Метод наименьших квадратов: формулы, код и применение
Время на прочтение
12 мин
Количество просмотров 31K
Традиционно в машинном обучении, при анализе данных, перед разработчиком ставится проблема построения объясняющей эти данные модели, которая должна сделать жизнь проще и понятней тому, кто этой моделью начинает пользоваться. Обычно это модель некоторого объекта/процесса, данные о котором собираются при регистрации ряда его параметров. Полученные данные, после выполнения различных подготовительных процедур, представляются в виде таблицы с числовыми данными (где строка – объект, а столбец – параметр), которые необходимо обработать, подставив их в те или иные формулы и посчитать по ним, используя какой-нибудь язык программирования.
Одним из часто встречающихся на практике методе, используемый в самых различных его модификациях, является метод наименьших квадратов (МНК). Этот метод был опубликован в современном виде более двухсот лет назад, именно поэтому особенное удивление вызывает то, что этот хрестоматийным метод не описан максимально подробно на самых популярных ресурсах, просвещённых анализу данных. Поэтому разработчик в попытках самостоятельно разобраться с МНК обращается к чтению самых различных бумажных и электронных изданий. После чего желание разобраться быстро улетучивается по причине того, что авторы этих ресурсов особо не «заморачиваются» над объяснениями выполняемых ими преобразований и допущений.
Обычно объяснение метода представляется в виде:
-
перегруженного математическими абстракциями «классического описания»;
-
«готовой процедурки», в которой выполняется программная реализация неких конечных выражений, полученных при каких-то начальных условиях.

Первый вид объяснения вызывает полное отторжение у новичка в виду отсутствия должного уровня математической подготовки и представляется непонятным нагромождением формул. А второй вид представляется неким черным ящиком, из которого чудесным образом извлекаются правильные значения. Из чего делается вывод, что все эти «математические изыскания» лишние, а нужно лишь найти на просторах интернета правильную процедуру и «прикрутить» её в проект, где она начинает выдавать значения «похожие на правильные». Подобный ситуативный путь решения проблемы разработчиком приводит к тому, что корректно проверить, модифицировать найденный код не представляется возможным и, соответственно, верифицировать получаемый результат тоже.
Триада
Данные проблемы возникают из-за того, что при описании МНК не описывается путь перехода от математического описания метода к его программной реализации. Данная проблема была давно преодолена одним из отцов-основателей математического моделирования в нашей стране академиком Самарским А.А., который предложил универсальную методологию вычислительного эксперимента в виде триады «модель-алгоритм-программа».

Из предложенной схемы становится видно, что путь от модели объекта к программе лежит через её алгоритмическое описание. Таким образом, в представленной парадигме для детального объяснения МНК нужно:
-
описать математическую модель объекта/процесса, анализируемые параметры которой формализуются в виде некой функциональной зависимости;
-
синтезировать алгоритм оценки искомых параметров модели на основе МНК;
-
выполнить программную реализацию полученного алгоритма.
Попробуем абстракции последних абзацев пояснить на примере. Пусть в качестве моделируемого объекта будем рассматривать процесс измерения термометром температуры печи, которая линейно зависит от времени и флуктуирует в области истинного значения по нормальному закону. Необходимо по выполненным измерениям определить зависимость, по которой изменяется температура в печи. При этом ошибка найденной зависимости должна быть минимальной.
В качестве анализируемых данных будем рассматривать n значений температуры, измеренной в градусах, получаемые с использованием термометра и зависящие от времени. Эти данные представим в виде таблицы, где строки – это объекты, первый столбец – набор параметров (j=1), второй столбец – набор измеренных ответов:

т.е. случайная величина, распределённая по закону Гаусса с фиксированным значением среднеквадратического отклонения (СКО), нулевым математическим ожиданием (МО) и с автокорреляционной функцией в виде дельта-функции.
Ниже приведен код, генерирующий набор данных на python. Для реализации приведенного в статье кода потребуется импортировать несколько библиотек.
import random
import matplotlib.pyplot as plt
import numpy as np
def datasets_make_regression(coef, data_size, noise_sigma, random_state):
x = np.arange(0, data_size, 1.)
mu = 0.0
random.seed(random_state)
noise = np.empty((data_size, 1))
y = np.empty((data_size, 1))
for i in range(data_size):
noise[i] = random.gauss(mu, noise_sigma)
y[i] = coef[0] + coef[1]*x[i] + noise[i]
return x, y
coef_true = [34.2, 2.] # весовые коэффициенты
data_size = 200 # размер генерируемого набора данных
noise_sigma = 10 # СКО шума в данных
random_state = 42
x_scale, y_estimate = datasets_make_regression(coef_true, data_size, noise_sigma, random_state)
plt.plot(x_scale, y_estimate, 'o')
plt.xlabel('x (порядковый номер измерения)', fontsize=14)
plt.ylabel('y (оценка температуры)', fontsize=14)Сгенерированный набор данных будет иметь вид

Математическая модель
Далее математическая модель будет описана три раза. Последовательно уровень абстракции при описании модели будет понижаться и конкретизироваться. Эти описания приведены для того, чтобы в дальнейшем материал, приведенный в статье, можно было соотнести с классическими изданиями.
Первое описание математической модели. Самое общее.
Поскольку мы рассматриваем процесс, который связывает набор наблюдаемых параметров и измеренных ответов с минимальной ошибкой этой связи, то математическую модель этого процесса в общем виде можно представить

Второе описание математической модели. Общее описание линейной модели.
Поскольку по условию задачи мы рассматриваем линейную зависимость, на которую влияет шум, имеющий нормальное распределение с нулевым средним значением, то используем линейную относительно параметров модель, а метрикой выберем расчёт СКО ошибки

Третье описание математической модели. Модель конкретизирована под условия примера.
Поскольку по условию задачи мы рассматриваем линейную зависимость одного параметра (поскольку j=1, то далее эту зависимость при описании опустим), на оценку которого влияет шум, имеющий нормальное распределение, то используем линейную модель с двумя коэффициентами

Обсуждение моделей
Было рассмотрено три модели, описывающих процесс изменения температуры в печи. Первая модель описана в наиболее общем виде, а третья приведена в виде, наиболее соответствующем начальным условиям задачи. В третьей модели учтен линейный закон изменения температуры (используется линейная модель) и нормальный закон распределения шума в измерениях (используется квадратичная функция ошибки).
Хочется отметить, что параметры математической модели процесса изменения температуры, описанной в выражении (2), в принципе, могут находиться не только методом наименьших квадратов, поскольку метрика с квадратичной функцией ошибки в явном виде не прописана. Такая общая форма записи приведена, поскольку не представляется возможным в кратком виде привести все возможные модификации МНК, у которого минимизация для различных условий может выполняться также различно.
В выражениях (3) и (4) линейные модели отличаются только количеством учитываемых параметров, причем третья модель – это редуцированная вторая модель, у которой только два коэффициента (один свободный и один весовой коэффициенты).
Далее с использованием выражения (4) и МНК, синтезируем алгоритмы, оценивающие параметры модели.
Алгоритмы и реализующие их программы
Далее будут выведены три алгоритма, результат работы которых позволит определить зависимость изменения температуры печи от времени. Последовательно сложность конечных выражений, используемых в алгоритмах, будет понижаться. Эти алгоритмы приведены для того, чтобы полученные выражения, можно было соотнести с классическими изданиями.

