вспомогательные инструменты, обладающие узкоспециализированным набором возможностей, самыми популярными из которых выступают парсеры и различные базы данных.
Приведенная классификация несколько условна. Дело в том, что многие сервисы и программные продукты имеют несколько версий, успешно сочетающих особенности всех трех перечисленных выше категорий инструментов по составлению семантического ядра. Больше информации о подобных сервисах можно найти в другой статье нашего сайта.
Этапы формирования семантики
Пошаговая инструкция о том, как собирать, создавать и оптимизировать семантику ресурса, представляет собой набор последовательно реализуемых мероприятий. В зависимости от квалификации привлеченных к работе специалистов и особенностей интернет-ресурса, перечень действий может варьироваться. Но общая схема операций в целом остается неизменной и включает несколько этапов или шагов. При желании можно найти в Ютуб немало видео с пошаговыми инструкциями. Для большей наглядности приведем свою, позволяющую подготовить, прописать и править семантику сайта, составленную на основе богатого практического опыта.
Шаг №1. Подготовка
Этап не связан с оптимизацией, так как предусматривает изучение и анализ продвигаемого вида деятельности. Чтобы получить исчерпывающее представление о нем, необходимо:
- составить полный перечень продвигаемых товаров и услуг;
- сгруппировать их по нескольким ключевым признакам, например, спросу, новизне и прибыльности;
- понять схему продвижения и каналы сбыта – от приема заявки на поставку до вручения товара клиенту или оказания услуги заказчику;
- узнать влияние на спрос географических и сезонных факторов;
- подобрать и построить исчерпывающий список товаров и услуги, не интересных владельцам интернет-ресурса (важная часть работы, позволяющая определиться с минус-словами);
- сбор СЯ сайтов конкурентов (позволяет подобрать схожие ключи).
Только последний пункт списка может называться полноценной работой СЕО-оптимизатора. Остальные намного ближе к деятельности маркетологов. Последние нередко привлекаются на подготовительном этапе, что позволяет повысить эффективность последующих мероприятий по сбору ядра семантики. Не менее важной грамотная подготовка оказывается для завершающей стадии работ по оптимизации, которая состоит в заполнении интернет-ресурса контентом на основе полученных ключей.
Шаг №2. Составление общего списка ключевых запросов
Сначала имеет смысл выбрать главные запросы. Затем – найти связанные с ним посредством какого-то вспомогательного инструмента. Обычно с подобной целью используется Яндекс Wordstat.
Достаточно вбить в поисковую строку основной запрос, например, «микроволновая печь», и программа в течение 1-2 секунд выдаст связанные с ним поисковые фразы, наиболее часто интересующие пользователей. Отдельного упоминания заслуживает второй список ключей, в котором содержатся запросы, схожие с исходным. Его использование позволяет расширить перечень запросов за счет синонимов, то есть сделать их более разнообразными. Расширять СЯ подобным образом всегда полезно и несложно – при грамотном использовании Вордстат.

Аналогичные действия выполняются со всеми исходными запросами. При желании более детального изучения частотности ключевых слов, можно воспользоваться другими критериями поиска. Например, с разбивкой на регионы или с привязкой ко временному критерию. Результатом становится получение обширного массива исходной информации, необходимой для дальнейшего анализа на последующих стадиях сбора семантического ядра.

Отобранные таким образом фразы необходимо вставить в таблицу Excel для дальнейшей сортировки и обработки. Другой вариант ответа на вопрос, куда их можно занести – более специализированные инструменты, например, Комбинатор ключевых фраз от Elama.

Дальнейшая сортировка происходит с применением функционала электронных таблиц. Списки могут добавляться друг к другу, сортироваться – как по алфавиту, так и по частоте запросов, корректироваться любым другим способом, которые прекрасно известны всем, работавшим с Excel. При использовании специализированных инструментов сначала потребуется изучить их особенности.
Аналогичные описанным выше действия по формированию базового списка ключевых слов могут быть выполнены самыми разными программными продуктами и онлайн-сервисами. В числе наиболее популярных:
- подсказки поисковых систем Google и Яндекс;
- готовые базы поисковых запросов (самая популярная – Букварикс, обеспечивающая быстрый поиск ключей);
- программы-парсеры, обрабатывающие данные других сервисов (две наиболее известных – Магадан и Word Keeper)
- универсальные и многофункциональные онлайн-сервисы, частично указанные ниже и позволяющие собрать СЯ как один из начальных этапов работы с семантикой сайта (например, https://seo.msk.ru/ от pied piper или https://texterra.ru/ от одноименной компании-разработчика).
Результатом становится визуализация начального варианта семантического ядра. Чтобы сделать его по-настоящему эффективным и внедрить на сайт, следует заняться масштабной чисткой собранных запросов. Необходимость «раздеть» СЯ и освободить от всего ненужного связана с логичным желанием повысить КПД семантики, сборка которой была выполнена на предыдущих этапах.
