Зеркалом сайта называют его копию с таким же контентом, но доступную по другому или другим адресам.
Поисковые системы стремятся сделать выдачу честной, поэтому Яндекс и Google делят зеркала на 2 типа: главное и неглавное (второстепенное). Первое отображается в результатах поиска, а второе физически может быть доступно, но в поиске не участвует.
Поэтому важно найти зеркало сайта и проверить каждое из них на корректность настройки.
Какие бывают зеркала сайта?
|
Описание |
Пример |
|
Cайт доступен по адресам с www и без www |
www.example.com и example.com |
|
Сайт доступен по протоколам http и https |
http://example.com и https://example.com |
|
Сайт находится в разных доменных зонах |
example.com и example.ru |
|
Одинаковый контент отображается на разных доменах |
example.com и other-example.ru |
Почему важно указать главное зеркало сайта?
Вся накопленная статистика (внешние и поведенческие факторы) присваивается главному зеркалу.
Если поисковый робот не увидит правил, то он выберет его самостоятельно.
В конечном итоге, такая ошибка может отрицательно сказаться на позициях и трафике вашего сайта.
Как найти зеркала сайта?
Чтобы найти зеркала сайта онлайн, воспользуйтесь инструментом «Поиск зеркал для домена».
Укажите домен сайта или конкурента:

В результате вы увидите все найденные в индексе адреса и коды ответа:

Как настроить главное зеркало сайта?
Если при попытке найти зеркало сайта вы увидели несколько адресов, проверьте их по инструкции:
-
Добавьте сайт в панель Яндекс.Вебмастера. Подтвердите права. В разделе «Индексирование — Переезд сайта» отметьте верный вариант его отображения в Яндексе. Сохраните настройки.
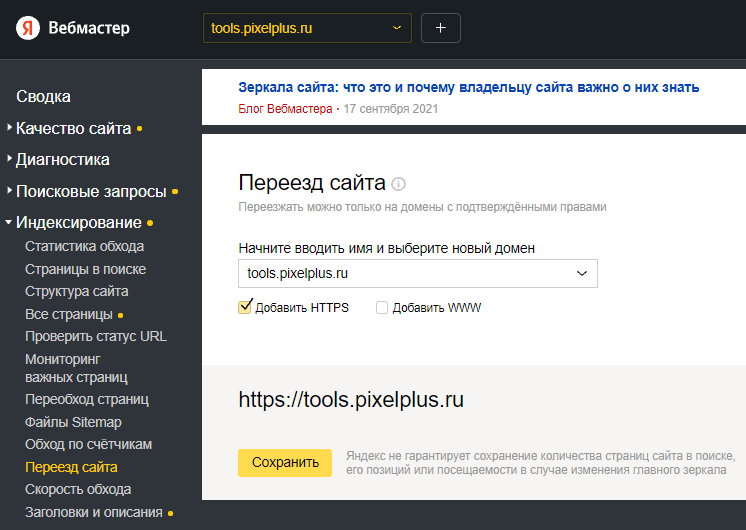
-
Добавьте сайт в панель Google Search Console. Подтвердите права. В разделе «Настройки сайта» отметьте верный вариант его отображения в Google. Сохраните настройки.
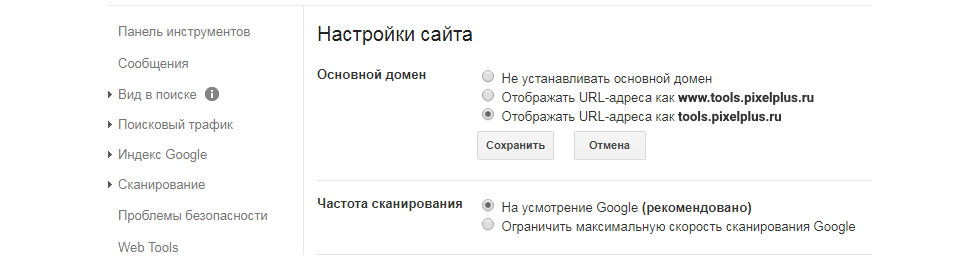
-
Настройте 301-е редиректы в файле .htaccess.
Перенаправление на домен с https:
RewriteCond %{SERVER_PORT} !^443$
RewriteRule .* https://%{SERVER_NAME}%{REQUEST_URI} [R=301,L]Перенаправление на домен без www:
RewriteCond %{HTTP_HOST} ^www.site.ru
RewriteRule ^(.*) https://site.ru/$1 [R=301,L]Перенаправление на домен с www:
RewriteCond %{HTTP_HOST} ^site.ru
RewriteRule (.*) https://www.site.ru/$1 [R=301,L]Перенаправление с одного домена на другой:
RewriteCond %{HTTP_HOST} old-site.ru
RewriteRule (.*) https://new-site.ru/$1 [R=301,L]
Когда всё это проделано, будьте уверены, что поисковые роботы и пользователи смогут найти ваш сайт по нужному адресу.
Стоимость проверки зеркал сайта
Стоимость одной проверки 25 лимитов, в том числе через API (от 54 копеек).
Инструмент доступен на всех PRO-тарифах: «Профессионал», «Гуру» и «Бизнес».
Ознакомьтесь с их ценами в таблице по ссылке.
Если у вас есть идеи, как улучшить SEO-инструмент или остались вопросы по работе с ним, напишите в нашу службу поддержки, мы обязательно вам поможем.
Вопросы и ответы
Что такое зеркало сайта?
Зеркала сайта — это сайты с одинаковым контентом, доступные по разным адресам. Например, на разных доменах или с www и без. В поиске участвует только главное зеркало.
Как найти все зеркала сайта?
Чтобы узнать, является ли сайт неглавным зеркалом другого сайта, добавьте его в Search Console Google и Яндекс.Вебмастер. Зеркала любого сайта можно узнать с помощью удобного сервиса Пиксель Тулс «Поиск зеркал для домена».
Сегодня расскажу подробнее о поиске зеркал сайтов (полных копий на разных доменах). Тема вызвала живой интерес и множество вопросов после доклада на SEMPRO.
Зачем вообще искать зеркала?
Напомню ситуации, когда это может быть актуально:
- Вы анализируете новую нишу на предмет конкуренции. Если ТОП выдачи выглядит не особо внушительно – не спешите радоваться. Сначала стоит проверить, не подклеено ли к молодому домену старое зеркало с мощным ссылочным профилем.
- Вы планируете купить сайт, который имеет хороший поисковый трафик. Обязательно требуйте передачи прав на все зеркала – иначе можно остаться ни с чем.
- Вас интересует схема ссылочного продвижения у конкретного конкурента. Стоит тщательно изучить обратные ссылки у всех версий проекта.
- Вы пользуетесь услугами SEO-студии или фрилансера; хотите быть уверены, что продвижение ведется именно для вашего домена.
Как найти зеркала с точки зрения Яндекса?
В Рунете популярен плагин для браузера RDS бар и онлайн-сервис recipdonor, который проверяет множество SEO-параметров, в том числе и этот (в платной версии). Создатели плагина подробно описали свою методику:
Склеен ли сайт на какой-то другой можно определить используя эти два запроса:
http://search.yaca.yandex.ru/yca/cy/ch/site.ru/ или http://bar-navig.yandex.ru/u?ver=2&u…ndex.ru&show=1Если какое-то из этих значений возвращает склейку, то этот сайт попадает к нам в базу.