Начнем с применения правила дифференцирования функции представленной в виде суммы

применим правило дифференцирования сложной функции

применим правило дифференцирования функции представленной в виде суммы


применим правило дифференцирования функции представленной в виде суммы

Приравняем полученные производные к нулю и решим полученную систему уравнений

Раскроем скобки
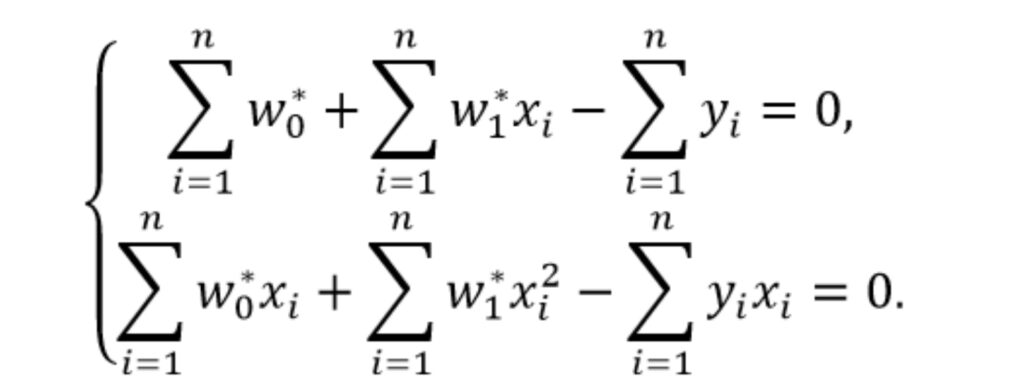
Вынесем постоянные множители за скобки

Вынесем слагаемые с множителем «y» в правую часть уравнений

Поставим слагаемые с множителем «x» в левой части в порядке убывания степеней

Для решения полученной системы алгебраических уравнения представим её в матричной форме
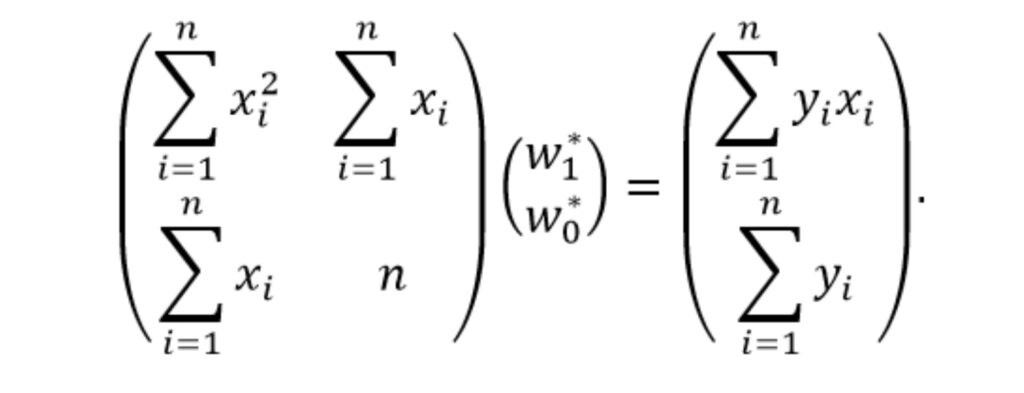
Выразим вектор w* с искомыми весами выполнив умножение обеих частей равенства на обратную матрицу y

Полученное выражение (5) является решением системы уравнений и его можно уже использовать в качестве первого алгоритма оценки параметров модели. Ниже приведен код реализующий этот алгоритм.
def coefficient_reg_inv(x, y):
size = len(x)
# формируем и заполняем матрицу размерностью 2x2
A = np.empty((2, 2))
A[[0], [0]] = sum((x[i])**2 for i in range(0,size))
A[[0], [1]] = sum(x)
A[[1], [0]] = sum(x)
A[[1], [1]] = size
# находим обратную матрицу
A = np.linalg.inv(A)
# формируем и заполняем матрицу размерностью 2x1
C = np.empty((2, 1))
C[0] = sum((x[i]*y[i]) for i in range(0,size))
C[1] = sum((y[i]) for i in range(0,size))
# умножаем матрицу на вектор
ww = np.dot(A, C)
return ww[1], ww[0]
[w0_1, w1_1] = coefficient_reg_analit(x_scale, y_estimate)
print(w0_1, w1_1)Результат работы алгоритма:
[33.93193341] [2.01436546]Выражение (5) можно упростить, выполнив аналитический расчет обратной матрицы.
Найти обратную матрицу можно с использованием, например, алгебраических дополнений. Для пояснения поиска обратной матрицы введем новую переменную A. Пусть

Перепишем выражение (5) в виде
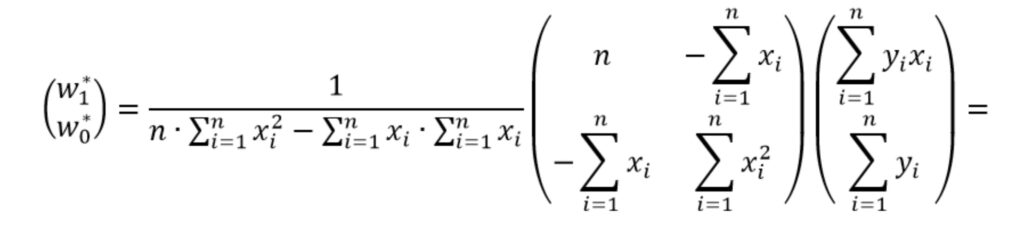
Упростим выражение раскрыв скобки, чтобы получить более компактную форму записи

Теперь решение системы уравнений имеет вид
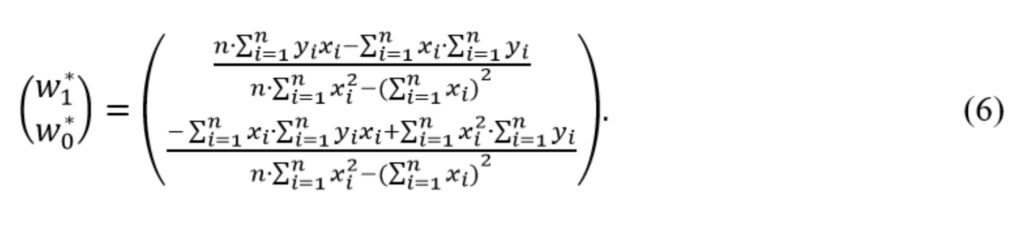
Полученное выражение (6) можно использовать в качестве второго алгоритма оценки параметров модели. Ниже приведен код, реализующий этот алгоритм.
def coefficient_reg_inv_analit(x, y):
size = len(x)
# выполним расчет числителя первого элемента вектора
numerator_w1 = size*sum(x[i]*y[i] for i in range(0,size)) - sum(x)*sum(y)
# выполним расчет знаменателя (одинаковый для обоих элементов вектора)
denominator = size*sum((x[i])**2 for i in range(0,size)) - (sum(x))**2
# выполним расчет числителя второго элемента вектора
numerator_w0 = -sum(x)*sum(x[i]*y[i] for i in range(0,size)) + sum((x[i])**2 for i in range(0,size))*sum(y)
# расчет искомых коэффициентов
w1 = numerator_w1/denominator
w0 = numerator_w0/denominator
return w0, w1
[w0_2, w1_2] = coefficient_reg_inv_analit(x_scale, y_estimate)
print(w0_2, w1_2)Результат работы алгоритма:
[33.93193341] [2.01436546]Видно, что полученный результат совпадает с результатом, полученным с использованием выражения (5).
Выполним дальнейшее упрощение полученного выражения (6), чтобы получить более компактную форму записи.