Шаг №3. Оптимизация или настройка базы
Каждый профессиональный СЕО-оптимизатор использует собственные алгоритмы чистки исходного варианта семантического ядра. Дело в том, что единственного верного решения задачи сделать сайт эффективным с точки зрения продвижения попросту не существует. Успеха добиваются разными путями. Некоторые из самых часто используемых на практике способов оптимизации заслуживают отдельного упоминания:
- Удаление особенно низкочастотных запросов. Граница отсечения определяется с учетом специфики ресурса и обычно равняется 50-70 показам. Остальные ключи нужно вписывать или вставлять в электронную таблицу.
- Избавление от фраз, которые не имеют отношения к конкретному интернет-ресурсу. Например, для магазина или гостиницы в Москве таковыми являются запросы, касающиеся других регионов.
- Исключение из списка лишних запросов с прогнозируемо низкой релевантностью. Типичным примером становится ключ со словом «скачать», не интересный потенциальным клиентам онлайн-магазина электроники. Другой наглядный пример, запрос «своими руками», который не должен вставляться в СЯ для компании, торгующей готовым товаром.
- Уборка дублей. Этим термином обозначаются запросы, полностью идентичные по составу ключевых слов и отличающиеся друг от друга только их порядком. В подавляющем большинстве случаев такие ключевые фразы воспринимаются поисковыми системами как полностью идентичные, а потому намного проще и правильнее оставить только один из дублей, порой многочисленных.
- Удаление ключей, так или иначе, ссылающихся на конкурентов. Обычно речь идет о товарах, не входящих в каталог интернет-магазина, производимых другими брендами или иных моделей.
Перечисленные операции выполняются вручную. Некоторые сервисы способны к их частичной автоматизации, например, в части удаления низкочастотных запросов. Но практика наглядно показывает, что поручить такую «тонкую» работу компьютеру в полном объеме все-таки не стоит. Напротив, грамотная балансировка автоматических и ручных процессов обеспечивает максимальную эффективность на выходе.
Самыми популярными онлайн-сервисами и программными продуктами, имеющими в составе обширный набор инструментов для оптимизации семантического ядра, выступают:
- уже упомянутый выше Яндекс Wordstat с дополнительными расширениями;
- Google Keyword Planner Tool;
- PromoPult;
- Serpstat;
- Keyword Tool;
- Keys.so;
- Key Collector;
- Словоеб и многие другие.
В приведенном списке присутствуют как софт, так и онлайн-сервисы. Большая их часть способна выполнять как первичный сбор семантического ядра, так и последующую его оптимизацию. Результатом последней становится резкое сокращение количества запросов, входящих в семантическое ядро. Но на этом процесс сбора семантики не заканчивается.
Шаг №4. Кластеризация (группировка) запросов
Завершающая стадия работы по формированию семантического ядра интернет-ресурса. Заключается в определении итогового списка запросов с учетом специфики сайта, под которой понимаются два основных параметра.
Первый – это общее количество посадочных страниц, входящих в структуру ресурса. Оно непосредственно влияет на финальное число запросов, так как для одной страницы обычно не требуется больше 5-6 ключей. Превышение этого лимита допускается, если разрабатывается объемный лендинг большого размера. Другими словами, для интернет-ресурса в 10 страниц целесообразно оставить примерно 50-60 запросов. Добавить дополнительные можно для объемных страниц, но это должно быть аргументированным решением.
Второй – направленность интернет-ресурса. В данном случае речь идет об информационной или коммерческой составляющей сайта. Некоторые различия между ними описаны выше и на других страницах нашего ресурса. (снова ссылка на страницу, где это описано).
Чтобы наглядно продемонстрировать эту разницу, достаточно привести несколько примеров ключевых запросов, актуальных именно для коммерческих сайтов. Это слова «купить», «цена», «выгодно» и другие им подобные в сочетании с основными тематическими ключами ресурса.
Ситуация с информационными сайтами несколько сложнее. В этом случае при формировании семантического ядра предпочтение отдается именно тематике и основной направленности интернет-ресурса.
Что дальше?
Составление семантического ядра из поисковых запросов– важное, но далеко не единственное направление работы по продвижению сайта. Можно выделить, как минимум, два не менее важных мероприятия.
Первое – выполняется параллельно с определением оптимальной семантики и состоит в формировании структуры сайта. Подготовка к этому осуществляется вместе с аналогичным этапом сбора СЯ и проходит с привлечением маркетологов. Только в таком случае удается добиться максимального эффекта, особенно актуального для коммерческих сайтов.
Второе – наполнение интернет-ресурса контентом на основании сформированного семантического ядра, включая основные мета теги html-языка (title, H1 и т.д.), тексты и другие составляющие. Чтобы их прописать, обычно привлекаются копирайтеры, обладающие достаточным опытом и квалификацией в данной теме. Допускается использование сотрудников самого онлайн-магазина, являющихся профессионалами в своем деле. Важно, что прописываться контент сайта должен в едином стиле и ключе.
Анализ существующего семантического ядра
Не стоит забывать о том, что процесс оптимизации и продвижения сайта должен носить систематический характер и быть перманентным. То есть постоянным и непрекращающимся по времени. Это вполне логично, так как происходит регулярное изменение всех определяющих факторов: начиная с интересов и запросов потенциальных посетителей ресурса или покупателей и заканчивая алгоритмами работы поисковых систем.