Определить склеен ли сайт – очень просто. А вот узнать какие сайты приклеены к данному, то есть произвести обратную процедуру – довольно сложная задача.
Для этого “в идеале” нужно проанализировать все сайты интернета на эти два запроса проверки склейки и создать связки для склееных сайтов.
Что позволит найти все зеркала сайта, если они действительно приклеены к данному сайту.В нашей базе более 13 млн. сайта, которые регулярно проверяются на данные параметры.
Из статистики, найдено:
406 000 сайтов склееных на другие
280 000 сайтов у которых есть дополнительные зеркала.
И оговорились:
Внимание: сервис определяет зеркала для сайтов, которые Яндекс признал действительно зеркалами и склеил их.
Определение зеркал по Google или по другим признакам (у которых в robots.txt прописано или стоит редирект, или на сайте просто надпись сайт переехал) – это другая история.
Источник: http://searchengines.guru/showthread.php?t=539779
Очевидно также, что мы не можем быть уверены в полноте любой базы. Что, если работаем с узкой нишей, где не особо популярные сайты? Да еще под англоязычный Google? На самом деле это не проблема. Гугл – знает все!
Как искать зеркала под Google?
Наверняка вы замечали, что Google хранит информацию о старых страницах очень долго. Для примера – отчет из API Search Console для моего сайта:
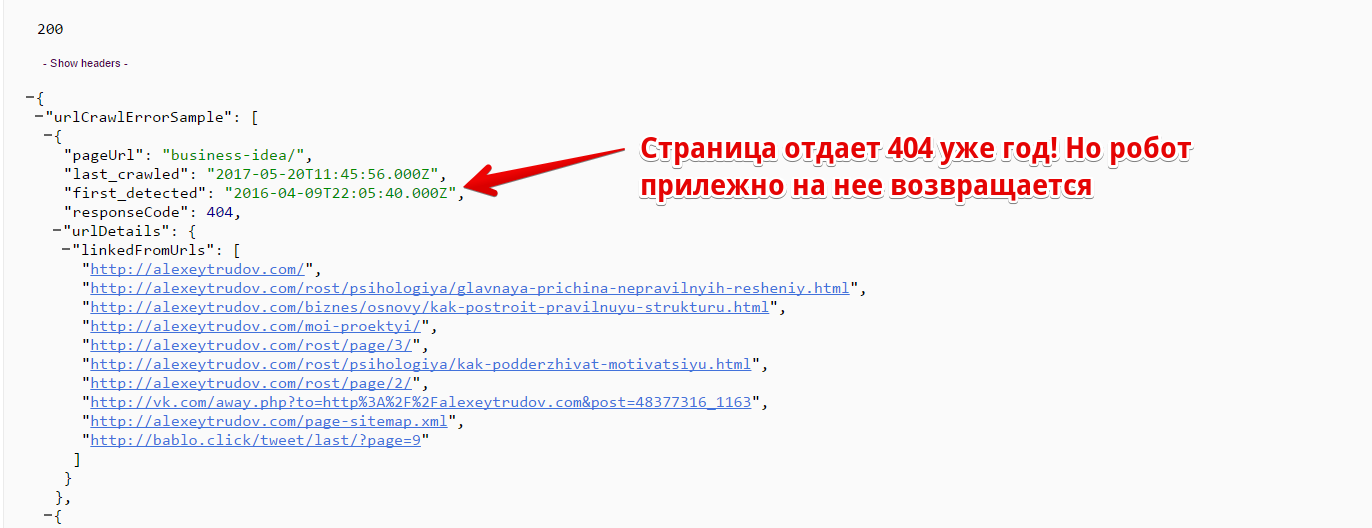
На этом и основан метод:
Запрашиваем у Google уникальную фразу с анализируемого сайта, одновременно запрещаем показывать сам сайт.
Вот пример из доклада (искал зеркала у сайта www.injuryclaimcoach.com):
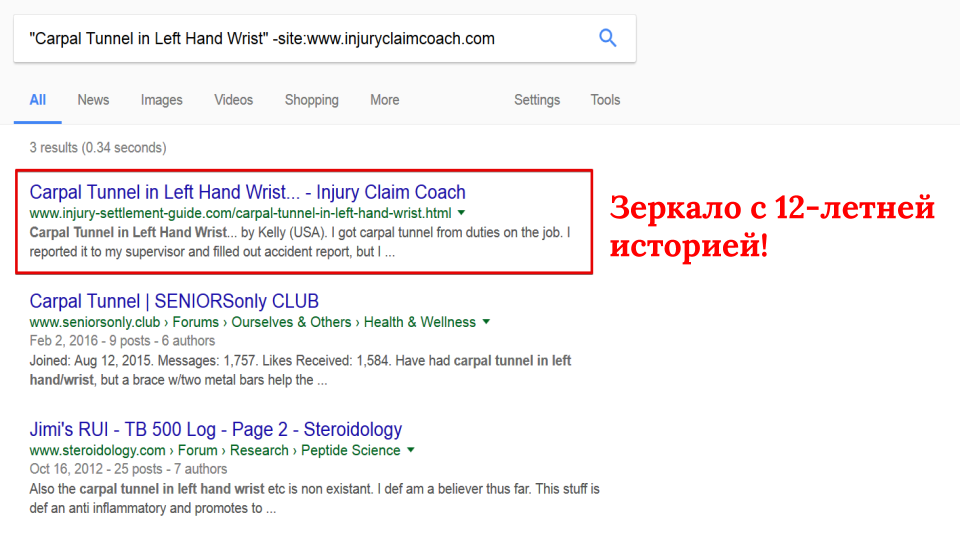
Используется фраза в кавычках и оператор site:, перед которым стоит минус. Первый результат отдает 301 код и перебрасывает на изучаемый домен. При этом переезд был осуществлен более 3 лет назад (особо любознательные могут проверить по web.archive).
Пример использования
Давайте поищем еще. Возьмем интересный пример. Возможно вы в курсе, что Гугл на своем сервисе blogspot.com однажды устроил знатную свистопляску с зеркалами.
Так, блог Дмитрия Шахова из России открывается по адресу http://bablorub.blogspot.ru/. Если обратитесь к нему через .com – получите редирект.
Но в выдаче тем не менее .com:

Применим нашу методику:
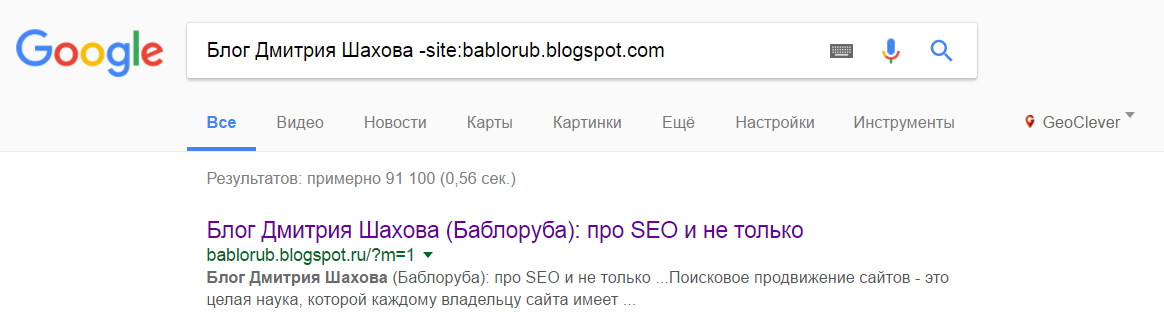
“Рушка” нашлась! Не будем на этом останавливаться. Выше я подчеркивал, что нужно использовать уникальную фразу.