раскроем скобки:

Ведем новые переменные используя термины математической статистики:

С учётом введённых переменных искомый вектор w* примет вид


Таким образом итоговое выражение представим в виде:

Полученное выражение (7) можно использовать в качестве третьего алгоритмаоценки параметров модели. Ниже приведен код, реализующий этот алгоритм.
def coefficient_reg_stat(x, y):
size = len(x)
avg_x = sum(x)/len(x) # оценка МО величины x
avg_y = sum(y)/len(y) # оценка МО величины y
# оценка МО величины x*y
avg_xy = sum(x[i]*y[i] for i in range(0,size))/size
# оценка СКО величины x
std_x = (sum((x[i] - avg_x)**2 for i in range(0,size))/size)**0.5
# оценка СКО величины y
std_y = (sum((y[i] - avg_y)**2 for i in range(0,size))/size)**0.5
# оценка коэффициента корреляции величин x и y
corr_xy = (avg_xy - avg_x*avg_y)/(std_x*std_y)
# расчет искомых коэффициентов
w1 = corr_xy*std_y/std_x
w0 = avg_y - avg_x*w1
return w0, w1
[w0_3, w1_3] = coefficient_reg_stat(x_scale, y_estimate)
print(w0_3, w1_3)Результат работы алгоритма:
[33.93193341] [2.01436546]Сравним полученные значения с результатом работы процедуры библиотеки sklearn.
from sklearn.linear_model import LinearRegression
# преобразование размерности массива x_scale для корректной работы model.fit
x_scale = x_scale.reshape((-1,1))
model = LinearRegression()
model.fit(x_scale, y_estimate)
print(model.intercept_, model.coef_)Результат работы алгоритма:
[33.93193341] [2.01436546]Видно, что полученный результат полностью совпадает с результатами, полученными ранее.
Итак, визуализируем полученный результат, построив прямую с использованием рассчитанных коэффициентов и сопоставим их с исходными данными (рисунок 2).
def predict(w0, w1, x_scale):
y_pred = [w0 + val*w1 for val in x_scale]
return y_pred
y_predict = predict(w0_1, w1_1, x_scale)
plt.plot(x_scale, y_estimate, 'o', label = 'Истинные значения')
plt.plot(x_scale, y_predict, '*', label = 'Расчетные значения')
plt.legend(loc = 'best', fontsize=12)
plt.xlabel('x (порядковый номер измерения)', fontsize=14)
plt.ylabel('y (оценка температуры)', fontsize=14)
Обсуждение алгоритмов
Таким образом удалось выполнить оценку параметров модели, которая описывает процесс изменения температуры в печи с минимальной ошибкой. Выведенные выражения (5) – (7) и запрограммированные по ним три алгоритма, реализующие МНК при обработке одного набора измеренных температур, хотя и отличаются видом конечных выражений, дают одинаковые оценки. Последовательный вывод выражений, выполненный в статье, показывает, что эти выражения по сути «делают» одно и тоже, однако, позволяют давать различные интерпретации. При этом хочется отметить, что в алгоритмах (6) – (7) удалось уйти от процедуры обращения матрицы, которая при обработке реальных данных может выполняться нестабильно.
Ещё один пример. Анализируем остатки.

-
количество выбросов в выборке равно 10;
-
длительность импульса равна 1-му измерению;
-
амплитуда импульса равна 256;
-
позиция первого импульса соответствует 10-му измерению;
-
период следования импульсов – каждые 20 измерений.
ni = 10 # количество выбросов
ind_impuls = np.arange(ni, data_size, 20) # индексы выбросов
y_estimate_imp = y_estimate.copy() # выборка с выбросами
for i in range(0, ni):
y_estimate_imp[ind_impuls[i]] += 256
[w0_imp, w1_imp] = coefficient_reg_stat(x_scale, y_estimate_imp)
y_pred_imp = predict(w0_imp, w1_imp, x_scale)
plt.plot(x_scale, y_estimate_imp, 'o', label = 'Истинные значения')
plt.plot(x_scale, y_pred_imp, '*', label = 'Расчетные значения')
plt.legend(loc = 'best', fontsize=12)
plt.xlabel('x (порядковый номер измерения)', fontsize=14)
plt.ylabel('y (оценка температуры)', fontsize=14) 
На рисунке 3 видно, что появление выбросов сместило, рассчитанную по выражению (7) прямую в вверх. Модифицируем алгоритм оценки параметров модели за счет новой метрики, а именно оценки квадратов разности между измеренными и модельными данными, которая выполняется по выражению

Ниже приведен код, который выполняет этот расчет (8) и визуализирует полученный результат (рисунок 4).
SqErr = (y_pred_imp - y_estimate_imp)**2
plt.plot(x_scale, SqErr, 'o')
plt.xlabel('x (порядковый номер измерения)', fontsize=14)
plt.ylabel('Квадрат ошибки', fontsize=14)
Для устранения влияния помехи на оценки параметров модели, получаемых с использованием алгоритмов, дополнительно введем процедуру цензурирования (отбрасывания) данных, которые имеют большое значение квадрата ошибки (8). С новыми начальными условиями алгоритм оценки параметров модели теперь дополняется следующей последовательностью действий

def censor_data(SqErr, nCensor):
# индексы отсортированного во возрастанию массива с квадратами ошибок
I = np.argsort(SqErr[:,0])
ind_imp = I[-nCensor:]
ind_imp = ind_imp[::-1] # разворот индексов массива
w0 = np.empty((nCensor, 1))
w1 = np.empty((nCensor, 1))
for i in range(0,nCensor):
# цензурирование данных
x_scale_cens = np.delete(x_scale, ind_imp[0:i], 0)
y_estimate_imp_cens = np.delete(y_estimate_imp, ind_imp[0:i], 0)
# расчёт параметров модельной прямой
w0[i], w1[i] = coefficient_reg_stat(x_scale_cens, y_estimate_imp_cens)
y_pred2_cens = predict(w0[i], w1[i], x_scale_cens)
return w0, w1
nCensor = 20 # количество отбрасываемых выбросов
[w0_с, w1_с] = censor_data(SqErr, nCensor)
plt.plot(coef_true[0], coef_true[1], 'o', label = 'Истинные значения')
plt.plot(w0_с, w1_с, '-*', label = 'Расчетные значения')
plt.legend(loc = 'best', fontsize=12)
plt.xlim((30, 50))
plt.ylim((1.85, 2.15))
plt.xlabel('w0', fontsize=18)
plt.ylabel('w1', fontsize=18)По итогам работы алгоритма построим полученные оценки параметров модели (рисунок 5) по мере цензурирования данных.