Анализ собранного ядра происходит по нескольким ключевым критериям, к числу которых относятся:
- Динамика частотности запросов. Предпочтения пользователей постоянно меняются. В результате требуется регулярная проверка актуальности семантики ядра.
- Устаревание ключевых фраз. Любой бизнес претерпевает изменения: появляются новые технологии взамен старым, происходит обновление модельной линейки, меняются способы продаж и т.д. Все это напрямую влияет на список ключей.
- Появление новых поисковых запросов. Фактически становится следствием процессов, указанных в двух первых пунктах списка, и комбинирует эффект от них.
- Соотношение запросов разной частотности. Еще один параметр, подверженный постоянному изменению. Рассматривается в комплексе с тремя предыдущими.
- Пробелы в семантическом ядре. Далеко не всегда изначально собранная семантика оказывается максимально эффективной. Нередко какие-то очень актуальные для пользователей запросы не входят в СЯ, а другие, не дающие конверсию, включены в состав ядра.
На основании перечисленных критериев проверяется баланс структуры сайта и состава семантического ядра. Однажды разработанная структура и собранное семантическое ядро – это не догма, а инструменты продвижения интернет-ресурса. Каждый из них должен регулярно корректироваться, причем во взаимосвязи друг с другом. Например, появление нового товара с высокой долей вероятности означает как необходимость актуализации списка запросов, так и создание новой страницы сайта.
Несколько полезных лайфхаков
Как было отмечено выше, не существует единственно правильного способа собрать эффективно работающее семантическое ядро. Каждый специалист в этой области руководствуется собственными принципами работы. Некоторые самые общие из них имеет смысл привести отдельно. Они состоят в следующем:
- Максимальное использование коммерческих фраз, примеры которых приведены ранее. Особенно актуальны такие запросы для сайтов, нацеленных на продажу товаров или услуг.
- Постоянный поиск оптимального соотношения запросов разной частотности – высокочастотных с одной стороны, средне- и низкочастотных – с другой. Дело в том, что по первым конкуренция между сайтами намного выше, что затрудняет продвижение в СЕОлидеры топа выдачи. Напротив, грамотный подбор запросов второго и третьего типа заметно увеличивает КПД ресурса.
- Ограничение количества ключей на одной странице. Если в СЯ входит много «хороших» запросов, схожих по семантике, правильнее увеличить число страниц и распределить их между ними, сделав более разветвленную структуру сайта.
- Активное включение в контент разноплановых запросов, существенно увеличивающих конверсию. По отношению к приведенному выше примеру с микроволновой печью таковыми становится ключи «СВЧ-печь» и «микроволновка».
- Написание иностранных брендов и тематических двуязычных запросов и на русском, и на английском языке (использование других языков заметно ограничено из-за специфики русскоязычного интернета, хотя и возможно в отдельных случаях). Такой подход к визуальному отображению ключей обеспечивает максимальную итоговую эффективность размещенных на странице релевантных поисковых запросов. Все бренды должны писаться на максимально возможном количестве языков.
- Внимательное изучение возможностей онлайн-сервисов и программ, используемых SEO-оптимизатором. Дело в том, что некоторые из подобных инструментов обладают очень широким функционалом, подробно описанным разработчиками и способным не только упростить работу специалиста, но и заметно повысить ее эффективность. Типичные примеры – Serpstat или PromoPult, которые содержат внушительные по объемам информационные базы.
Завершающая рекомендация раздела выглядит предельно кратко и понятно. Формирование семантического ядра и выдача списка запросов копирайтеру – важная, но не главная задача. SEO-оптимизация решает вопросы маркетинга, а они состоят в повышении трафика, увеличении объема продаж или сокращении стоимости рекламной кампании без снижения итоговых результатов. Именно эти цели и должен решать специалист посредством сбора ядра и формирования списка релевантных ключей.
Как проверить КПД собранного ядра?
Проверить эффективность работы сайта достаточно просто. Один из доступных инструментов – онлайн-сервис SEO-аудитор от Roistat. Программа позволяет выполнить разносторонний анализ интернет-ресурса с применением множества инструментов по выбору пользователя. В их числе:
- бизнес-аналитика – сквозная (включает расчет различных показателей на основании статистики запросов– CPO, LTV, ROI и т.д.) и мультиканальная, когортный/сегментный анализ и составление сводного отчета);
- анализ трафика (позволяет применять разные методы управления ставками, аудит контекстной рекламы, интегрирование расходов и т.д.);
- аудит лидов посредством трекинга заявок из разных источников – как онлайн, так и офлайн;
- оценка лояльности посетителей сайта и многое другое.
Важным достоинством сервиса выступает возможность интеграции практически со всеми программами учета и рекламными платформами. Единственным существенным недостатком становится высокая стоимость подписки (от 7 300 руб. в мес.), которая частично компенсируется бесплатным пробным режимом на 2 недели.