Забиваем “Я считаю, что глупо тиранить кандидата вопросами про то, что такое релевантность или формула BM-25 -site:bablorub.blogspot.com” (цитата из статьи про прием сеошника на работу):
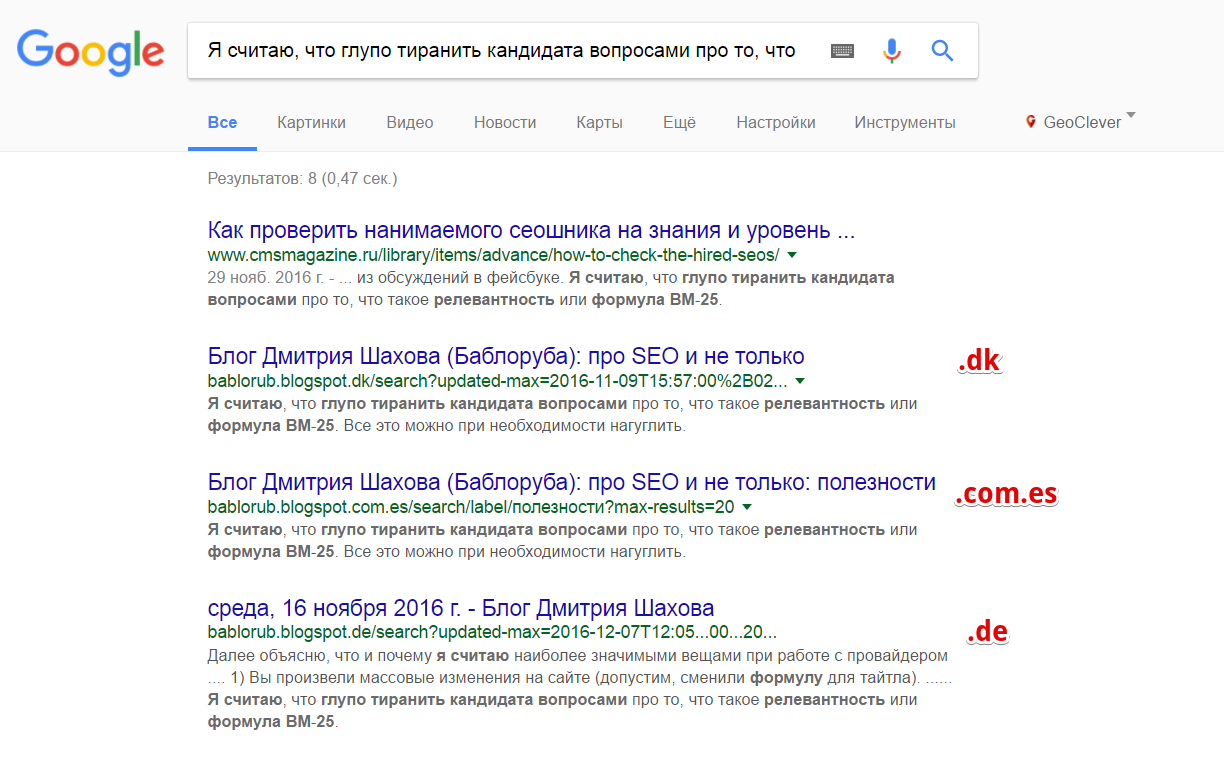
Ничего такой улов!
Но фразу мы взяли не то чтобы слишком удачно – она в популярной статье, которая была много где процитирована или перепечатана.
Берем другую, – ответ Дмитрия на мой вопрос из тех времен когда мы еще не были знакомы лично:
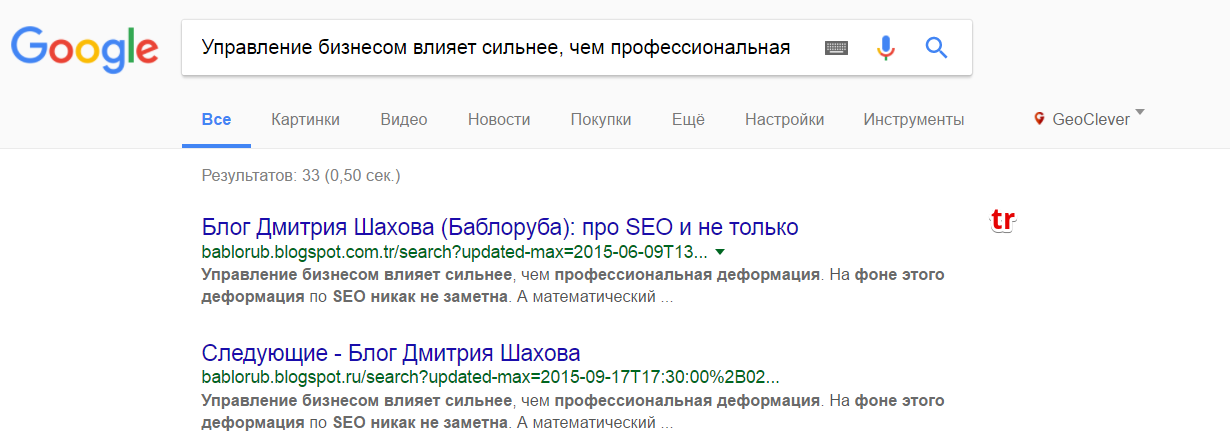
Еще один! Но заодно подсунут и .ru тоже. Заминусуем и его и .tr! Используем длинный запрос: Управление бизнесом влияет сильнее, чем профессиональная деформация. На фоне этого деформация по SEO никак не заметна. -site:bablorub.blogspot.com -site:bablorub.blogspot.ru -site:bablorub.blogspot.tr
Интересно, кончились ли у Гугла зеркала?
Как бы не так!

