«Велосипедный набор» или о создании самодельных датасетов для анализа и машинного обучения
Время на прочтение
6 мин
Количество просмотров 4.3K
Несколько лет назад я ненадолго увлекся машинным обучением и анализом данных, даже написал небольшой цикл о моем погружении в этот удивительный мир, с точки зрения полного новичка.
Как часто бывает при изучении чего-то нового, мне очень хотелось сделать свой «велосипед». К сожалению, в математике и программировании я разбираюсь плохо, поэтому кандидатом на роль «велосипеда» стал собственный датасет.
С того момента прошло уже больше двух лет и вот у меня дошли руки поделится с вами своим небольшим опытом.
В статье мы рассмотрим несколько потенциальных источников для самостоятельного сбора данных (в том числе не очень популярных), а также попробуем найти в этом процессе хоть какую-то пользу.

Оглавление:
Часть I: Введение
Часть II: Источники данных
Часть III: Есть ли от этого польза?
Часть IV: Заключение
Часть I: Введение
Из вступительной части вы наверняка уже догадались, что я не гуру анализа данных и машинного обучения. Пионером в области поиска источников открытых данных меня тоже сложно назвать. Поэтому в данной статье речь пойдет не о хороших практиках, а об утолении «зуда в руках» в случае, если вам пришла в голову идея создать свой датасет.
Прошу вас не воспринимать мою статью слишком серьезно.
С момента задумки статьи до её реализации много воды утекло. Ситуация с доступом к открытым данным становится все лучше и лучше. На Хабре за это время появились хорошие подборки различных источников (например, зарубежных), но я все же решил внести свои «5 копеек».
Итак, пришла пора сбросить гнет чужих наборов данных и создать свой «лучший в мире» набор данных, чтобы скормить его потом алгоритму или просто построить «самый эксклюзивный» график на свете.
Часть II: Источники данных
Порталы с открытыми данными можно разделить на несколько категорий.
Специальные порталы с данными для машинного обучения и анализа
На этих порталах как правило данные собраны в форматы удобные для машинного анализа. Остается их только скачать и загрузить.
Мне в первую очередь вспоминается Kaggle. На Хабре уже есть хорошая статья про наборы данных у Kaggle и инструменты самостоятельного поиска датасетов для машинного обучения.
Поскольку цель нашей сегодняшней статьи не столько сделать хорошо, сколько сделать что-то самостоятельно с нуля, мы продолжим движение в сторону менее популярных ресурсов.
Порталы открытых данных различных гос. органов и общественных организаций
Хотя концептуально «Открытое правительство» в России начало формироваться в начале 2010-х годов, лично мне более-менее адекватные данные обычно удавалось найти примерно за период с 2015 года и позже.
На Хабре уже есть критика порталов с открытыми данными РФ от 2017 года. С тех пор ситуация стала лучше. У некоторых порталов даже появись API для доступа. Однако, все равно остается ощущения, что часто данные собирается по принципу: «Нам тут начальство приказало данные открыть, вот вам кушаете не обляпайтесь».
Рассмотрим основные популярные порталы открытых данных.
Портал открытых данных РФ
Портал оставляет не однозначное впечатление. С одной стороны, у портала есть API для доступа к данным и множество разных датасетов.
С другой стороны на портале, часто можно встретить заброшенные и бесполезные наборы данных, например:
- заброшенный набор данных об активных пользователях сети интернет, в котором полезной статистики меньше чем метаданных.
- или набор данных, который нам привез сам «почтальон печкин».

С другой стороны есть люди, которые ответственно выполняют свою работу. Например, данные о величине муниципального долга Ровеньского района и данные об Исполнение бюджетов сельских поселений Ровеньского района ведутся вполне добросовестно и регулярно. Если вы «смелый, ловкий и умелый то…» вполне можете из этих двух наборов создать один, найти аномальные выбросы, несоответствия или даже корреляции между данными.
Я думаю, результат получится не менее убедительным чем на графике про связь фильмов Николаса Кейджа и падение людей в бассейн.
Портал открытых г. Москвы
У портала открытых данных г. Москвы, тоже есть API для доступа к данным.
Сами данные при этом ведутся более порядочно, чем у федерального ресурса.
На сайте есть как геоданные (объекты с привязкой к координатам), так и просто статистика.
В качестве достаточно простого кейса по созданию своего набора данных можно например, скрестить два набора данных и поискать зависимости между данными вызовов подразделений пожарно-спасательного гарнизона города Москвы по административным округам и данными по количеству выявленных общественными пунктами охраны порядка в городе Москве фактов незаконной сдачи жилья в аренду (поднаем) по административным округам Если найдете что-нибудь интересное отпишитесь в комментарии.
Другие стандартизованные источники
У «Северной столицы», тоже есть свой портал открытых данных.
И у других городов РФ тоже есть аналогичные порталы, но они остаются вам на самостоятельное изучение.
Открытые данные можно найти у разных министерств и ведомств, например, у Минтруда.
Также вполне интересно изучить открытые данные Республики Беларусь.
Сайты с информацией
Помимо ресурсов, в том или ином виде адаптированных под концепцию «Открытого правительства» существует множество других сайтов с полезной статистической информацией, например:
- Центробанк РФ – множество различных экономических показателей, для анализа.
- Народный мониторинг – данные для любителей временных трендов. Если зарегистрироваться на портале, то можно выбрать любую любительскую точку мониторинга погоды и скачать данные о погоде в формате .csv. (без регистрации кнопка не доступна).