Примеры составления семантического ядра
Теме образцов готовых СЯ отводится специальный раздел нашего сайта. (Ссылка на одну из написанных ранее статей, где приводятся примеры). Здесь же необходимо отметить два важных момента. Первый касается сложности прямого переноса сформированного ранее семантического ядра на конкретный информационный ресурс или интернет-магазин. Дело в том, что двумя подразделами выше приведена информация о необходимости регулярного анализа семантики сайта на предмет происходящих вокруг изменений. Именно поэтому велика вероятность, что эффективное два-три года назад ядро окажется малорезультативным в сегодняшних условиях.
Второй немаловажный нюанс заключается в существенной специфике любого вида деятельности, что в равной степени касается как информационных, так и коммерческих сайтов. Не существует двух одинаковых интернет-магазинов микроволновых печей – ни с точки зрения ассортименте, ни в вопросах продвижения товара, ни в отношении ценовой политики. Стоит ли удивляться, что семантическое ядро, составленное для одного из них, вряд ли подойдет для другого, как и даже самые тщательно отобранные запросы.
Как организовать работу по оптимизации и продвижению интернет-ресурса?
Существует всего два ответа на вынесенный в подзаголовок вопрос. Первый предусматривает решение задачи собственными силами. Второй предполагает обращение к специалистам. Рассмотрим плюсы и минусы каждого из подходов несколько подробнее.
Подход №1. SEO своими силами
Собрать семантическое ядро со списком поисковых запросов своими руками – вполне выполнимая задача, решению которой можно научиться в сравнительно сжатые сроки. Главным достоинством такого способа действий становится экономия денежных средств. Очевидно, что специалисту со стороны придется платить, а если все делать самому или с привлечением штатного персонала компании, расходы существенно сократятся. По крайней мере, так кажется на первый взгляд.
Важно понимать, что подобная экономия нередко оказывается фикцией. Во-первых, нет никаких гарантий, что задача будет решена успешно. Несмотря на наличие множества разнообразных инструментов сбора семантики сайта и поисковых запросов, грамотное использование онлайн-сервисов и программных продуктов требует квалификации и опыта, а потому часто недоступно начинающему специалисту.
Во-вторых, отвлечение собственных сил и времени персонала на выполнение непрофильной работы также сопровождается расходами – хотя бы на зарплату. Зачастую намного правильнее и, в конечном счете, заметно выгоднее, чтобы каждый сотрудник занимался своим делом, то есть тем, что умеет и профессионально выполняет.
Подход №2. Сотрудничество со специалистами
Учитывая сказанное выше, становится понятным, из-за чего наибольшей популярностью пользуется второй подход, предусматривающий помощь профессионалов. В пользу такого варианта действий можно привести множество аргументов, главными из которых становятся такие:
- Гарантия получения нужного результата.
- Сжатые сроки выполнения работы.
- Индивидуальный подход к заказчику.
Чтобы три приведенных выше пункта списка стали из рекламных лозунгов реальностью, достаточно выполнить всего одно условие. Оно состоит в обращении к настоящим профессионалам, доказавшим способность решать самые сложные задачи на практике.
Плюсы обращения к нам
Мы представляем собой команду единомышленников, давно и успешно работающую на высококонкурентном российском рынке SEO-продвижения. Заработанная за это время безупречная деловая репутация подкрепляется отзывами клиентов, уже воспользовавшихся качественными услугами компании. За плечами наших специалистов – множество успешно реализованных проектов разной направленности – от обычных интернет-магазинов бытовой техники до специализированных сайтов – кулинарных, мебельных, в сфере туризма и т.д.
Ключевыми преимуществами предлагаемого сотрудничества, помимо перечисленных в предыдущем разделе, выступают:
- большой опыт формирования семантических ядер для сайтов разной направленности, вида деятельности и объема;
- предоставление клиенту возможности самостоятельно выбрать базовые параметры взаимодействия – от перечня выполняемых работ до способа оплаты;
- предоставление сопутствующих услуг, вплоть до разработки интернет-ресурса под ключ и заключения долгосрочного договора на его сопровождение;
- прозрачная ценовая политика, которая дополняется серьезными скидками и преференциями для постоянных и крупных заказчиков;
- отработанная схема взаимодействия с клиентом, удобная и выгодная, а также многократно доказавшая эффективность на практике.
Как оформить заказ?
Все, что нужно для оформления заказа на разработку семантического ядра и получение других услуг нашей компании – заполнение онлайн-заявки на сайте. Альтернативный вариант действий – выход на связь удобным способом – по телефону, email или в чате.
Наш сотрудник оперативно свяжется с Вами, ответит на возникшие вопросы, уточнит задачу и обсудит условия сотрудничества. На основе полученных данных в сжатые сроки разрабатывается и направляется в Ваш адрес персональное коммерческое предложение. Готовы предоставить дополнительно любую интересующую информацию.