В результате работы рассматриваемого алгоритма видно (рисунок 5), что по мере цензурирования помеховых данных параметры модели приближаются к истинным (точка с оценкой параметров возле i=1 получена после удаления первой точки, точка с оценкой параметров возле i=20 получена после удаления двадцатой точки).
Ниже приведен код, который рассчитывает и строит на графике прямую (рисунок 6) с использованием параметров модели, полученной на последнем шаге алгоритма c цензурированием. На этом рисунке видно, что использование дополнительной процедуры цензурирования данных на основе анализа остаточной суммы квадратов, позволяет улучшить согласование оцениваемых параметров с истинными.
y_pred_censor = predict(w0_с[nCensor-1], w1_с[nCensor-1], x_scale)
plt.plot(x_scale, y_estimate_imp, 'o', label = 'Истинные значения')
plt.plot(x_scale, y_pred_censor, '*', label = 'Расчетные значения')
plt.legend(loc = 'best', fontsize=12)
plt.xlabel('X (порядковый номер измерения)', fontsize=14)
plt.ylabel('Y (оценка температуры)', fontsize=14)
Обсуждение алгоритма
Был рассмотрен алгоритм оценки параметров модели, которая описывает процесс изменения температуры в печи при наличии помех в измерениях. Показано, как зная логику построения алгоритма его можно модифицировать под изменившиеся условия и получить необходимый результат (оценку параметров модели).
Безусловно, что приведенный в статье алгоритм оценки параметров модели с использованием процедуры цензурирования импульсных помеховых сигналов (в том виде, в котором он приведен в статье) не является оптимальным и универсальным. Он приведен здесь для иллюстрации возможностей модификации алгоритма, реализующего классический МНК. А также для демонстрации ещё одной важной метрики при использовании МНК – оценка квадратов разности между измеренными и модельными данными (8), которая является источником множества различных модификаций метода.
Заключение
В статье делается попытка «расколдовать» классический МНК, а также продемонстрировать удобство методологической интерпретации решения задачи в виде триады «модель-алгоритм-программа», которая позволяет осуществить бесшовный переход от модельной постановки задачи и задания начальных условий до её программной реализации. Ставилась задача в максимально доступной для читателя форме продемонстрировать последовательность математической мысли при решении задачи с применением МНК. Показать, как начальные условия влияют на полученные конечные выражения. Автор надеется, что статья будет полезной для всех тех, кто при решении различных задач анализа данных попытается применить или модифицировать классические методы и для этого попробует также с «карандашом в руках» выполнить вывод конечных выражений. Этот подход позволит разработчику применять на практике понятные для него алгоритмы, а не код, который работает «по неведомым» правилам.
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
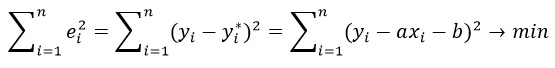
частные производные функции приравниваем к нулю
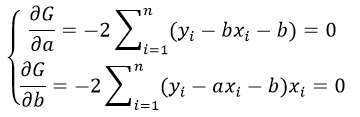
отсюда получаем систему линейных уравнений
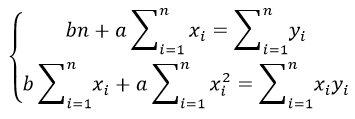
Формулы определения коэффициентов уравнения линейной регрессии:
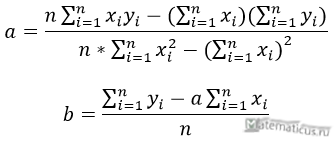
Также запишем уравнение регрессии для квадратной нелинейной функции:
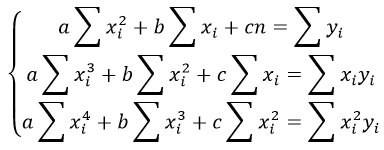
Система линейных уравнений регрессии полинома n-ого порядка:
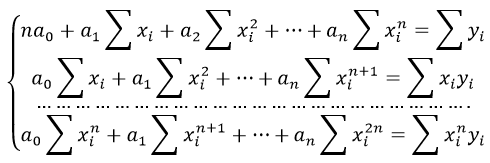
Формула коэффициента детерминации R2:
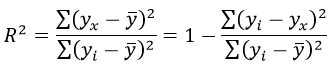
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
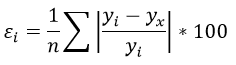
Чем меньше ε, тем лучше. Рекомендованный показатель ε<10%
Формула среднеквадратической погрешности:
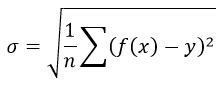
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
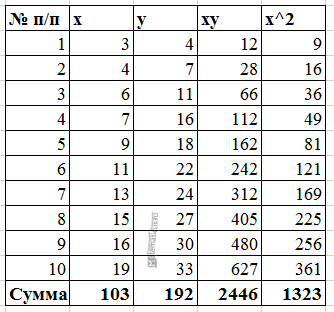
Расчет коэффициентов линейной регрессии:
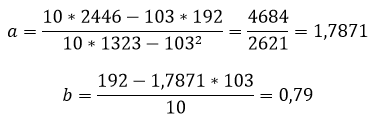
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
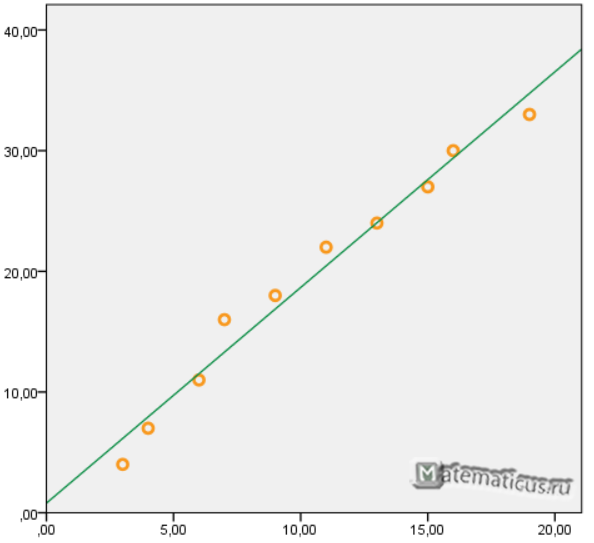
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
![]() 16130
16130
Метод наименьших квадратов регрессия
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
частные производные функции приравниваем к нулю
отсюда получаем систему линейных уравнений
Формулы определения коэффициентов уравнения линейной регрессии:
Также запишем уравнение регрессии для квадратной нелинейной функции:
Система линейных уравнений регрессии полинома n-ого порядка:
Формула коэффициента детерминации R 2 :
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
Чем меньше ε, тем лучше. Рекомендованный показатель ε
Формула среднеквадратической погрешности:
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
Расчет коэффициентов линейной регрессии:
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
Метод наименьших квадратов
Начнем статью сразу с примера. У нас есть некие экспериментальные данные о значениях двух переменных – x и y . Занесем их в таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | |
| x i | 0 | 1 | 2 | 4 | 5 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 , 0 |
После выравнивания получим функцию следующего вида: g ( x ) = x + 1 3 + 1 .
Мы можем аппроксимировать эти данные с помощью линейной зависимости y = a x + b , вычислив соответствующие параметры. Для этого нам нужно будет применить так называемый метод наименьших квадратов. Также потребуется сделать чертеж, чтобы проверить, какая линия будет лучше выравнивать экспериментальные данные.
В чем именно заключается МНК (метод наименьших квадратов)
Главное, что нам нужно сделать, – это найти такие коэффициенты линейной зависимости, при которых значение функции двух переменных F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 будет наименьшим. Иначе говоря, при определенных значениях a и b сумма квадратов отклонений представленных данных от получившейся прямой будет иметь минимальное значение. В этом и состоит смысл метода наименьших квадратов. Все, что нам надо сделать для решения примера – это найти экстремум функции двух переменных.
Как вывести формулы для вычисления коэффициентов
Для того чтобы вывести формулы для вычисления коэффициентов, нужно составить и решить систему уравнений с двумя переменными. Для этого мы вычисляем частные производные выражения F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 по a и b и приравниваем их к 0 .
δ F ( a , b ) δ a = 0 δ F ( a , b ) δ b = 0 ⇔ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i = 0 — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = 1 n y i ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Для решения системы уравнений можно использовать любые методы, например, подстановку или метод Крамера. В результате у нас должны получиться формулы, с помощью которых вычисляются коэффициенты по методу наименьших квадратов.