- Сайты поставщики данных спортивной статистики, например, у Sportradar есть пробный доступ к API. При желании можно найти кучу информации по разным видам спорта и национальным чемпионатам. От количества побед команды до количества мячей, которые футболист забил головой.
- Национальная электронная библиотека предоставляет данные по издательствам и научным статьям, сводки правда без привязки к датам, но помимо готовых сводок можно с помощью поиска самостоятельно собрать те или иные данные по публикационной активности.

Отчеты, аналитические записки и прочие данные для ручной обработки
На мой взгляд больше всего погрузится в процесс сбора данных помогает именно их получение в ручном режиме. Для этого не обязательно брать очень большой набор данных. В принципе источников для сбора данных великое множество.
Лично я начал с обращений граждан. Сейчас практически каждый орган исполнительной власти, в том или ином виде отчитывается за работу с обращениями граждан.
Я в свое время собрал данные мэрии Москвы. Мэрия предлагает нам данные о количестве обращений в бумажном и электронном форматах, количестве положительных и отрицательных решений и относительному количеству обращений по административным округам Москвы. Всю эту информацию с января 2016 по август 2020 я выложил на GitHub.
Вы можете попробовать обработать данные по другим городам, например по Санкт-Петербургу, Твери или Новосибирску.
Также интересные данные можно найти в отчетах по травматизму, например, в сфере энергетики (Ростехнадзор, Минэерго).
Часть III: Есть ли от этого польза?
На самом деле в силу малого опыта в анализе данных ответить на вопрос заголовка убедительно мне будет затруднительно. Может быть матерые специалисты скажут, что в создании своего набора данных смысла нет и это пустая трата времени.
Но вот, что полезного я вынес для себя в итоге:
- С точки зрения понимания принципов работы с популярными библиотеками данных на Python (или другом языке) собрать хоть один датасет своими руками будет познавательно. Особенно это полезно, когда в процессе возникают какие-нибудь ошибки в формате или наполнении файла.
- Пока ищешь или собираешь данные начинаешь постепенно планировать эксперимент, причем не один.
- Как правило неоткуда взять готовое решение или интерпретацию результатов. Полезно попытаться самому понять, что в итоге получилось даже если результаты вышли безумными и не имеют никакого практического применения. Особенно полезно понять, что сами по себе библиотеки и программы для машинного обучения чудес не делают и если данные плохие или сам анализ не продуман, то и результат будет так себе.
- В процессе сбора данных иногда можно найти явные ошибки, неточности и несоответствия. В упомянутом выше наборе про обращения граждан в мэрию Москвы, точно есть аномальные данные, которые выглядят как «копипаст», также были ошибки с указанием итоговых значений вместо фактических. Понимание, того, что все мы люди и можем ошибаться, помогает лучше понять проблемы и необходимость обработки реальных данных для машинного обучения.
- Полученные результаты можно разместить в общем доступе, вдруг они кому-нибудь однажды будут полезны.
Часть IV: Заключение
Подводя итог хочется призвать всех, кто только начал интересоваться машинным обучением и анализом данных попробовать создать своё «велосипед», причем не только датасеты но и программную часть, чтобы наука о данных не казалось вам магией.
Вот и закончилась статья, которую я не мог написать больше двух лет, но как говорится: «Лучше поздно чем никогда», прям на душе стало спокойно.
Желаю всем бодрого настроения и здоровья в эти нелегкие осенние месяцы.
Если кто-нибудь соберет свой интересный датасет или получит интересные результаты анализа собственных датасетов, пишите в комментарии.
UPD:
Статья на Хабре про источники с датасетами изображений от wadik69
Как создать набор данных для вашего проекта машинного обучения
Перевод
Ссылка на автора