Советы
Как составить семантическое ядро сайта
Руководство с комментариями опытного сеошника
Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядро
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
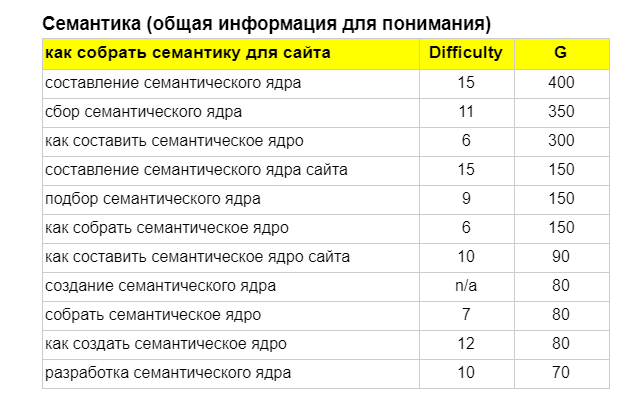
Вот так выглядит семантика для статьи, которую вы читаете. Скорее всего, если вы нашли эту статью в поиске, вы писали что-то подобное. Difficulty означает сложность запроса — чем выше, тем труднее попасть в топ выдачи. G означает частность — сколько таких запросов ищут в месяц
Для чего собирать семантическое ядро
Вот основные причины:
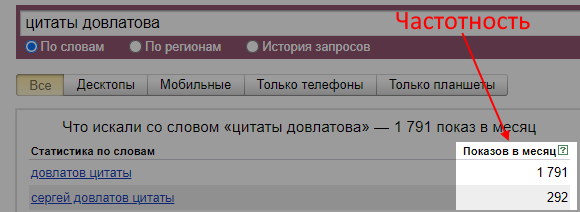
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
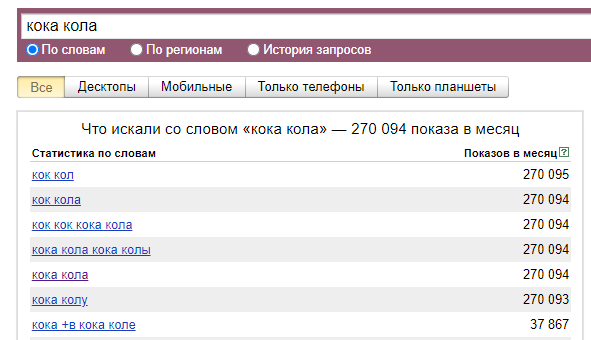
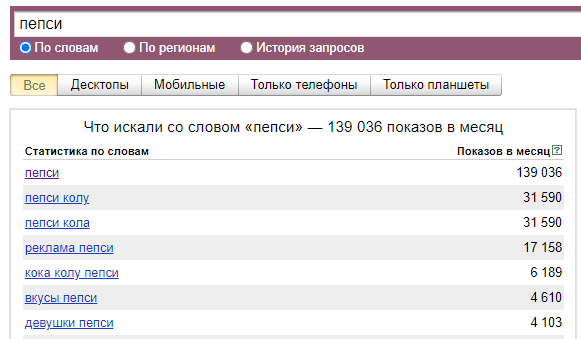
Кока кола популярнее Пепси. По данным Wordstat, запросов, связанных с ней, больше чем в два раза
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
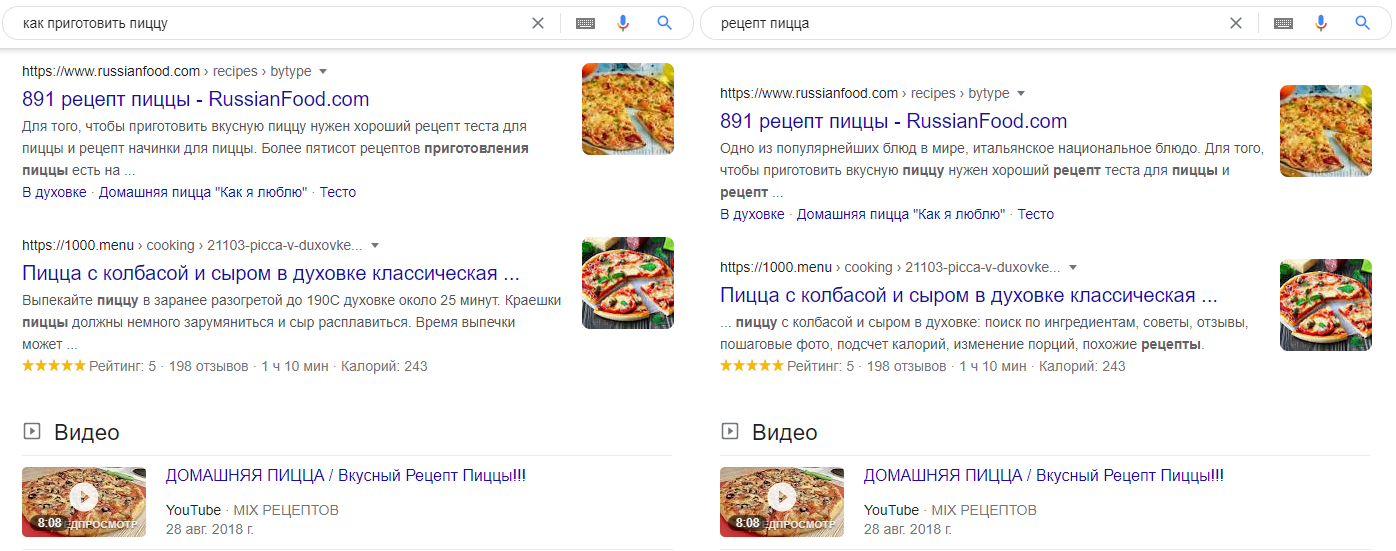
«Как приготовить пиццу» и «Рецепт пицца» — один кластер. Google выдает по этим запросам пересекающие результаты. Первые позиции совпадают полностью
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
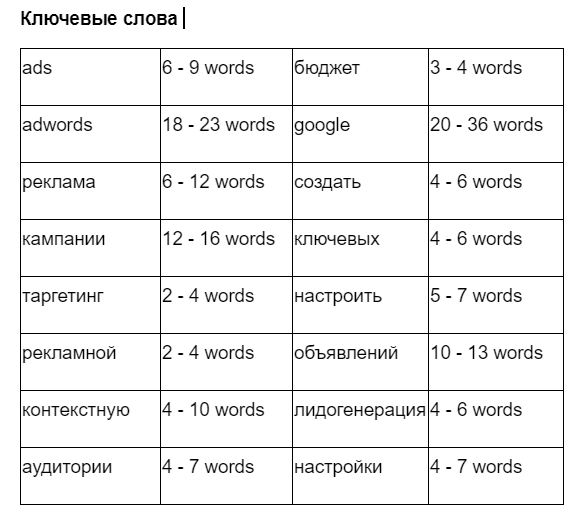
Ключи для статьи про контекстную рекламу. Справа от слова написано его рекомендуемое вхождение — сколько раз за статью оно должно быть использовано