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n
Мы вычислили значения переменных, при который функция
F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 примет минимальное значение. В третьем пункте мы докажем, почему оно является именно таким.
Это и есть применение метода наименьших квадратов на практике. Его формула, которая применяется для поиска параметра a , включает в себя ∑ i = 1 n x i , ∑ i = 1 n y i , ∑ i = 1 n x i y i , ∑ i = 1 n x i 2 , а также параметр
n – им обозначено количество экспериментальных данных. Советуем вам вычислять каждую сумму отдельно. Значение коэффициента b вычисляется сразу после a .
Обратимся вновь к исходному примеру.
Здесь у нас n равен пяти. Чтобы было удобнее вычислять нужные суммы, входящие в формулы коэффициентов, заполним таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | ∑ i = 1 5 | |
| x i | 0 | 1 | 2 | 4 | 5 | 12 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Решение
Четвертая строка включает в себя данные, полученные при умножении значений из второй строки на значения третьей для каждого отдельного i . Пятая строка содержит данные из второй, возведенные в квадрат. В последнем столбце приводятся суммы значений отдельных строчек.
Воспользуемся методом наименьших квадратов, чтобы вычислить нужные нам коэффициенты a и b . Для этого подставим нужные значения из последнего столбца и подсчитаем суммы:
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n ⇒ a = 5 · 33 , 8 — 12 · 12 , 9 5 · 46 — 12 2 b = 12 , 9 — a · 12 5 ⇒ a ≈ 0 , 165 b ≈ 2 , 184
У нас получилось, что нужная аппроксимирующая прямая будет выглядеть как y = 0 , 165 x + 2 , 184 . Теперь нам надо определить, какая линия будет лучше аппроксимировать данные – g ( x ) = x + 1 3 + 1 или 0 , 165 x + 2 , 184 . Произведем оценку с помощью метода наименьших квадратов.
Чтобы вычислить погрешность, нам надо найти суммы квадратов отклонений данных от прямых σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 и σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 , минимальное значение будет соответствовать более подходящей линии.
σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 = = ∑ i = 1 5 ( y i — ( 0 , 165 x i + 2 , 184 ) ) 2 ≈ 0 , 019 σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 = = ∑ i = 1 5 ( y i — ( x i + 1 3 + 1 ) ) 2 ≈ 0 , 096
Ответ: поскольку σ 1 σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0 , 165 x + 2 , 184 .
Как изобразить МНК на графике функций
Метод наименьших квадратов наглядно показан на графической иллюстрации. С помощью красной линии отмечена прямая g ( x ) = x + 1 3 + 1 , синей – y = 0 , 165 x + 2 , 184 . Исходные данные обозначены розовыми точками.
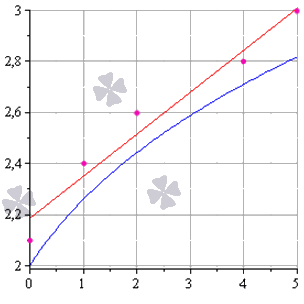
Поясним, для чего именно нужны приближения подобного вида.
Они могут быть использованы в задачах, требующих сглаживания данных, а также в тех, где данные надо интерполировать или экстраполировать. Например, в задаче, разобранной выше, можно было бы найти значение наблюдаемой величины y при x = 3 или при x = 6 . Таким примерам мы посвятили отдельную статью.
Доказательство метода МНК
Чтобы функция приняла минимальное значение при вычисленных a и b , нужно, чтобы в данной точке матрица квадратичной формы дифференциала функции вида F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 была положительно определенной. Покажем, как это должно выглядеть.
У нас есть дифференциал второго порядка следующего вида:
d 2 F ( a ; b ) = δ 2 F ( a ; b ) δ a 2 d 2 a + 2 δ 2 F ( a ; b ) δ a δ b d a d b + δ 2 F ( a ; b ) δ b 2 d 2 b
Решение
δ 2 F ( a ; b ) δ a 2 = δ δ F ( a ; b ) δ a δ a = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ a = 2 ∑ i = 1 n ( x i ) 2 δ 2 F ( a ; b ) δ a δ b = δ δ F ( a ; b ) δ a δ b = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ b = 2 ∑ i = 1 n x i δ 2 F ( a ; b ) δ b 2 = δ δ F ( a ; b ) δ b δ b = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) δ b = 2 ∑ i = 1 n ( 1 ) = 2 n
Иначе говоря, можно записать так: d 2 F ( a ; b ) = 2 ∑ i = 1 n ( x i ) 2 d 2 a + 2 · 2 ∑ x i i = 1 n d a d b + ( 2 n ) d 2 b .
Мы получили матрицу квадратичной формы вида M = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
В этом случае значения отдельных элементов не будут меняться в зависимости от a и b . Является ли эта матрица положительно определенной? Чтобы ответить на этот вопрос, проверим, являются ли ее угловые миноры положительными.
Вычисляем угловой минор первого порядка: 2 ∑ i = 1 n ( x i ) 2 > 0 . Поскольку точки x i не совпадают, то неравенство является строгим. Будем иметь это в виду при дальнейших расчетах.
Вычисляем угловой минор второго порядка:
d e t ( M ) = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2
После этого переходим к доказательству неравенства n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 с помощью математической индукции.
- Проверим, будет ли данное неравенство справедливым при произвольном n . Возьмем 2 и подсчитаем:
2 ∑ i = 1 2 ( x i ) 2 — ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 — x 1 + x 2 2 = = x 1 2 — 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
У нас получилось верное равенство (если значения x 1 и x 2 не будут совпадать).
- Сделаем предположение, что данное неравенство будет верным для n , т.е. n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 – справедливо.
- Теперь докажем справедливость при n + 1 , т.е. что ( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 > 0 , если верно n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 .
( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 = = ( n + 1 ) ∑ i = 1 n ( x i ) 2 + x n + 1 2 — ∑ i = 1 n x i + x n + 1 2 = = n ∑ i = 1 n ( x i ) 2 + n · x n + 1 2 + ∑ i = 1 n ( x i ) 2 + x n + 1 2 — — ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + n · x n + 1 2 — x n + 1 ∑ i = 1 n x i + ∑ i = 1 n ( x i ) 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + x n + 1 2 — 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 — 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 — 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + + ( x n + 1 — x 1 ) 2 + ( x n + 1 — x 2 ) 2 + . . . + ( x n — 1 — x n ) 2 > 0
Выражение, заключенное в фигурные скобки, будет больше 0 (исходя из того, что мы предполагали в пункте 2 ), и остальные слагаемые будут больше 0 , поскольку все они являются квадратами чисел. Мы доказали неравенство.
Ответ: найденные a и b будут соответствовать наименьшему значению функции F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 , значит, они являются искомыми параметрами метода наименьших квадратов (МНК).
Математика на пальцах: методы наименьших квадратов