Вы думаете об искусственном интеллекте для своей организации? Вы определили вариант использования с доказанным ROI? Отлично! но не так быстро … у вас есть набор данных?
Ну, большинство компаний изо всех сил пытаются создать набор данных, готовый к ИИ, или, возможно, просто игнорируют эту проблему, я подумал, что эта статья может вам немного помочь.
Давайте начнем с основ …
набор данныхэто коллекцияданные, Другими словами,набор данныхсоответствует содержимому одной таблицы базы данных или одной статистическойданныематрица, где каждый столбец таблицы представляет определенную переменную, и каждая строка соответствует данному членунабор данныхобсуждаемый.
В проектах машинного обучения нам нужно обучениенабор данных.Это фактнабор данныхиспользуется для обучения модели для выполнения различных действий.
Зачем мне нужен набор данных?
ML сильно зависит от данных, без данных «AI» не может учиться. Это самый важный аспект, который делает возможным обучение алгоритму… Независимо от того, насколько велика ваша команда AI или размер вашего набора данных, если ваш набор данных недостаточно хорош, весь ваш проект AI потерпит неудачу! Я видел, как фантастические проекты провалились, потому что у нас не было хорошего набора данных, несмотря на идеальный вариант использования и очень опытных ученых данных.
Контролируемый ИИ обучается на совокупности обучающих данных.
Во время разработки ИИ мы всегда полагаемся на данные. От обучения, настройки, выбора модели до тестирования, мы используем три различных набора данных: набор обучения, набор проверки и набор тестирования. Для вашей информации, наборы проверки используются для выбора и настройки окончательной модели ML.
Вы можете подумать, что сбора данных достаточно, но все наоборот. В каждом проекте ИИ классификация и маркировка наборов данных занимает большую часть нашего времени, особенно наборов данных, достаточно точных, чтобы отразить реалистичное видение рынка / мира.
Я хочу представить вам первые два набора данных, которые нам нужны — набор обучающих данных и набор тестовых данных, потому что они используются для различных целей во время вашего проекта ИИ, и от них во многом зависит успех проекта.
- набор обучающих данныхэто тот, который используется для обучения алгоритма, чтобы понять, как применять такие понятия, как нейронные сети, для обучения и получения результатов. Он включает в себя как входные данные, так и ожидаемый результат.
Учебные комплекты составляют большую часть общих данных, около 60%.При тестировании модели соответствуют параметрам в процессе, который известен как корректировка весов.
- набор тестовых данныхиспользуется для оценки того, насколько хорошо ваш алгоритм был обучен с набором обучающих данных. В проектах ИИ мы не можем использовать набор обучающих данных на этапе тестирования, потому что алгоритм уже будет заранее знать ожидаемый результат, который не является нашей целью.
Тестовые наборы представляют 20% данных. Испытательный набор должен быть входными данными, сгруппированными вместе с проверенными правильными выходными данными, как правило, путем проверки человеком
Исходя из моего опыта, попытка дальнейшей настройки после фазы тестирования является плохой идеей. Это может привести к переоснащению.