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Когда семантическое ядро собирать самому, а когда лучше звать сеошника
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Я пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядра
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Чем выше значение Difficulty, тем сложнее попасть в топ выдачи по этому запросу
Интент
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
В мою семантику попал запрос «пицца с доставкой фильм». Не знал, что такой есть и поэтому было ощущение что запрос можно оставить. Но потом загуглил и вот — под пиццерию это не подходит
Геозависимость
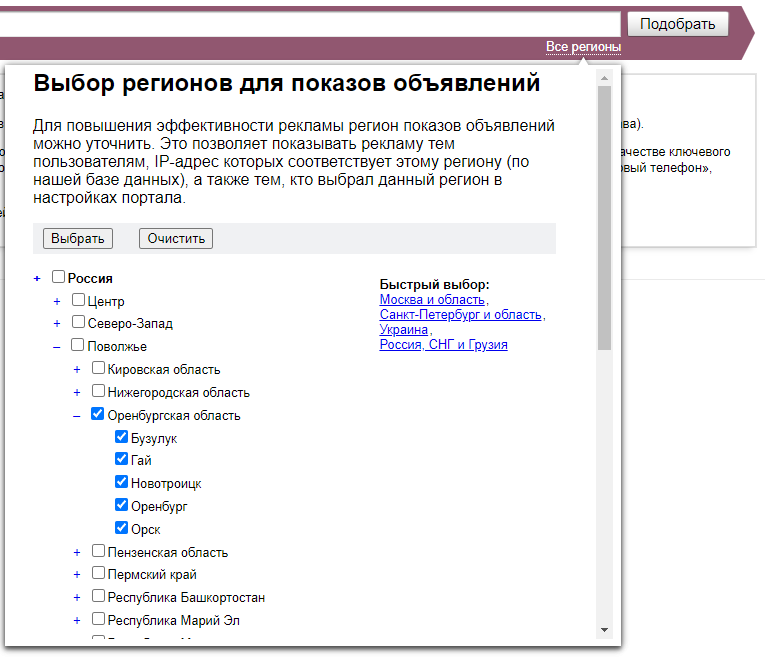
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
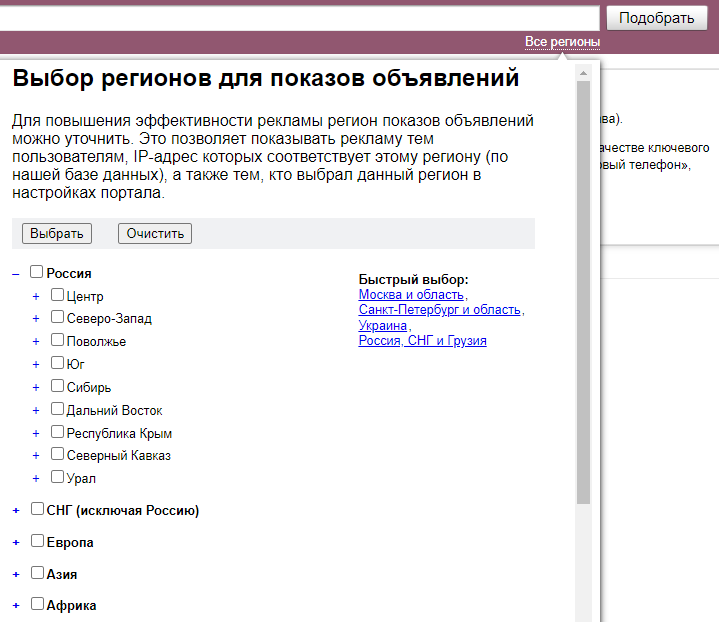
Можно выбрать как всю Россию, так и конкретный город или регион
Пошаговая инструкция как составить семантическое ядро
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
- Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:
Сбор базовых ключевых слов
Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
Выбор региона в Яндекс Вордстат
Поглядите, какая мне смешная капча попалась 🙂
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
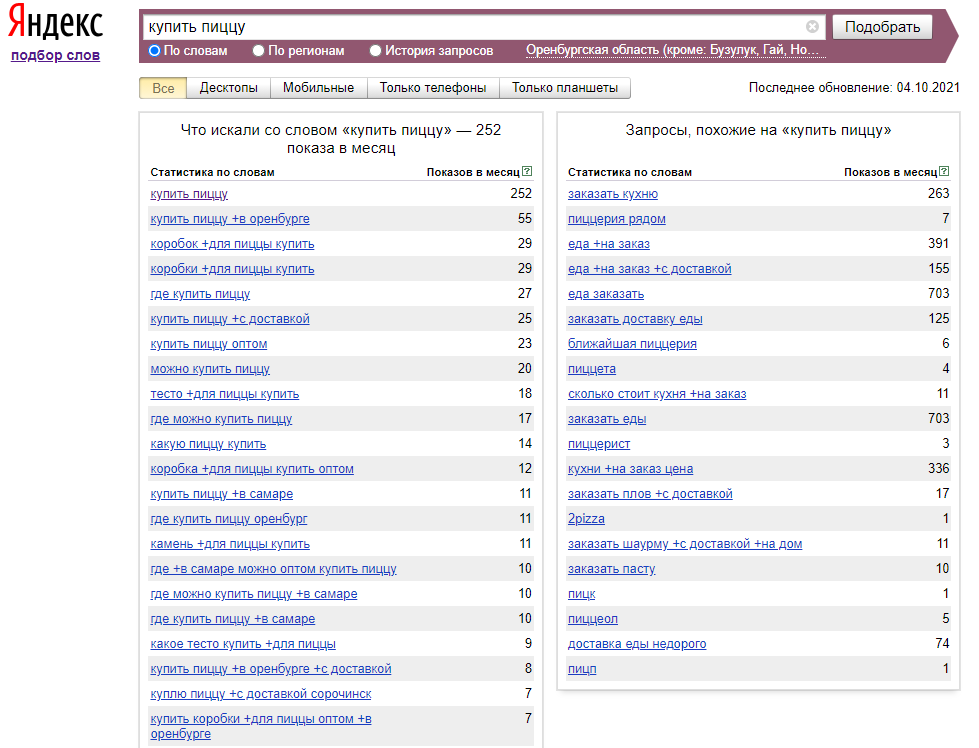