Я математик-программист. Самый большой скачок в своей карьере я совершил, когда научился говорить:«Я ничего не понимаю!» Сейчас мне не стыдно сказать светилу науки, что мне читает лекцию, что я не понимаю, о чём оно, светило, мне говорит. И это очень сложно. Да, признаться в своём неведении сложно и стыдно. Кому понравится признаваться в том, что он не знает азов чего-то-там. В силу своей профессии я должен присутствовать на большом количестве презентаций и лекций, где, признаюсь, в подавляющем большинстве случаев мне хочется спать, потому что я ничего не понимаю. А не понимаю я потому, что огромная проблема текущей ситуации в науке кроется в математике. Она предполагает, что все слушатели знакомы с абсолютно всеми областями математики (что абсурдно). Признаться в том, что вы не знаете, что такое производная (о том, что это — чуть позже) — стыдно.
Но я научился говорить, что я не знаю, что такое умножение. Да, я не знаю, что такое подалгебра над алгеброй Ли. Да, я не знаю, зачем нужны в жизни квадратные уравнения. К слову, если вы уверены, что вы знаете, то нам есть над чем поговорить! Математика — это серия фокусов. Математики стараются запутать и запугать публику; там, где нет замешательства, нет репутации, нет авторитета. Да, это престижно говорить как можно более абстрактным языком, что есть по себе полная чушь.
Знаете ли вы, что такое производная? Вероятнее всего вы мне скажете про предел разностного отношения. На первом курсе матмеха СПбГУ Виктор Петрович Хавин мне определил производную как коэффициент первого члена ряда Тейлора функции в точке (это была отдельная гимнастика, чтобы определить ряд Тейлора без производных). Я долго смеялся над таким определением, покуда в итоге не понял, о чём оно. Производная не что иное, как просто мера того, насколько функция, которую мы дифференцируем, похожа на функцию y=x, y=x^2, y=x^3.
Я сейчас имею честь читать лекции студентам, которые боятся математики. Если вы боитесь математики — нам с вами по пути. Как только вы пытаетесь прочитать какой-то текст, и вам кажется, что он чрезмерно сложен, то знайте, что он хреново написан. Я утверждаю, что нет ни одной области математики, о которой нельзя говорить «на пальцах», не теряя при этом точности.
Задача на ближайшее время: я поручил своим студентам понять, что такое линейно-квадратичный регулятор. Не постесняйтесь, потратьте три минуты своей жизни, сходите по ссылке. Если вы ничего не поняли, то нам с вами по пути. Я (профессиональный математик-программист) тоже ничего не понял. И я уверяю, в этом можно разобраться «на пальцах». На данный момент я не знаю, что это такое, но я уверяю, что мы сумеем разобраться.
Итак, первая лекция, которую я собираюсь прочитать своим студентам после того, как они в ужасе прибегут ко мне со словами, что линейно-квадратичный регулятор — это страшная бяка, которую никогда в жизни не осилить, это методы наименьших квадратов. Умеете ли вы решать линейные уравнения? Если вы читаете этот текст, то скорее всего нет.
Итак, даны две точки (x0, y0), (x1, y1), например, (1,1) и (3,2), задача найти уравнение прямой, проходящей через эти две точки:
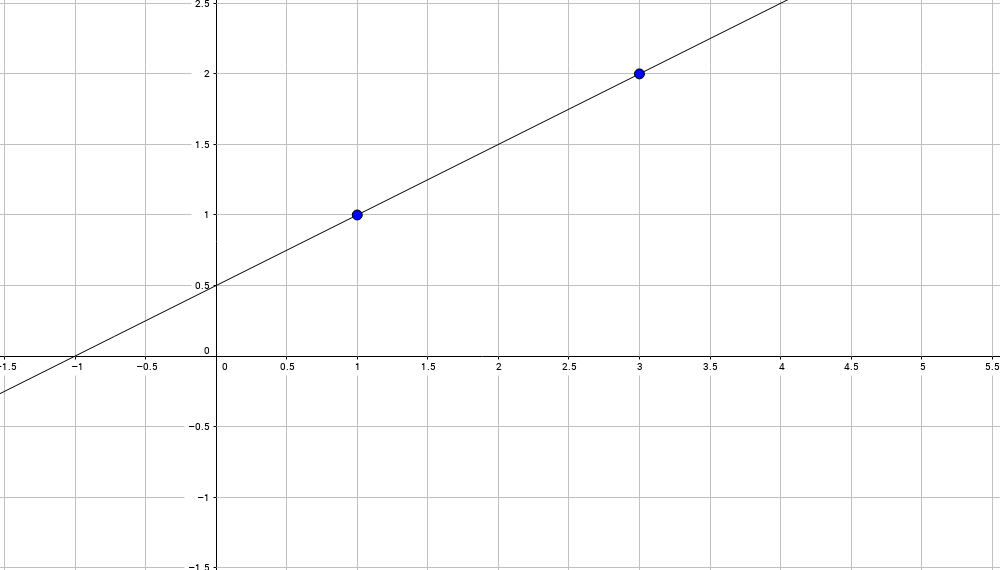
Эта прямая должна иметь уравнение типа следующего:
Здесь альфа и бета нам неизвестны, но известны две точки этой прямой:
Можно записать это уравнение в матричном виде:
Тут следует сделать лирическое отступление: что такое матрица? Матрица это не что иное, как двумерный массив. Это способ хранения данных, более никаких значений ему придавать не стоит. Это зависит от нас, как именно интерпретировать некую матрицу. Периодически я буду её интерпретировать как линейное отображение, периодически как квадратичную форму, а ещё иногда просто как набор векторов. Это всё будет уточнено в контексте.
Давайте заменим конкретные матрицы на их символьное представление:
Тогда (alpha, beta) может быть легко найдено:
Более конкретно для наших предыдущих данных:
Что ведёт к следующему уравнению прямой, проходящей через точки (1,1) и (3,2):
Окей, тут всё понятно. А давайте найдём уравнение прямой, проходящей через три точки: (x0,y0), (x1,y1) и (x2,y2):
Ой-ой-ой, а ведь у нас три уравнения на две неизвестных! Стандартный математик скажет, что решения не существует. А что скажет программист? А он для начала перепишет предыдующую систему уравнений в следующем виде:
И дальше постарается найти решение, которое меньше всего отклонится от заданных равенств. Давайте назовём вектор (x0,x1,x2) вектором i, (1,1,1) вектором j, а (y0,y1,y2) вектором b:
В нашем случае векторы i,j,b трёхмерны, следовательно, (в общем случае) решения этой системы не существует. Любой вектор (alpha*i + beta*j) лежит в плоскости, натянутой на векторы (i, j). Если b не принадлежит этой плоскости, то решения не существует (равенства в уравнении не достичь). Что делать? Давайте искать компромисс. Давайте обозначим через e(alpha, beta) насколько именно мы не достигли равенства:
И будем стараться минимизировать эту ошибку:
Очевидно, что ошибка минимизируется, когда вектор e ортогонален плоскости, натянутой на векторы i и j.
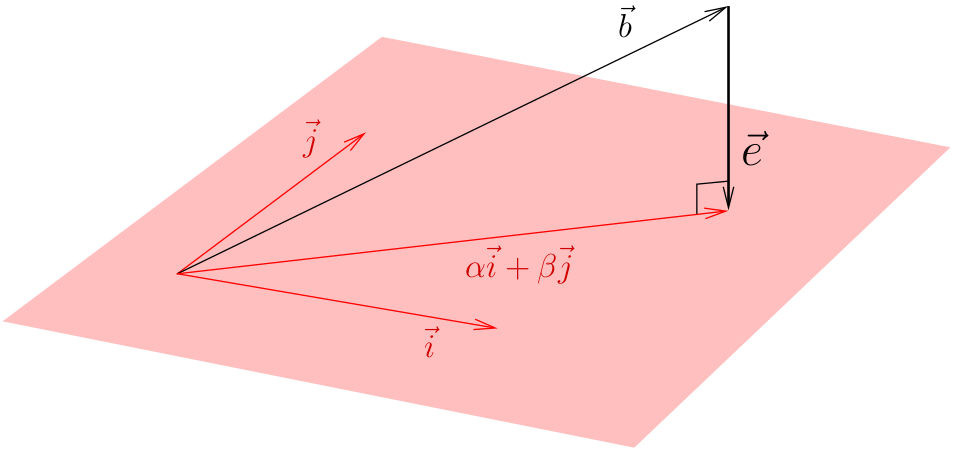
Иными словами: мы ищем такую прямую, что сумма квадратов длин расстояний от всех точек до этой прямой минимальна:
UPDATE: тут у меня косяк, расстояние до прямой должно измеряться по вертикали, а не ортогональной проекцией. Вот этот комментатор прав.
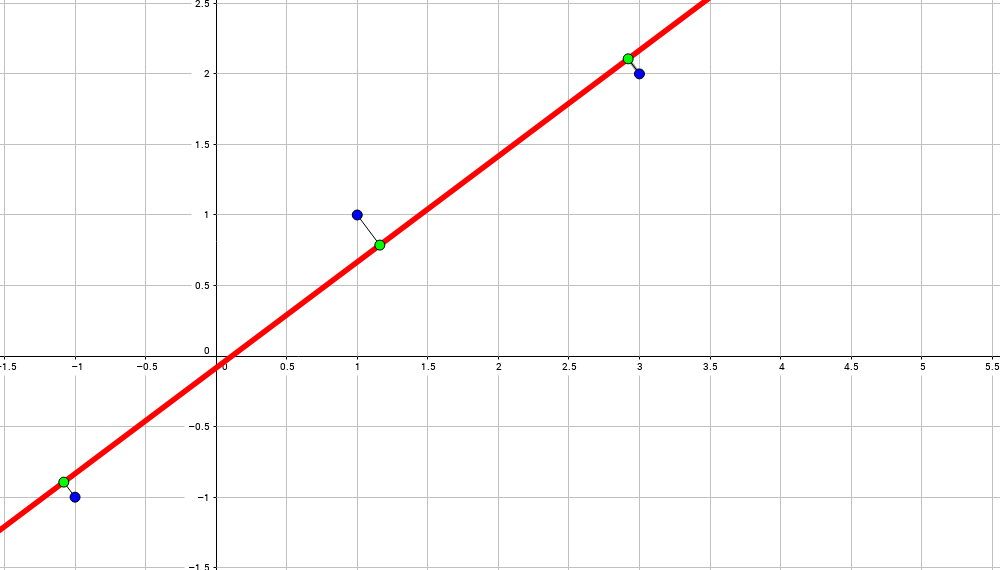
Совсеми иными словами (осторожно, плохо формализовано, но на пальцах должно быть ясно): мы берём все возможные прямые между всеми парами точек и ищем среднюю прямую между всеми:
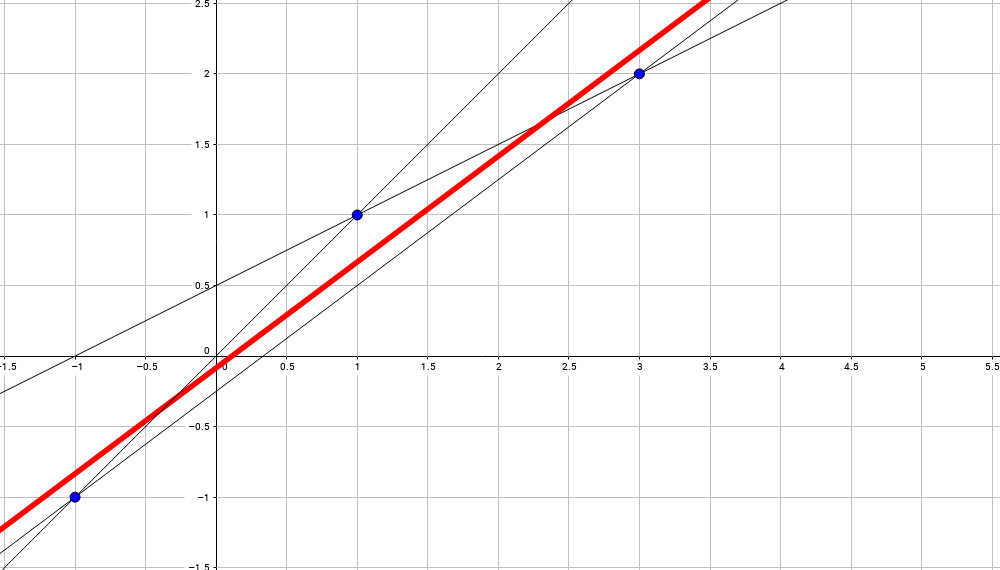
Иное объяснение на пальцах: мы прикрепляем пружинку между всеми точками данных (тут у нас три) и прямой, что мы ищем, и прямая равновесного состояния есть именно то, что мы ищем.
Минимум квадратичной формы
Итак, имея данный вектор b и плоскость, натянутую на столбцы-векторы матрицы A (в данном случае (x0,x1,x2) и (1,1,1)), мы ищем вектор e с минимум квадрата длины. Очевидно, что минимум достижим только для вектора e, ортогонального плоскости, натянутой на столбцы-векторы матрицы A:
Иначе говоря, мы ищем такой вектор x=(alpha, beta), что:
Напоминаю, что этот вектор x=(alpha, beta) является минимумом квадратичной функции ||e(alpha, beta)||^2:
Тут нелишним будет вспомнить, что матрицу можно интерпретирвать в том числе как и квадратичную форму, например, единичная матрица ((1,0),(0,1)) может быть интерпретирована как функция x^2 + y^2:
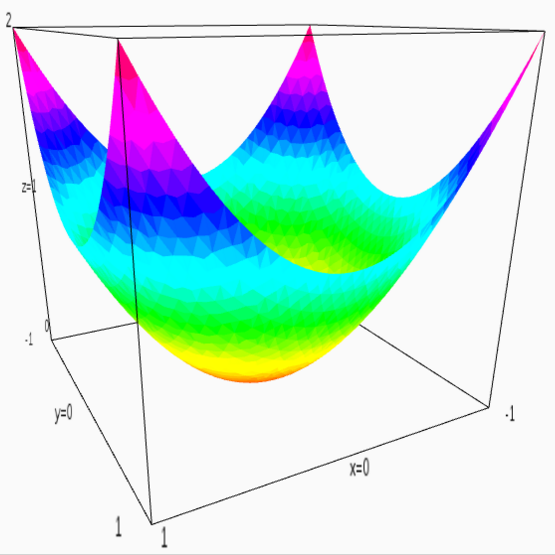
Вся эта гимнастика известна под именем линейной регрессии.
Уравнение Лапласа с граничным условием Дирихле
Теперь простейшая реальная задача: имеется некая триангулированная поверхность, необходимо её сгладить. Например, давайте загрузим модель моего лица:

Изначальный коммит доступен здесь. Для минимизации внешних зависимостей я взял код своего софтверного рендерера, уже подробно описанного на хабре. Для решения линейной системы я пользуюсь OpenNL, это отличный солвер, который, правда, очень сложно установить: нужно скопировать два файла (.h+.c) в папку с вашим проектом. Всё сглаживание делается следующим кодом:
X, Y и Z координаты отделимы, я их сглаживаю по отдельности. То есть, я решаю три системы линейных уравнений, каждое имеет количество переменных равным количеству вершин в моей модели. Первые n строк матрицы A имеют только одну единицу на строку, а первые n строк вектора b имеют оригинальные координаты модели. То есть, я привязываю по пружинке между новым положением вершины и старым положением вершины — новые не должны слишком далеко уходить от старых.
Все последующие строки матрицы A (faces.size()*3 = количеству рёбер всех треугольников в сетке) имеют одно вхождение 1 и одно вхождение -1, причём вектор b имеет нулевые компоненты напротив. Это значит, я вешаю пружинку на каждое ребро нашей треугольной сетки: все рёбра стараются получить одну и ту же вершину в качестве отправной и финальной точки.
Ещё раз: переменными являются все вершины, причём они не могут далеко отходить от изначального положения, но при этом стараются стать похожими друг на друга.
Всё бы было хорошо, модель действительно сглажена, но она отошла от своего изначального края. Давайте чуть-чуть изменим код:
В нашей матрице A я для вершин, что находятся на краю, добавляю не строку из разряда v_i = verts[i][d], а 1000*v_i = 1000*verts[i][d]. Что это меняет? А меняет это нашу квадратичную форму ошибки. Теперь единичное отклонение от вершины на краю будет стоить не одну единицу, как раньше, а 1000*1000 единиц. То есть, мы повесили более сильную пружинку на крайние вершины, решение предпочтёт сильнее растянуть другие. Вот результат:
Давайте вдвое усилим пружинки между вершинами:
Логично, что поверхность стала более гладкой:
А теперь ещё в сто раз сильнее:
Что это? Представьте, что мы обмакнули проволочное кольцо в мыльную воду. В итоге образовавшаяся мыльная плёнка будет стараться иметь наименьшую кривизну, насколько это возможно, касаясь-таки границы — нашего проволочного кольца. Именно это мы и получили, зафиксировав границу и попросив получить гладкую поверхность внутри. Поздравляю вас, мы только что решили уравнение Лапласа с граничными условиями Дирихле. Круто звучит? А на деле всего-навсего одну систему линейных уравнений решить.
Уравнение Пуассона
Давайте ещё крутое имя вспомним.
Предположим, что у меня есть такая картинка:
Всем хороша, только стул мне не нравится.
Разрежу картинку пополам:
И выделю руками стул:
Затем всё, что белое в маске, притяну к левой части картинки, а заодно по всей картинке скажу, что разница между двумя соседними пикселями должна равняться разнице между двумя соседними пикселями правой картинки:
Код и картинки доступны здесь.
Пример из жизни
Я специально не стал делать вылизанные результаты, т.к. мне хотелось всего-навсего показать, как именно можно применять методы наименьших квадратов, это обучающий код. Давайте я теперь дам пример из жизни:
У меня есть некоторое количество фотографий образцов ткани типа вот такой:
Моя задача сделать бесшовные текстуры из фотографий вот такого качества. Для начала я (автоматически) ищу повторяющийся паттерн:
Если я вырежу прямо вот этот четырёхугольник, то из-за искажений у меня края не сойдутся, вот пример четыре раза повторённого паттерна:
Вот фрагмент, где чётко видно шов:
Поэтому я вырезать буду не по ровной линии, вот линия разреза:
А вот повторённый четыре раза паттерн:
И его фрагмент, чтобы было виднее:
Уже лучше, рез шёл не по прямой линии, обойдя всякие завитушки, но всё же шов виден из-за неравномерности освещения на оригинальной фотографии. Вот тут-то и приходит на помощь метод наименьших квадратов для уравнения Пуассона. Вот конечный результат после выравнивания освещения:
Текстура получилась отлично бесшовной, и всё это автоматически из фотографии весьма посредственного качества. Не бойтесь математики, ищите простые объяснения, и будет вам инженерное счастье.
http://zaochnik.com/spravochnik/matematika/stati/metod-naimenshih-kvadratov/
http://habr.com/ru/post/277275/