Забиваем теперь “Управление бизнесом влияет сильнее, чем профессиональная деформация. На фоне этого деформация по SEO никак не заметна. -site:bablorub.blogspot.com -site:bablorub.blogspot.ru -site:bablorub.blogspot.tr -site:bablorub.blogspot.com.tr -site:bablorub.blogspot.com.es -site:bablorub.blogspot.de -site:bablorub.blogspot.dk” (я уже устал…)
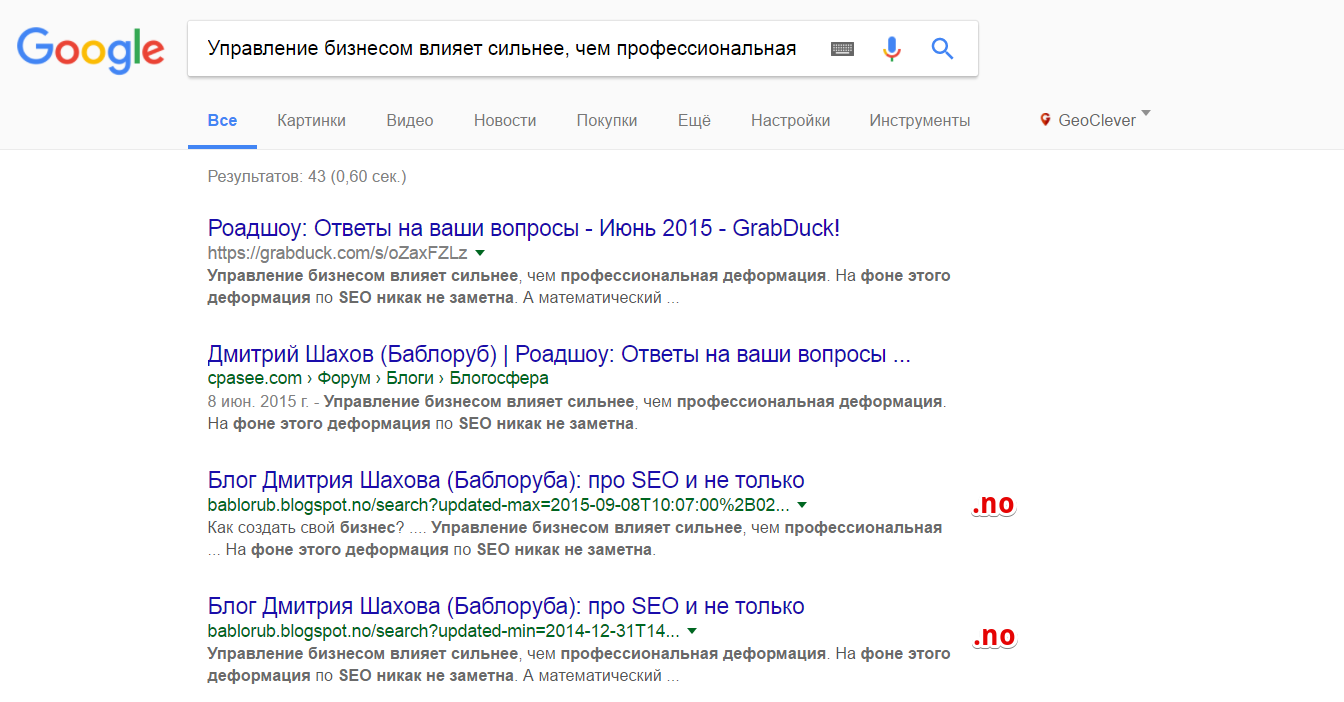
Тут я сдался. Доменов у Гугла много куплено, это мы точно выяснили. Желающие могут найти еще и еще.
Практические советы и тонкости
- Стоит использовать не только -site:, но и -inurl:. Иногда это предпочтительнее. Контент бывает растиражирован по разным каталогам сайтов; в адрес таких страниц обычно входит часть домена. Поэтому чтобы не тонуть в них, минусуем не весь домен, а его часть. Тогда если и будут всплывать каталоги, то скорее ссылающиеся на старое зеркало.
- Нужно делать несколько проверок с разными фразами. Желательно брать запросы из старого контента (можно проверять по вебархиву).
- Гугл спокойно переваривает длинные поисковые фразы, где минусуется сразу несколько доменов. Пользуемся этим, чтобы не натыкаться на уже обнаруженные зеркала.
- Один и тот же запрос стоит задавать с фразой в кавычках и без, а затем проверять скрытые результаты. Выдача может сильно отличаться и содержать разные домены.
- Разумеется, мы не можем быть уверены, что найдем абсолютно все зеркала. Но на практике метод работает неплохо. Смотрите пример в комментариях. С помощью одного запроса выявлено сразу 2 зеркала, при том что сервисы находят ноль (лень постить скриншоты, можете проверить сами). Спасибо Ивану за показательный пример.
Удачного использования!
!
Будет использованнолимит(ов)
Поиск зеркал сайта
Мы разработали инструмент для того, чтобы можно было найти зеркало сайта. Данный этап проверки является одним из важнейших при работах по оптимизации сайта, так как работающие зеркала могут создать определенные проблемы. Поэтому, крайне важно определить дубли и настроить для них 301-редирект.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Продолжаем тему продвижения сайтов методами SEO оптимизации, начатую в статье про аудит юзабилити сайта. Чуть раньше мы рассмотрели все способы продвижения коммерческих сайтов и в общих чертах познакомились с работой поисковых систем. Сегодня у нас на повестке дня вопрос взаимодействия поисковых систем и сайта.

В предыдущей статье мы говорили про индексацию сайта поисковыми роботами и влияние этого процесса на общий успех продвижения. Следовательно, одной из задач продвижения для нас будет создание условий, при которых поисковые индексаторы будут посещать страницы нашего сайта с завидной регулярностью, чтобы новый контент быстро попадал в индекс, а затем и поисковую выдачу (читайте подробнее про SEO терминологию, используемую в данной статье).
Для решения этой задачи необходимо понимание принципов взаимодействия поисковых ботов и вебстраниц нашего или какого-либо другого сайта в интернете (что привлекает ботов, а что, наоборот, отвращает от индексации вебстраниц). В сегодняшней и последующей статье речь пойдет про протокол Http, Урл адреса, зеркала, дубли страниц и прочие вещи, так или иначе с этим связанные.
P.S. Как бы я не хотел, но всего необходимого в одну (или даже несколько публикаций) не впихнешь (а дьявол, как говорится, кроется в деталях). В общем, есть вариант пройти онлайн-обучение по теме «SEO 2.0 от TexTerra«. Все же, за это время рассказать можно, наверное, все. Но это платно, само собой.
URL адреса и зеркала — их влияние на успех продвижения
Что такое URL адреса я уже довольно подробно расписывал, но чтобы не заставлять вас постоянно переходить из одной статьи в другую, здесь я частично повторюсь. Урл представляет из себя адрес вебстраницы (документа) в сети интернет. Записывается он в определенном формате, доступном пониманию DNS (серверам доменных имен).
Если брать исходную схему формирования Урл адреса, то выглядит она пугающе:
![]()
Однако, логин и пароль при обращении к вебстраницам используется, наверное, крайне редко (это больше свойственно схеме или протоколу FTP). Поэтому проще будет рассмотреть реальный пример Урла:
https://ktonanovenkogo.ru/papka/failik.html
В данном случае это адрес не существующей на моем блоге странички с названием ее файла failik.html (этот файлик может физически находиться на моем сервере в папке papka, либо он может на лету генерироваться CMS при запросе этой страницы — читайте про принципы работы CMS).
Все, что в URL написано после третьего слеша слева (включая и его тоже — /papka/failik.html), является относительным (внутренним) адресом местоположения документа (относительно корневой папки сервера). Более подробно про абсолютные и относительные адреса читайте по приведенной ссылке. Папки, так же как и файлы, могут существовать физически на сервере, а могут быть и виртуальными (их генерирует CMS, подразумевая под папками разделы и категории — читайте про ЧПУ в WordPress и SEF в Joomla).