Статистика Яндекс Вордстат по запросу «купить пиццу» для Оренбурга
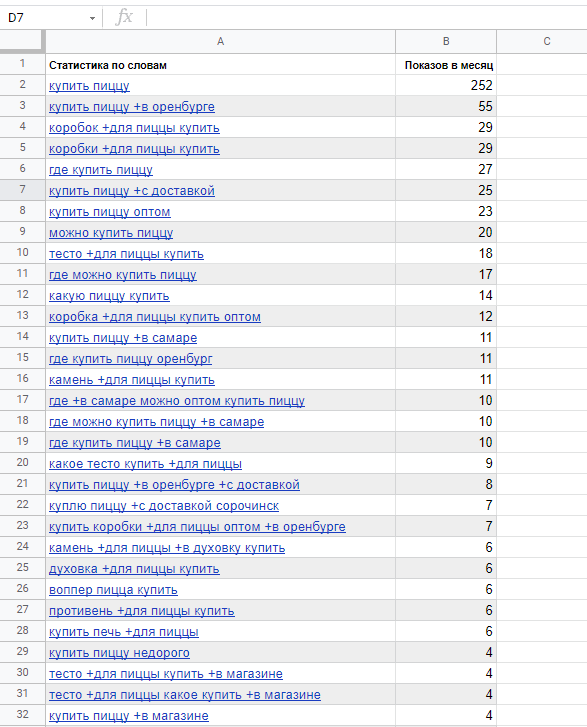
А вот так это выглядит в Google Таблицах
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
Я вбил общий запрос «купить пицца» и мне приглянулись фразы «пиццу купить рядом» и «воппер пицца купить» — последнюю часто ищут, видимо, какой-то тренд. В этот раз меня интуиция подвела: в Оренбурге «воппер пиццу» ищут 6 раз в месяц, что очень мало, а «купить пиццу рядом» не ищут вообще. Но тем не менее используйте Букварикс — это поможет вам отыскать другие перспективные запросы
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
Анализ конкурентов
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
На одном сайте пиццерии я увидел раздел с акциями и стал копать в этом направлении. Попробовал запросы «пицца скидки» и «промокоды пицца». По последнему запросу неплохой результат — 169 запросов для Оренбурга, точно нужно взять. А по скидкам частотность меньше, но тоже можно использовать
Шлифуем семантику — сортируем, удаляем дубликаты и лишние символы
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Выделяем таблицу и нажимаем вкладку «Данные», а в ней «Удалить повторы». Оставляем только столбец A — в котором содержатся сами запросы
Удалить плюсы. Они будут мешать на этапе кластеризации.