Что такое переоснащение?
Хорошо известная проблема для ученых-данных …переобученияэто ошибка моделирования, которая возникает, когда функция слишком близко подходит к ограниченному набору точек данных.
Сколько данных нужно?
Все проекты как-то уникальны, но я бы сказал, что вам нужно в 10 раз больше данных, чем количество параметров в создаваемой модели.Чем сложнее задача, тем больше нужно данных.
Какой тип данных мне нужен?
Я всегда начинаю проекты ИИ, задавая точные вопросы руководителю компании. Чего вы пытаетесь достичь с помощью ИИ? Основываясь на своем ответе, вы должны решить, какие данные вам действительно нужны для решения вопроса или проблемы, над которой вы работаете. Сделайте некоторые предположения о данных, которые вам требуются, и будьте осторожны, чтобы записать эти предположения, чтобы вы могли проверить их позже, если это необходимо.
Ниже приведены несколько вопросов, которые помогут вам:
- Какие данные вы можете использовать для этого проекта? Вы должны иметь четкое представление обо всем, что вы можете использовать.
- Какие данные не доступны, вы хотели бы иметь? Мне нравится этот вопрос, так как мы всегда можем каким-то образом смоделировать эти данные.
У меня есть набор данных, что теперь?
Не так быстро! Вы должны знать, что все наборы данных являются неточными. На данном этапе проекта нам необходимо подготовить некоторые данные, что является очень важным шагом в процессе машинного обучения. По сути, подготовка данных заключается в том, чтобы сделать ваш набор данных более подходящим для машинного обучения. Это набор процедур, которые занимают большую часть времени, затрачиваемого на проекты машинного обучения.
Даже если у вас есть данные, вы все равно можете столкнуться с проблемами их качества, а также с искажениями, скрытыми в ваших тренировочных наборах. Проще говоря, качество обучающих данных определяет производительность систем машинного обучения.
Вы слышали об уклонах от ИИ?
На ИИ можно легко влиять… За прошедшие годы ученые обнаружили, что некоторые популярные наборы данных, используемые для обучения распознаванию изображений, включают в себя гендерные предубеждения.
Как следствие, приложения ИИ строятся дольше, потому что мы пытаемся убедиться, что данные верны и правильно интегрированы.
Что делать, если у меня недостаточно данных?
Может случиться так, что вам не хватает данных, необходимых для интеграции решения ИИ. Я не буду лгать вам, потребуется время для создания набора данных, готовых к ИИ, если вы все еще полагаетесь на бумажные документы или.CSVфайлы. Я бы порекомендовал вам сначала уделить время созданию современной стратегии сбора данных.
Если вы уже определили цель своего решения по ОД, вы можете попросить вашу команду потратить время на создание данных или передать процесс на аутсорсинг. В моем последнем проекте компания хотела создать модель распознавания изображений, но не имела изображений. Как следствие, мы потратили недели на то, чтобы сделать снимки, чтобы собрать набор данных и выяснить, как будущие клиенты смогут сделать это за нас.
У вас есть стратегия данных?
Создание управляемой данными культуры в организации, пожалуй, самая сложная часть работы специалиста по искусственному интеллекту. Когда я пытаюсь объяснить, почему компании нужна культура данных, я вижу разочарование в глазах большинства сотрудников. Действительно, сбор данных может быть раздражающей задачей, которая обременяет ваших сотрудников. Тем не менее, мы можем автоматизировать большую часть процесса сбора данных!
Другой проблемой может быть доступность данных и владение ими. Во многих моих проектах я заметил, что у моих клиентов достаточно данных, но данные заблокированы и труднодоступны. Вы должны создать связи между хранилищами данных в вашей организации. Чтобы получить особую информацию, вы должны собрать данные из нескольких источников.
Что касается владения, то соответствие также является проблемой с источниками данных — просто потому, что компания имеет доступ к информации, это не означает, что она имеет право использовать ее! Не стесняйтесь спрашивать свою юридическую команду об этом (GDPR в Европе является одним из примеров).
Качество, объем и количество!
Машинное обучение — это не только большой набор данных. На самом деле, вы не снабжаете систему всеми известными точками данных в любой смежной области. Мы хотим снабдить систему тщательно отобранными данными, надеясь, что она сможет изучить и, возможно, расширить на полях знания, которые уже есть у людей.
Большинство компаний считают, что достаточно собрать все возможные данные, объединить их и позволить ИИ найти понимание.
При создании набора данных вы должны стремиться к разнообразию данных. Я всегда рекомендую компаниям собирать как внутренние, так и внешние данные. Цель состоит в том, чтобы создать уникальный набор данных, который вашим конкурентам будет сложно скопировать. Приложения машинного обучения требуют большого количества точек данных, но это не означает, что модель должна учитывать широкий спектр функций.
Мы хотим значимых данных, связанных с проектом.Вы можете располагать подробными подробными данными по теме, которая просто не очень полезна. Эксперт ИИ задаст вам точные вопросы о том, какие поля действительно имеют значение, и как эти поля, вероятно, будут иметь значение для вашего применения полученных вами знаний.
В моей последней миссии я должен был помочь компании создать модель распознавания изображений для целей маркетинга. Идея заключалась в том, чтобы построить и подтвердить доказательство концепции. У этой компании не было данных, кроме некоторых 3D-рендеров их продуктов. Мы хотели, чтобы ИИ распознал продукт, прочитал упаковку, определил, подходит ли он для клиента, и помог им понять, как его использовать.
Наш набор данных состоял из 15 продуктов, и для каждого из нас было 200 изображений. Это число оправдано тем фактом, что это был еще прототип, в противном случае мне понадобилось бы гораздо больше изображений! Это предполагает, что вы используете методы обучения передаче.
Когда дело доходит до фотографий, нам нужны разные фоны, условия освещения, ракурсы и т. Д.
Каждый день я выбирал 20 картинок случайным образом из тренировочного набора и анализировал их. Это дало бы мне хорошее представление о том, насколько разнообразным и точным был набор данных.
Каждый раз, когда я делал это, я обнаруживал что-то важное в отношении наших данных. Это может быть несбалансированное количество картинок с одинаковым углом, неправильные метки и т. Д.
Хорошей идеей было бы начать с модели, которая была предварительно обучена на большом существующем наборе данных, и использовать трансферное обучение, чтобы уточнить ее с вашим меньшим набором данных, который вы собрали.
Предварительная обработка данных
Хорошо, давайте вернемся к нашему набору данных. На этом этапе вы собрали свои данные, которые вы считаете важными, разнообразными и репрезентативными для вашего проекта ИИ. Предварительная обработка включает в себя выбор правильных данных из полного набора данных и построение обучающего набора. Процесс объединения данных в этом оптимальном формате известен какпреобразование функций,
- Формат:Данные могут распространяться в разных файлах Например, результаты продаж из разных стран с разной валютой, языками и т. Д., Которые необходимо собрать для формирования набора данных.
- Очистка данных:На этом этапе наша цель — устранить пропущенные значения и удалить ненужные символы из данных.
- Функция извлечения:На этом этапе мы сосредоточены на анализе и оптимизации ряда функций. Обычно член команды должен выяснить, какие функции важны для прогнозирования, и выбрать их для более быстрых вычислений и низкого потребления памяти.