Для простоты предположим, что в нашем примере имеется физический файлик и физическая папка papka, которая в свою очередь находится в корневой директории сайта. Однако, не понятно, как DNS сервера смогут понять, на каком именно из многих миллионов серверов искать данный файлик и папку. Тут как раз важна та часть URL адреса, которая содержит в себе название хоста (что это такое?). Она заключена между вторым и третьим слешем слева и в моем случае представляет из себя „ktonanovenkogo.ru“.
Кстати, возможны еще варианты, когда название хоста и домена не совпадут. Например, если бы у меня главное зеркало было бы выбрано как „www.ktonanovenkogo.ru“, то это было бы названием хоста, в то время как домен по-прежнему был бы — ktonanovenkogo.ru. Но это нюансы. Вернувшись к Урл адресу, мы еще отметим, что буковки, стоящие перед двойным слешем, являют собой обозначение схемы или, другими словами, протокола, по которому должно осуществляться подключение.
Протокол определяет способ взаимодействия браузера (или другой программы-клиента, например, FTP менеджера Файлзилла) и сервера, на котором расположен сайт. Вариантов протоколов достаточно много, но чаще всего используется именно показанный в примере HTTP (протокол передачи гипертекста). Иногда вы можете встретить и HTTPS, что означает шифрование передаваемых данных.
Откуда возникают зеркала со слешем и без слеша на конце и с index.php
Еще очень важно понимать, что в интернете все построено на принципах, заложенных в Линукс системах, которыми и нужно руководствоваться при написании и прочтении Урл адресов. Например, подобная запись:
https://ktonanovenkogo.ru/papka
будет означать, что идет обращение к файлу papka (в линуксе расширения для файлов не нужны, в отличии от Виндовс), а вот такой вид записи (со слешем на конце):
https://ktonanovenkogo.ru/papka/
говорит об обращении к самой папке. Причем в настройках сервера данные виды записей могут быть заданы как алиасы (т.е. синонимы), но могут и не быть заданы. Де-юро — это разные Урлы, хотя де-факто могут быть и одинаковыми (алиасами).
В линуксе papka.html — это не файл с расширением Html, а просто такое странное имя файлика с точкой посередине. Поэтому и вы, например, при настройке ЧПУ (чуть выше приводил ссылки) можете добавлять окончание .html или .php (или любое другое) в конце Урлов страниц своего сайта, а можете и не добавлять. Никого значения это не имеет, а лишь создает некое ощущение законченности для пользователей, привыкших к традиционной ОС Windows.
Именно поэтому при написании и понимании Урлов следует обращать внимание на завершающий слеш. Если он есть, то обращение идет к папке, а если нет — то к файлу. Все просто. Однако, это мы с вами знаем эту тонкую разницу, а подавляющее большинство пользователей сети не знают. Поэтому все веб-серверы настроены таким образом, что при обращении к ним по следующему Урлу:
https://ktonanovenkogo.ru/papka
они будут в первую очередь искать в корневой папке (или какой-то еще, которая будет прописана в урле перед последним слешем) файлик с названием papka. Не найдя его, они поймут, что очевидно просто был упущен последний слеш при формировании Урла, а значит нужно искать не файл, а директорию papka, что сервер с успехом и сделает.
Однако, открыть пользователю просто содержимое папки сервер не может (точнее может, но не должен этого делать, ибо тем самым подрывает безопасность сайта — для этого даже специальную директиву „запрета листинга каталога“ в корневой файл .htaccess добавляют на отдельной строке: Options -Indexes), ибо в папке контент, по идее, содержаться не должен.
Сервер в этом случае должен прошерстить названия файлов, заключенных в этой папке на предмет нахождения чего-нибудь с названием index, и именно его открыть при запросе такого Урл адреса, указывающего на папку. Это может быть index.html или index.php.
Такая сложившаяся ситуация приводит к так называемому „дублированию“, когда одна и та же страница доступна по трем разным Урл адресам, которые будут называться зеркалами. В нашем примере это будут адреса:
https://ktonanovenkogo.ru/papka https://ktonanovenkogo.ru/papka/ https://ktonanovenkogo.ru/papka/index.php
Хорошо ли это? Нет, и эту проблему в обязательном порядке нужно решать. Дело в том, что у поисковых машин ограничен ресурс (технический и материальный), а значит, обнаружив одну и ту же информацию по трем разным адресам, машина не будет хранить все три Урла и вместе с ними три одинаковые страницы в индексной базе. Она вынуждена будет выбрать только один из них для учета и хранения. А какой именно?
Этого никто угадать не в состоянии. Но один из Урлов станет главным, а остальные будут признаны зеркалам. Зеркала машина посчитает синонимами (алиасами) и склеит их. Вся проблема в том, что очень сложно угадать, какой именно вариант написания Урла станет главным и попадет в индекс. А значит не понятно, какую именно страницу нам нужно продвигать, как SEO оптимизаторам (на какой Урл закупать ссылки или делать внутреннюю перелинковку).
Если ваше мнение по выбору главного зеркала не совпадет с мнением поисковой системы, то затраченные на продвижение усилия и средства будут напрасными. В принципе, для каждой страницы сайта можно спустя какое-то время понять, какой же вариант поисковик сохранил в индексной базе, но этот путь уж слишком сложен. Гораздо более простым будет способ, при котором поисковому роботу мы не предоставим возможности выбирать (дать только один вариант). Как это сделать?
Есть несколько вариантов решения данной проблемы, но рассмотрим мы их чуть позже, а сейчас давайте посмотрим еще на один очень распространенный вариант возникновения зеркал всего сайта.
Причина появления зеркал с WWW в названии доменов и почему это опасно
Это те самые зеркала с WWW и без него, о возникновении и борьбе с которыми мне уже доводилось писать. Однако, повторюсь. Выглядят зеркала с WWW и без оных примерно так:
https://www.ktonanovenkogo.ru/papka/fail.html https://ktonanovenkogo.ru/papka/fail.html
Откуда взялось это пресловутое WWW? В статье про DNS и структуру доменных имен я писал, что система доменных имен появилась не сразу, а уже на одном из этапов существования и развития интернета. До нее адреса ресурсов тогда еще не глобальной сети выглядели как-то так: www.ktonanovenkogo или www.magazin.
Возможно, что я не точно передаю картину, но проверить сейчас это уже довольно-таки хлопотно, да и не нужно. Оставим на суд зрителей. Итак, после появления идеи DNS все доменные имена стали формироваться уже по другому принципу:
...третий_уровень.второй_уровень.первый_уровень.нулевая_зона
Доменные зоны стали разделять точками. Причем отсчет ведется справа налево. Нулевая зона, по идее, должна была обозначаться только точкой, но в силу того, что это было одинаково для всех — от лишнего знака в самом конце доменного имени решили отказаться. Домены первого уровня разделили на два типа — предназначенные для стран (ru, ua и т.д.) и общедоступные (com, net и т.п.).
Домены второго уровня, как вы знаете, стали сдавать в аренду (для рунета срок аренды измеряется годом, после чего вы имеете право оплатить его продление). В зонах же более высокого уровня хозяевами стали те, кто арендовал зону второго. Если это не совсем понятно, то обратитесь к приведенной чуть выше статье.