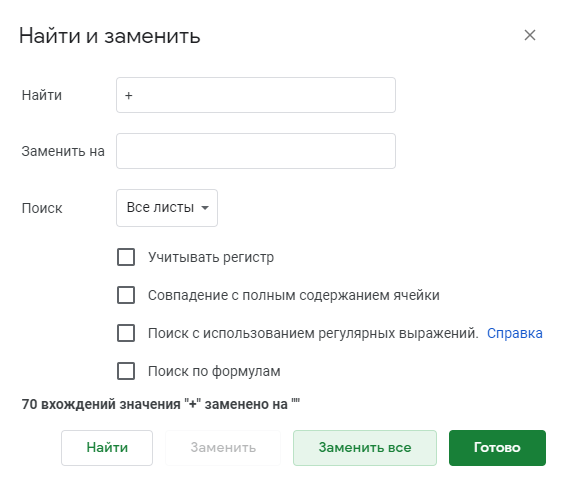
Нажмите Ctrl + F или Command + F на MacBook. В выпадающем меню выберите три точки. Либо в разделе «Правки» кликните «Найти и заменить». В поле «Найти» напишите «+», остальное оставьте без изменений. Нажмите на кнопку «Заменить все». Google удалит все плюсы из таблицы
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Сортировка запросов по убыванию частотности. Выделяем таблицу, нажимаем «Данные» и кликаем по «Сортировать диапазон по столбцу B, Я → А». Если у вас частность не в столбце B, то сортируйте по другому столбцу
Чистка нерелевантных запросов
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
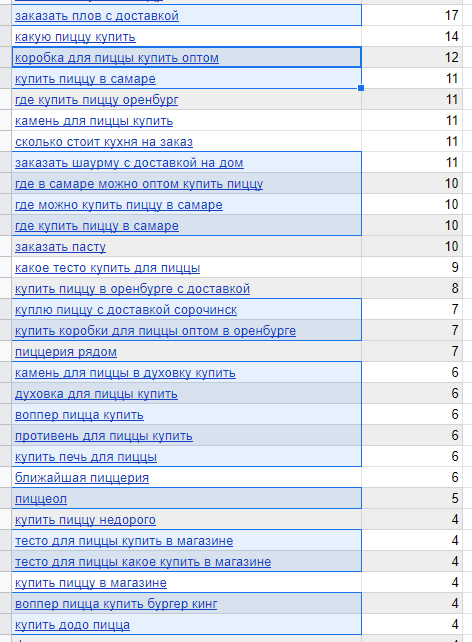
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:



Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
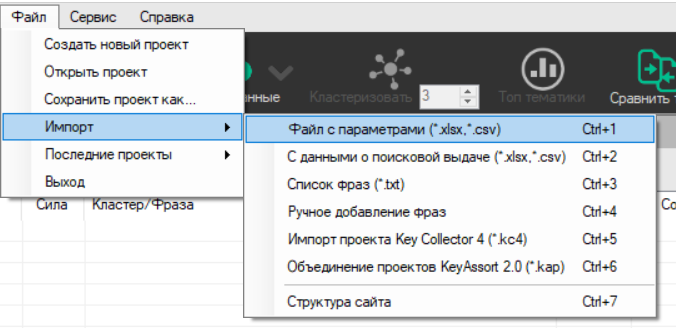
В меню нажимаем «Файл» — «Импорт» — «Файл с параметрами»
Следующие окна оставляем без изменений:
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
Так как мы работали с Яндекс Вордстат, то собираем по Яндексу
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
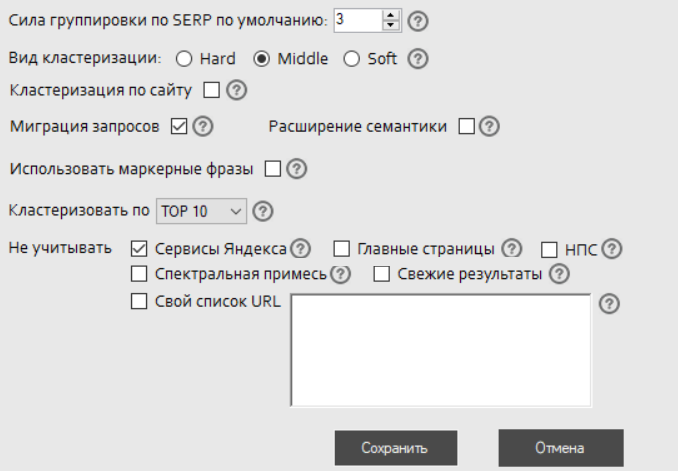
Настройка кластеризации
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:

В последнем кластере ошибка — это не статья в блоге, а страницы пиццы
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальше
Теперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Заключение
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
- Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.