Идеальная стратегия данных
Наиболее успешными проектами ИИ являются те, которые интегрируют стратегию сбора данных во время жизненного цикла услуги / продукта. Действительно, сбор данных не может быть серией одноразовых упражнений. Он должен быть встроен в основной продукт. По сути, каждый раз, когда пользователь использует ваш продукт / услугу, вы хотите собирать данные о взаимодействии. Цель состоит в том, чтобы использовать этот постоянный новый поток данных для улучшения вашего продукта / услуги.
Когда вы достигаете такого уровня использования данных, каждый новый добавляемый вами клиент увеличивает набор данных и, следовательно, продукт лучше, что привлекает больше клиентов, что делает набор данных лучше и так далее. Это какой-то положительный круг.

Лучшими и долгосрочными проектами ML являются те, которые используют динамические, постоянно обновляемые наборы данных. Преимущество построения такой стратегии сбора данных состоит в том, что вашим конкурентам становится очень трудно реплицировать ваш набор данных. С данными ИИ становится лучше, а в некоторых случаях, например, с помощью совместной фильтрации, это очень ценно. Совместная фильтрация делает предложения, основанные на сходстве между пользователями, она улучшится с доступом к большему количеству данных; чем больше пользовательских данных, тем больше вероятность того, что алгоритм сможет найти похожего пользователя.
Это означает, что вам нужна стратегия для постоянного улучшения вашего набора данных до тех пор, пока пользователь получит выгоду от повышения точности модели. Если вы можете, найдите творческие способы использовать даже слабые сигналы для доступа к большим наборам данных.
Еще раз, позвольте мне использовать пример модели распознавания изображений. Исходя из моего прошлого опыта, мы придумали и разработали способ, позволяющий пользователям фотографировать нашу продукцию и отправлять ее нам. Эти картинки затем будут использоваться для питания нашей системы искусственного интеллекта и со временем сделать нашу систему умнее.
Другой подход заключается в повышении эффективности вашего конвейера меток, например, мы привыкли полагаться на систему, которая могла бы предлагать метки, предсказанные начальной версией модели, чтобы этикетировщики могли принимать более быстрые решения.
Наконец, я видел, как компании просто нанимали больше людей для маркировки новых материалов для обучения … Это требует времени и денег, но это работает, хотя это может быть затруднительно в организациях, которые традиционно не имеют статьи в своем бюджете для такого рода расходов.
Несмотря на то, что говорят большинство компаний SaaS, машинное обучение требует времени и подготовки. Всякий раз, когда вы слышите термин AI, вы должны думать о данных, стоящих за ним. Я надеюсь, что эта статья поможет вам понять ключевую роль данных в проектах ML и убедит вас уделить время размышлению о вашей стратегии обработки данных.
Время прочтения: 5 мин.
Используем Numpy
Установим необходимые пакеты:
pip install numpy pandas matplotlibСоздадим случайный набор данных, имеющих нормальное распределение. Надо отметить, что в теории вероятностей нормальное распределение – это весьма распространенное, непрерывное распределение вероятностей, симметричное относительно среднего. Оно показывает, что данные, близкие к среднему, встречаются чаще, чем данные, далекие от среднего. Нормальные распределения используются в статистике для представления случайных величин с действительными значениями. Например, данные роста, артериального давления, IQ подчиняются нормальному распределению.
В приведенном ниже коде создадим случайный набор данных:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# инициализируем параметры для нормального распределения:
# определение среднего
mu = 0.5
# определение стандартного отклонения
sigma = 0.1
# random использует начальное значение в качестве основы
# для генерации случайного числа.
np.random.seed(0)
# определим координаты x
X = np.random.normal(mu, sigma, (546, 1))
# определим координаты y
Y = np.random.normal(mu * 2, sigma * 3, (546, 1))
# строим граф
plt.scatter(X, Y, color = 'r')
plt.show()
Вывод графа:

Теперь создадим немного другой набор данных, включающих 3 столбца, которые представляют функцию в наборе данных и еще один 4-й столбец – метки вывода, значения которых меняются в пределах от 0 до 3. Созданный таким способом набор данных можно использовать для обучения, к примеру, классификатора логистической регрессии или классификатора нейронной сети.
import numpy as np
import pandas as pd
import math
import random
import matplotlib.pyplot as plt
# определение столбцов с использованием нормального распределения
# столбец1
point1 = abs(np.random.normal(1, 15, 50))
# столбец2
point2 = abs(np.random.normal(2, 10, 50))
# столбец3
point3 = abs(np.random.normal(3, 4, 50))
# x содержит функции датасета
x = np.c_[point1, point2, point3]
# метки вывода варьируются от 0 до 3
y = [int(np.random.randint(0, 3)) for i in range(50)]
# определяем DataFrame для последующего использования
data = pd.DataFrame()
# определяем столбцы датасета
data['col1'] = point1
data['col2'] = point2
data['col3'] = point3
# построение функций (x) по меткам (y)
plt.subplot(2, 2, 1)
plt.title('col1')
plt.scatter(y, point1, color ='r', label ='col1')
plt.subplot(2, 2, 2)
plt.title('Col2')
plt.scatter(y, point2, color = 'g', label ='col2')
plt.subplot(2, 2, 3)
plt.title('Col3')
plt.scatter(y, point3, color ='b', label ='col3')
# сохраняем граф
plt.savefig('dataset.jpg')
# отображение графа
plt.show()
Результат вывода графа:

Используем Sklearn
Sklearn имеет генератор образцов наборов данных. Процесс создания датасета несложный и быстрый. Далее приведу примеры того, как это сделать. Импортируем необходимые библиотеки:
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from matplotlib import style
Генерирование изотропных Гауссовских капель для кластеризации с помощью функции make_blobs ()
Датасет подходит для задач линейной классификации с учетом линейно разделяемой природы двоичных объектов.
# Создаем тестовый датасет с использованием make_blobs
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_blobs(n_samples = 300, centers = 3,
cluster_std = 1, n_features = 2)
plt.scatter(X[:, 0], X[:, 1], s = 40, color = 'b')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
Вывод результата:

Генерирование датасета для задачи двоичной классификации с помощью функции make_moons ()
Этот тестовый датасет подходит для алгоритмов, изучающих нелинейные границы классов.
# Создаем тестовый датасет с использованием make_moon
from sklearn.datasets import make_moons
from matplotlib import pyplot as plt
from matplotlib import style
X, y = make_moons(n_samples = 500, noise = 0.1)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='r')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf
Вывод результата:

Генерирование датасета для задачи двоичной классификации с помощью функции make_circles ()
Этот датасет подходит для алгоритмов, изучающих сложные нелинейные многообразия.
# Создаем тестовый датасет с использованием make_circles
from sklearn.datasets import make_circles
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_circles(n_samples = 50, noise = 0.02)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Вывод:

В приведенных примерах с использованием Numpy и Sklearn показаны способы создания случайных наборов данных. И несмотря на то, что такие датасеты не могут учесть всех особенностей реального набора данных, они хорошо контролируемы, чтобы быть использованными для обучения и исследования сильных и слабых качеств вашей модели.
Для начала загрузим датасет:
from sklearn import datasets
data = datasets.load_diabetes(as_frame=True)
dataset = data.frame
Создать тестовый набор очень просто, нужно произвольно выбрать 20% образцов и отложить их:
import numpy
def split_test_train (dataset, test_size):
shuffled_indx = numpy.random.permutation(len(dataset))
test_set_size = int(len(dataset) * test_size)
train_indx = shuffled_indx[test_set_size:]
test_indx = shuffled_indx[:test_set_size]
return dataset.iloc[test_indx], dataset.iloc[train_indx]
Теперь для того чтобы разделить набор данных, требуется вызвать функцию split_test_train():
test_set, train_set = split_test_train(dataset, 0.2)
Все работает, но еще далеко от совершенства. При каждом запуске программы будут получаться разные тестовые наборы. Чтобы этого избежать можно сохранить тестовый набор и использовать его при последующих запусках или установить начальное значение генератора случайных чисел:
import numpy
def split_test_train (dataset, test_size):
numpy.random.seed(42)
shuffled_indx = numpy.random.permutation(len(dataset))
test_set_size = int(len(dataset) * test_size)
train_indx = shuffled_indx[test_set_size:]
test_indx = shuffled_indx[:test_set_size]
return dataset.iloc[test_indx], dataset.iloc[train_indx]
Данный метод имеет реализацию в модуле Scikit-Learn — функция train_test_split(). Функция train_test_split() имеет дополнительную особенность, в нее можно передавать несколько наборов данных с одинаковым количеством строк и она разобьет их по тем же самым индексам. Это удобно при наличии отдельного набора для меток. Пример использования train_test_split():
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(dataset, test_size=0.2, random_state=42)
До этого момента мы рассматривали случайные методы выборки. Они неплохи для больших наборов данных, однако если это не так, испытательный набор может оказаться смещенным, что приведет к неверной оценке работы модели. Чтобы этого не допустить используются стратифицированные выборки.
Выборка делится на однородные подгруппы (страты) и из каждой страты выбирается правильное количество образцов для обеспечения репрезентативности испытательного набора. В Scikit-Learn представлен класс StratifiedShuffleSplit.
Например, разделим dataset на train и test выборки, сохранив баланс возрастных страт. Сперва создадим столбец «age_cat», содержащий 5 возрастных страт:
dataset[«age_cat»] = numpy.around(dataset[«age»]/5, 2)
dataset[«age_cat»].hist()
Теперь разделим датасет с использованием столбца «age_cat»:
from sklearn.model_selection import StratifiedShuffleSplit
shuffle_split = StratifiedShuffleSplit(n_splits=1, test_size=0.2,random_state=42)
for train_indx, test_indx in shuffle_split.split(dataset, dataset[«age_cat»]):
train_set = dataset.loc[train_indx]
test_set = dataset.loc[test_indx]
Проверим, работает ли код ожидаемым образом. Для этого рассчитаем пропорции страт в каждом наборе данных и сравним процент ошибок.
Здесь видно, что испытательный набор, сгенерированный с использованием стратифицированной выборки имеет пропорции страт близкие к пропорциям в полном наборе данных. Чего нельзя сказать о выборке полученной случайным методом.
И последний совет: после того как разделите набор данных на тестовый и обучающий, отложите тестовый и не заглядывайте в него! Иначе ваш мозг обнаружит паттерны в наборе, и исходя из них вы подберете определенный тип модели МО. В итоге вы получите более оптимистичную оценку качества вашей модели, и на реальных данных она будет работать не настолько хорошо, как вы ожидали.
Сформировав набор открытых данных и структуру набора открытых данных в программе для работы с электронными таблицами Excel (xlsx), программно будут сгенерированы все необходимые файлы во всех машиночитаемых форматах (csv,json,xml).
Для публикации (передачи для публикации) данных в формате Excel, необходимо чтобы таблица была в простом, плоском формате (Рис. 1).
В упрощенном виде плоская таблица — это таблица, каждая ячейка которой может быть однозначно идентифицирована указанием строки и столбца таблицы. Кроме того, в одном столбце все ячейки должны содержать данные одного простого типа.
Файл набора данных
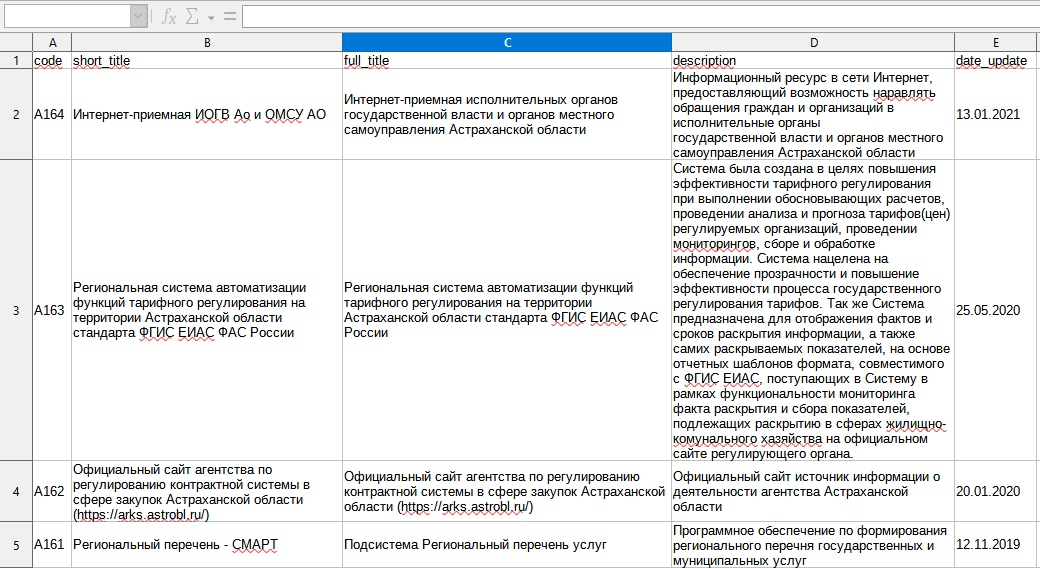
Рис. 1 Пример таблицы набора данных в Excel
Первая строка в таблице набора данных должна состоять из названий полей набора данных. Названия должны иметь краткое англоязычное представление (в виде англоязычных имен или краткого текста транслитерации) (Рис. 2).