После ввода в строй DNS серверов встал вопрос о переходе со старых систем обозначения сайтов к новым. Решили сделать просто — перенесли структуру целиком и поставили www.ktonanovenkogo или www.magazin сразу перед доменной зоной первого уровня. Получилось что-то типа www.ktonanovenkogo.ru или www.magazin.com.
Т.е. WWW стало автоматически доменом третьего уровня (субдоменом) и на первых порах все DNS сервера содержали такие вот конструкции — все хосты сайтов того времени начинались с WWW. Смысла в этом, однако, никакого не было, но сыграла свою роль все та же привычка, что заставляет нас добавлять к Урлам страниц расширение html или php.
WWW — это рудимент (искусственное внедрение), доставшийся нам из давней истории того, что такое интернет, и который в некотором роде является помехой. Каждому вебмастеру предоставляется возможность самому бороться с этим злом, ломая мозг по поводу — какой „умный человек“ все это придумал.
Получается, что у каждого домена второго уровня (полученного у регистратора) существует алиас (зеркало) на домене третьего уровня (с WWW). Этот подарок вы получаете непосредственно от регистратора, который делает для вашего домена алиас с WWW. Это реализуется из соображений удобства, чтобы „чайники“, считающие, что все веб адреса должны начинаться с трех волшебных буковок, не были бы разочарованы в своих заблуждениях, добавив их в Урл вашего сайта.
Данная ситуация (вкупе с описанной выше ситуацией со слешем в конце Урл адреса и окончанием index.php) опять же будет трактоваться поисковыми системами не предсказуемо (нельзя угадать, какое зеркало поисковик посчитает главным, предоставь вы ему возможность выбирать). Это чревато потерей части ссылочной массы, поэтому с такими невольными зеркалами надо разбираться и бороться.
Нет правильного или неправильного зеркала (с WWW или без него). Для SEO главное, чтобы это зеркало было одно.
Как проверить и склеить зеркала вашего сайта?
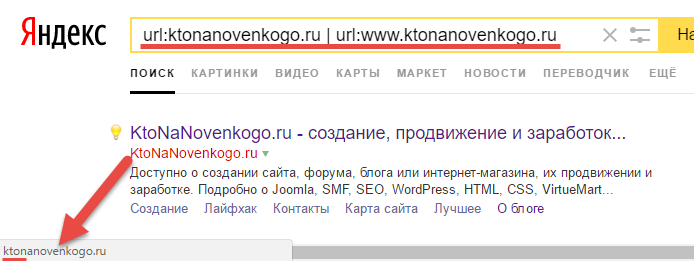
Если помните, то я как-то писал про язык запросов Яндекса, который призван помогать быстрее найти нужный ответ, например, путем сужения области поиска. Вот мы им и воспользуемся, чтобы ответить на волнующий нас вопрос. Для этого в поисковую строку Яндекса нужно будет ввести следующую конструкцию:
url:ktonanovenkogo.ru | url:www.ktonanovenkogo.ru
В результате вы увидите то что никогда не видели выдачу Яндекса по этому запросу, где может быть несколько вариантов:
- В выдаче только один результат — это означает, что в индексе поисковика хранится только одно зеркало (второе либо было уже склеено, либо исключено каким-то другим способом). Посмотреть, какой именно это вариант (с WWW или без оного), вы можете, подведя курсор мыши либо к тайтлу, либо к области с Урлом страницы, показанной на скриншоте.

В результате, браузер вам покажет, на какую именно страницу ведет эта ссылка (в моем случае это вариант без WWW). Выбор этого зеркала главным мог произойти либо по прихоти самого поисковика, либо с вашей помощью.
- В выдаче оказалось два результата — означает, что в индексе хранятся оба зеркала вашего сайта. Процесс определения главного зеркала поисковиком еще не был завершен, либо робот-зеркальщик еще не посетил ваш сайт, чтобы склеить их нужным образом.
- В выдаче по данному запросу много результатов — означает, что вы ошиблись в использовании операторов языка запросов Яндекса, приведенных выше. Проверь их правильность.
- В выдачи нет вообще результатов по данному запросу — означает, что ваш сайт еще не был проиндексирован данным поисковиком.
Точно так же вы можете проверить и наличие в индексе зеркал основного хоста с и без слеша на конце или с index.php:
url:ktonanovenkogo.ru | url:ktonanovenkogo.ru/index.php
Это был способ, когда мы спрашивали о наличии зеркал в индексе у той самой инстанции, ради которой мы так и стараемся — поисковой системы. Однако, можно и прямо на своем сайте проверить склейку зеркал.
Просто введите в адресную строку браузера сначала Урл любой странички с WWW, а потом без этой комбинации. Если в одном из случаев перейдет автоматическое изменение введенного вами Урла (исчезнет WWW или, наоборот, появится), то значит у вас на сайте все в порядке со склейкой зеркал с использование 301 редиректа.
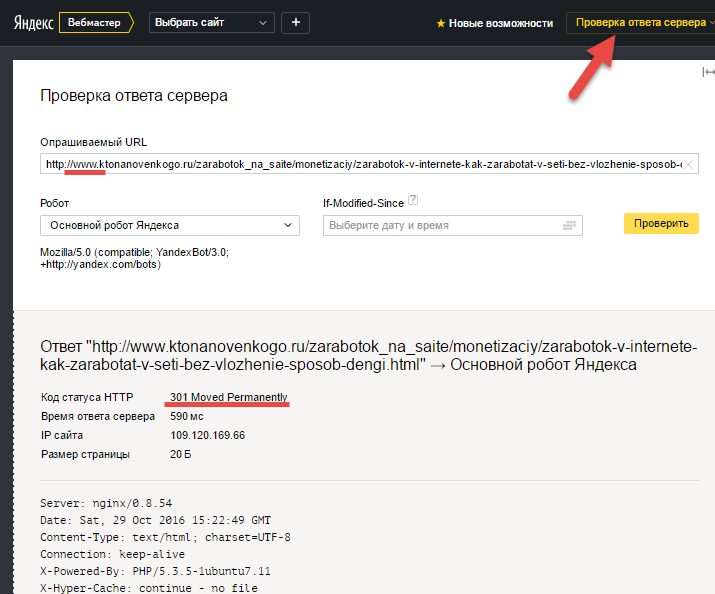
Чуть ниже я буду говорить про коды ответа сервера. Так вот, если мы посмотрим ответ моего сервера на Урл с WWW, то как раз и увидим использование 301 редиректа (для этого я взял сервис Яндекса „Проверка ответа сервера“). Тот же 301 редирект будет показан и при вводе в этот сервис Урла „https://ktonanovenkogo.ru/index.php“.
Как склеить найденные зеркала?
Другой вопрос — как склеить эти самые зеркала, если вы обнаружили их наличие в индексе поисковиков? В принципе, в статье про 301 редирект для склейки зеркал с WWW я приводил один из вариантов реализации. Однако, все зависит от того программного обеспечения, на котором работает ваш сервер. У кого-то это сработает, а у кого-то нет. Что делать?
Во-первых, не паниковать. Ибо самое важное вы уже сделали — нашли проблему, которая мешала или могла помешать успешному продвижению. Во-вторых, можно просто обратиться в техподдержку вашего хостинга, обстоятельно объяснить возникшую проблему и (бесплатно или за денежку) договориться о том, чтобы вам ее устранили. Для сисадмина хостинга это совсем не сложно.
Кроме этого, для Яндекса можно использовать директиву Host в файле robots.txt (указав в ней основное зеркало), о котором я уже довольно подробно писал. Также можно использовать панель Яндекс Вебмастера для указания основного зеркала (вкладка „Настройки индексирования“ — „Переезд сайта“):
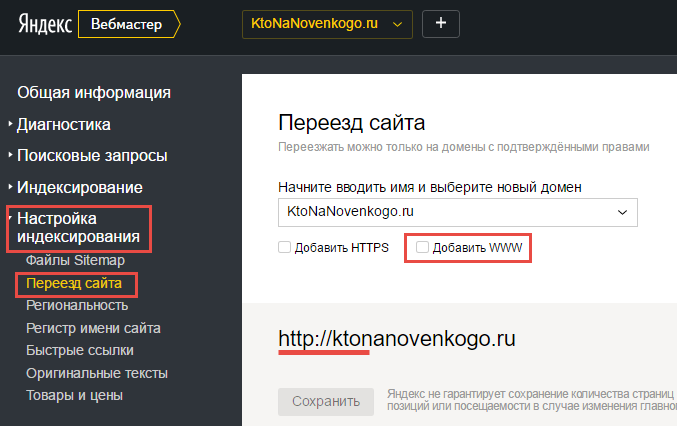
У меня был сразу после создания блога настроен 301 редирект на Урл адреса без WWW, а также прописана директива в роботс. тхт (в блоке, предназначенном для Яндекса — User-agent: Yandex):
User-agent: * Disallow: User-agent: Yandex Disallow: Host: ktonanovenkogo.ru Sitemap: https://ktonanovenkogo.ru/sitemap.xml.gz Sitemap: https://ktonanovenkogo.ru/sitemap.xml
Смысла задавать главное зеркало в настройках Вебмастера уже не было, ибо Яндекс и так правильно выбрал главное зеркало.
Управление сервером Apache с помощью .htaccess
С высокой вероятностью ваш сайт будет работать под управлением веб-сервера Apache (он используется на подавляющем числе серверов). Он бесплатный, постоянно обновляемый, хорошо оттестированный и имеет большое количество расширений. Давайте посмотрим, как с помощью настроек его конфигурационного файла можно склеить оба типа описанных выше зеркал (с WWW и и index.php).
У веб-сервера Apache основной конфигурационный файл называется httpd.conf. Однако, если в нем прописана разрешающая директива, то для каждого каталога сайта на вашем сервере можно будет использовать дополнительный файл конфигурации .htaccess. Возможности у него такие же, как и у httpd.conf, но все прописанные в нем директивы будут применяться только к той папке, в которой он находится.
Однако, если разместите файл .htaccess в корне, то его действие распространится на весь ваш сайт. Этот способ конфигурирования Apache удобен тем, что доступ к .htaccess, лежащему в корне сайта, можно получить по обычному ФТП соединению с помощью любого ФТП клиента. Редактировать же его можно в любом текстовом или Html редакторе (в том числе и в онлайн редакторе).
Если у вас в корневой директории .htaccess нет, то просто создайте у себя на компьютере пустой текстовый файл и сохраните его без расширения и с точкой перед названием htaccess. После этого подключитесь к сайту по ФТП и скопируйте данный пустой файлик в корневую папку. Потом по мере необходимости открывайте его и вносите нужные вам инструкции, которые с великим удовольствием выполнит веб-сервер Apache.
Однако, настоятельно рекомендую перед каждой правкой .htaccess сохранять его к себе на компьютер, ибо из-за ошибки во вносимой инструкции может стать недоступным весь сайт. Имея бекап, вы сможете восстановить все как было в считанные секунды. Ну и также советую правку вносить не в обычном блокноте Виндовс, а в редакторе на вроде Notepad++, где есть возможность откатиться назад.
Как склеить зеркала при использовании сервера Apache
Итак, большинство сайтов в рунете работают на Apache, поэтому будет не лишним привести код, добавляемый в .htaccess, который гарантирует стопроцентную склейку описанных выше зеркал. В своей основе он опирается на 301 редирект со всех Урл адресов, имеющих в своем составе WWW на Урлы без WWW (или наоборот). Что такое 301 редирект?
К сожалению, в рамках этой статьи об этом подробно поговорить уже не удастся, но вторая часть данной публикации будет как раз посвящена описанию принципов взаимодействия поисковых роботов и веб-серверов (обязательно подпишитесь на рассылку моего блога, чтобы не пропустить эту публикацию), где мы рассмотрим все возможные коды ответов сервера (в том числе и кода 301).
Если же говорить кратко, то код ответа 301 означает „переадресацию навсегда“, после которой поисковая система исключит из своей базы старый Урл, а все ссылки, что на него вели, будут засчитаны Урлу новому (осуществится перенос ссылочного веса). На вашем же сайте при запросе страницы по старому урлу будет происходить автоматический мгновенный (не заметный) переброс на новый. Как это реализовать?
Нам понадобится добавить несколько строк в файле .htaccess, о котором шла речь чуть выше. При этом используются возможности расширения программы веб-сервера Apache под названием mod_rewrite.
Итак, давайте сделаем 301 редирект с WWW на без WWW (со всех урлов, включающих WWW, на урлы без этих трех букв). Для этого достаточно будет в файл .htaccess добавить конструкцию из четырех строк (скопируйте предварительно оригинальный файл .htaccess к себе на компьютер, чтобы можно было бы им заменить имеющийся на сервере в случае неудачи):
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.(.*) [NC]
RewriteRule ^(.*)$ http://%1/$1 [R=301,L]
Первые две строчки делают что-то такое, что я объяснить толком не могу, поэтому и не буду. Ну, а две последние как раз и осуществляют перенаправление на Урлы без WWW. Всякие хитрые значки, используемые в этих строчках, относятся к синтаксису так называемых „регулярных выражений“, которые помогают программистам в их нелегкой задаче. Хотите узнать больше про регулярные выражения — велком в Википедию (и побольше терпения с собой возьмите).
Есть еще один популярный вариант реализации того же самого действа (редиректа с Урлов, использующих WWW):
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.domain.ru$ [NC]
RewriteRule ^(.*)$ http://domain.ru/$1 [R=301,L]
Только не забудьте заменить domain и domain.ru на название вашего домена, например, ktonanovenkogo и ktonanovenkogo.ru
Если вы хотите, что в ваших урлах рудимент в виде WWW все же оставался, то сделайте обратный 301 редирект с Урлов без WWW на Урлы с WWW:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.domain.ru$ [NC]
RewriteRule ^(.*)$ http://domain.ru/$1 [R=301,L]
Ну, и альтернативный вариант для гурманов:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www.(.*) [NC]
RewriteRule ^(.*)$ http://www.%1/$1 [R=301,L]
По поводу склеивания зеркал со слешем, без него и с index.php (или index.html — зависит от настройки веб-сервера) ничего определенного сказать не могу, ибо у меня хостер эту проблему решал. Советую вам сделать простейшую проверку и посмотреть что происходит, когда в адресную строку браузера вы вводите:
https://ktonanovenkogo.ru https://ktonanovenkogo.ru/ https://ktonanovenkogo.ru/papka/index.php https://ktonanovenkogo.ru/papka/index.html
Лично у меня в первых трех случаях Урл в адресной строке автоматически заменяется на первый вариант, а в последнем выдает 404 ошибку (документ не найден). Т.е. получается, что у меня эти зеркала успешно склеены, а страница с index.html просто отмечена, как не существующая страница, что тоже верно.