Рис. 2 Пример первой строки (заголовка) таблицы набора открытых данных в Excel
Старайтесь избегать следующих ситуаций при создании таблицы:
-
Пустая строка в середине таблицы набора данных (Риc. 3). (Отдельные пустые поля допустимы (Рис. 4))
Рис. 3 Пустая строка
Рис. 4 Пустое поле
-
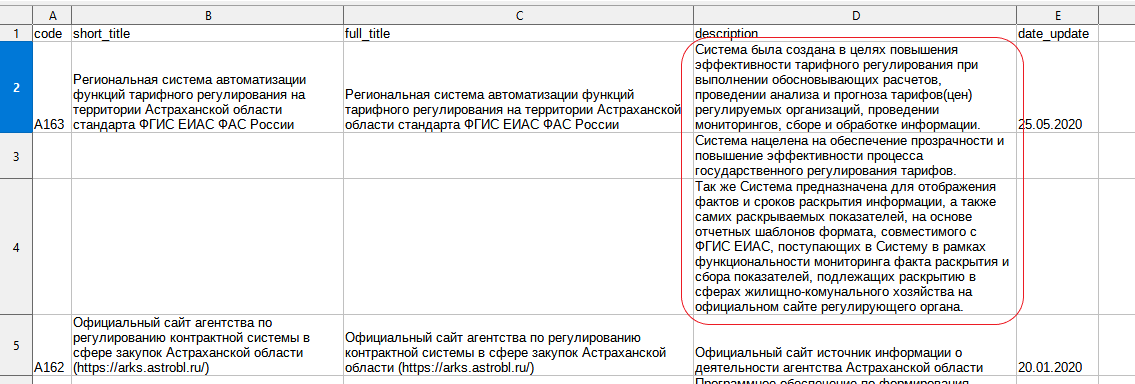
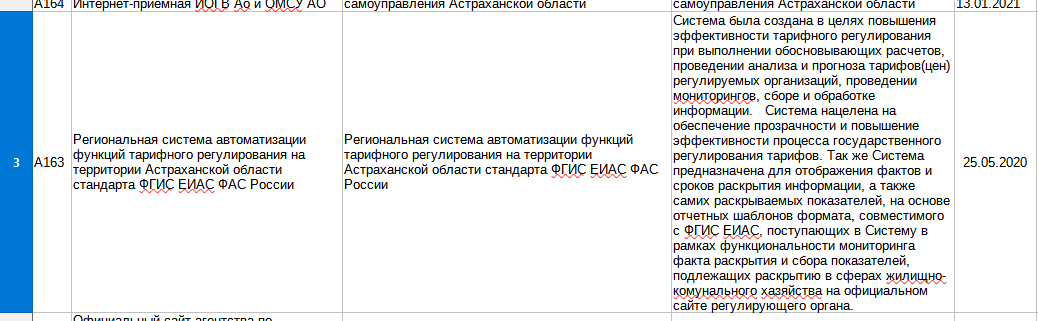
Содержимое одного поля набора данных размещенное в нескольких ячейках (Рис. 5.1, 6.1.1, 6.1.2). (Правильно надо сделать так (Рис 5.2 и Рис. 6.2))
Рис. 5.1 Содержимое размещенное в нескольких ячейках
Рис 6.1.1
Рис 6.1.2
Рис. 6.2




Файл структуры набора данных
Структура наборов открытых данных должна представлять описание каждого информационного поля (столбца) открытых данных (Рис. 7).

Рис. 7 Пример таблицы набора данных в Excel
Таблица структуры набора данных должна состоять из следующих столбцов (Рис. 8):
- field_name;
- english description;
- russian description;
- format.

Рис. 8 Заголовок таблицы структуры набора данных
Значением столбца field_name является наименование поля набора открытых данных (Рис. 9).
Рис. 9 Пример столбца field_name
Значением столбца english description является подробное описание поля набора открытых данных на английском языке (Рис. 10).
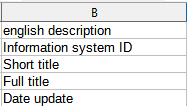
Рис. 10 Пример столбца english_description
Значением столбца russian description является подробное описание поля набора открытых данных на русском языке (Рис. 11).
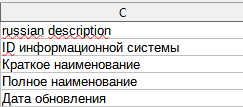
Рис. 11 Пример столбца russian_description
Значением столбца format является формат поля набора открытых данных на английском языке (Рис. 12). Возможные значения столбца format:
- string (текст состоящий из буквенных символов, знаков препинания и цифр);
- integer (целое число);
- float (дробное число);
- date (дата).

Рис. 12 Пример столбца format