Если у вас в адресной строке после добавления к Урлу главной страницы слеша или index.php открывается главная, но сам Урл не меняется, то имеет место проблема с не склеенными зеркалами. Обращайтесь к хостеру за консультацией или помощью. Повторюсь, что для администратора сервера это не сложная задачка.
Canonical для удаления дублей контента
Хотя статья и так уже получилась чрезмерно длинной, не могу не упомянуть про такую замечательную вещь, как атрибут rel=»canonical» тега служебной гиперссылки link. Он позволяет на всех страницах-дублях (включая и описанные выше зеркала) прописать адрес канонического Урла, который и предназначен для хранения в индексной базе поисковика.
Например, для нашего последнего случая нужно будет, чтобы на всех страницах был прописан тег с каноническим Урлом (в нашем случае без слеша):
<link rel="canonical" href="https://ktonanovenkogo.ru" />
Кроме описанных выше зеркал дубли страниц могут плодить и сами движки сайтов. Также в некоторых движках, при нахождении товара или статьи в нескольких категориях, у них будут формировать разные Урлы (с разным названием категории внутри Урла). Ну и все те же Урлы с параметрами, которые могут выглядеть, например, так:
https://ktonanovenkogo.ru/category/joomla/joomla-2-5-3-x?print=yes
Однако, если ваш движок будет прописывать между тегами Head тег link rel=»canonical» с указание Урла основной страницы, которая и должна быть проиндексирована поисковиками, то вы избежите ненужный проблем. Например, на моем блоге для показанной выше страницы ее исходный код будет содержать такую вот конструкцию:
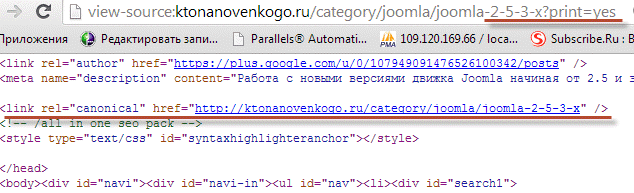
Если говорить про WordPress, то я для добавления Canonical на всех страницах блога, использую плагин All in One SEO Pack. Возможно, что я отстал от жизни и в этот движок уже интегрирована поддержка Canonical. Какие-то движки имеют поддержку этой функции по умолчанию, а в какие-то нужно будет устанавливать расширения.
Однако, поисковым роботом Яндекса атрибут rel=»canonical» не сто процентов будет учтен. Canonical для него носит рекомендательный, а не обязательный характер, поэтому склеивайте зеркала с помощью редиректов — так будет спокойнее.
Директива Disallow в robots.txt
Тоже очень известный способ борьбы с дублями контента, который появился еще до ввода rel=»canonical». Есть такой замечательный инструмент для общения с поисковым роботом, как файлик с говорящим названием — robots.txt. Про оптимальный robots.txt lzk WordPress, Joomla и SMF я уже писал, но подчеркну, что там мы активно использовали директивы Disallow, позволяющие отговорить робота поисковый системы от индексации чего бы то ни было.
В следующей статье мы поговорим еще про очень важные вещи, связанные с общением поискового робота и вашего сервера на языке http запросов и ответов. Не переключайтесь и подписывайтесь на рассылку.
Содержание:
- Зеркало сайта и SEO
- Как найти зеркало сайта, которое является основным
- Как склеить зеркала сайта
- Краткое резюме
В пределах этой статьи мы попытаемся дать Вам ответы на некоторые вопросы из разряда «Что такое, как создать и как правильно настроить зеркало сайта?».
Итак, начнем с определения: зеркало сайта – это его полная или частичная копия в плане содержимого контента.
Любой веб-сайт при создании становится доступным по двум адресам – просто URL и URL с WWW, которые в глазах поисковиков являются различными ресурсами, несмотря на полное дублирование их содержимого.
Если не указать зеркало сайта, которое является основным, поисковики могут произвести выбор сами, исходя из своих алгоритмов, и в индексе отображать лишь один из альтернативных адресов. И, к сожалению, их мнение не всегда может совпадать с Вашим. В итоге Вы можете тратить силы на продвижение «не того» адреса.
Получить бесплатную консультацию от SEO-эксперта по вашему сайту
Как найти зеркало сайта, которое является основным
Поисковики могут воспринимать существование зеркал, как дублирование контента – один из основных факторов, из-за которых происходит проседание позиций сайта. Поэтому нужно знать, как найти зеркала веб-сайта и при необходимости избавиться от них или произвести их склейку.
Проще всего это сделать, используя сервис в Яндекс.Вебмастере «Добавить новый сайт». Проверив все возможные адреса, можно будет увидеть сообщения «URL уже проиндексирован» (этот адрес является основным) и «Указанный веб-ресурс является неглавным зеркалом такого-то сайта».
Или же ввести один из альтернативных адресов в поисковую строку Google и определить зеркало сайта, которое будет отображено в результатах (оно и является главным).
Как склеить зеркала сайта
Кроме того, что поисковикам нужно знать, какой из адресов веб-сайта должен отображаться в поиске, существование зеркал может плохо сказываться на процессе продвижения. Во время наращивания ссылочной массы внешние ссылки могут ошибочно содержать альтернативные адреса. А это значит, что накапливаемый ссылочный вес будет перераспределяться между ними, занижая реальные позиции.
Избежать подобной проблемы можно, если знать как склеить зеркало сайта, чтобы суммировать все показатели:
- Для начала необходимо прописать 301 redirect в файле .htaccess:

- Далее в Яндекс.Вебмастере в разделе “Индексирование → Переезд сайта” укажите главное зеркало

- Для Google потребуется добавить в Search Console все варианты адресов как отдельные веб-ресурсы и в для каждого из них в «Настройках сайта» указать предпочитаемый основной URL.
- Аналогичным способом можно склеить зеркало сайта, которое образовалось из-за целенаправленной смены его адреса, чтобы передать все достижения старого веб-ресурса новому (ссылочный вес и т. д.).
Краткое резюме
Как Вы уже поняли существуют различные ситуации, в которых появляется необходимость создать зеркало сайта или произвести склейку нескольких из них: от самого обычного перенаправления с WWW на URL без него до переноса годами зарабатываемых показателей со старого адреса на новоприобретенный. В SEO без этого не обойтись, иначе управлять процессом продвижения будет просто невозможно.
Остались вопросы? Посети блок комментариев и задай их нам!
Чувствуете что бизнесу нужен апгрейд?
Получить бесплатную консультацию от специалиста по вашему проекту
Подробнее