Sorry for the weird question as I don’t know what to put in it.
I am working on a text file, want to know the value next to that string like:
ItemIndex = 6; //the number 6 will change overtime
So I want to get that value «6» and change that, here’s my code:
var textSample= File.ReadAllText(path to text file);
var textConfig = textSample.Replace("ItemIndex ="0"", "ItemIndex ="$$$"");
var changedConfig = textConfig.Replace("ItemIndex ="$$$"", $"ItemIndex ="{myValue}"");
File.WriteAllText(path to text file, changedConfig);
But that no work. Can anyone tell me what’s wrong?
У сайта есть API и если, при открытии страницы, посмотреть какие запросы посылает сайт, то найдем такие ссылки:
- GET: https://api.sky.bank/currency/get-offices-list . Возвращает список отделений банков
- POST: https://api.sky.bank/currency/rates-by-codes . Возвращает валюты с значением курса по отделениям банков
Так что, мы можем их повторить.
Кст,:
- Не все сайты имеют данные по валюте, поэтому в API их больше, чем отображается
- Валюта приходит в меньшем номинале (копейки, центы и т.п.), поэтому в ответе есть и указание на сколько делить (см.
buy_unitиsell_unit) - Делить лучше как
Decimal(чтобы указать максимальную точность, типа 2 знака после запятой и т.п.), чемfloat, но для простоты решения оставилfloat
Пример:
import requests
session = requests.session()
session.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'
URL_GET_OFFICES = 'https://api.sky.bank/currency/get-offices-list'
URL_RATES_BY_CODES = 'https://api.sky.bank/currency/rates-by-codes'
rs = session.get(URL_GET_OFFICES)
office_id_by_name = {
x['id']: x['sname'] for x in rs.json()['response']
}
print(office_id_by_name)
# {24: '1 ФИЛИАЛ (закр)', 2: 'АТ "СКАЙ БАНК"', 25: 'Барвінківське відділення', 4: 'БАРВ.Ф.АКРБ "РЕГ_ОН-БАНК" ...
rs = session.post(URL_RATES_BY_CODES)
currency_by_rates = rs.json()['response']
print(currency_by_rates)
# {'EUR': [{'id': 839871, 'currency_id': 4, 'unit': None, 'rate': None, 'date': '2022-01-28T00:00:00+02:00', ...
print()
for office_id, name in office_id_by_name.items():
print(f'{name} (#{office_id}):')
for currency_name, rates in currency_by_rates.items():
for rate in rates:
if rate['office_id'] == office_id:
buy_rate = rate["buy_rate"]
sell_rate = rate["sell_rate"]
print(f' {currency_name}: {buy_rate} | {sell_rate}')
print()
Результат:
1 ФИЛИАЛ (закр) (#24):
АТ "СКАЙ БАНК" (#2):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Барвінківське відділення (#25):
БАРВ.Ф.АКРБ "РЕГ_ОН-БАНК",М.БАРВ_НКОВЕ (#4):
Виртуальное ТОБО АТ "СКАЙ БАНК" (#29):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Днепр (#22):
Київське відділення №1 (#21):
EUR: 32.17 | 32.32
RUB: 0.361 | 0.37
USD: 28.82 | 28.9
Ф-Я N 1 АКРБ "РЕГ_ОН-БАНК",ХАРК_В (#3):
Харківське відділення №1 (#6):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське відділення №11 (#16):
Харківське відділення №12 (#17):
Харківське відділення №13 (#18):
Харківське відділення №14 (#19):
Харківське відділення №2 (#7):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське відділення №3 (#8):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське відділення №4 (#9):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське відділення №5 (#10):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське відділення №7 (#12):
Харківське відділення №8 (#13):
Харківське головне відділення (#14):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
Харківське Центральне відділення (#23):
EUR: 32.2 | 32.35
RUB: 0.362 | 0.371
USD: 28.85 | 28.95
ХВ N10 АТ `РЕГІОН-БАНК` (#15):
ХВ N15 АТ `РЕГІОН-БАНК` (#20):
ХВ N6 АТ `РЕГІОН-БАНК` (#11):
ХФ БАРВЕНКОВО(ЗАКР) (#26):
Чугуев филилал (Закр) (#28):
Чугуївське відділення (#27):
ЧУГУЇВ.Ф.АКРБ "РЕГ_ОН-БАНК", М.ЧУГУЇВ (#5):
Вы можете попытаться найти первый div как элемент, и из этого списка элементов все дочерние элементы ниже.
Вот пример кода из головы:
<div>
<a> Test </a>
<a>dynamic text will be here </a>
<a> Test4 </a>
...
</div>
поэтому код будет выглядеть примерно так:
WebElement divElement = driver.findElement(By.tagName("div"));
List<WebElement> listA = divElement.findElement(By.tagName("a"));
WebElement elementDynamic = listA.get(1);
так что у вас есть все элементы в одном объекте, так что вы можете выполнять итерации и выполнять любые необходимые действия, которые вам нужны.
Надеюсь, поможет,
Решение
Алгоритм
- Для каждой таблицы конкатенируем текстовые столбцы с некоторым разделителем, которого заведомо не может быть в поисковой строке. Это позволит нам избежать ситуации, когда искомый фрагмент текста может начинаться в одном столбце строки таблицы, а заканчиваться — в другом.
- Для каждой таблицы формируем строку запроса для динамического выполнения.
- Полученный в результате первых двух пунктов запрос будем использовать в качестве источника строк для курсора.
- При обходе курсора будем динамически выполнять построенный оператор. Чтобы избежать вывода всех таблиц, дополним скрипт критерием существования искомых строк в результатах поиска. Тогда на выходе будут только те строки/таблицы, в которых содержится искомая подстрока.
Пункт 1 алгоритма
Столбцы таблиц можно извлечь из системного представления INFORMATION_SCHEMA.COLUMNS. Поскольку у нас появилась замечательная функция CONCAT, то нет особой необходимости выбирать только столбцы строковых типов данных. Дело в том, что функция CONCAT неявно преобразовывает данные к строковому типу и, кроме того, заменяет при этом NULL-значение пустой строкой.
Замечания. Не все типы данных могут быть неявно преобразованы к строке. Устаревший тип IMAGE нельзя преобразовать, поэтому в коде исключается таблица dtproperties, содержащая данные для построения диаграммы и использующая этот тип данных. Помимо этого, имеются типы данных, которые могут быть преобразованы только явно:
- hierarchyid
- sql_variant
- XML
- CLR UDT
Вот скрипт, который выполняет указанные действия:
SELECT TABLE_NAME, STRING_AGG(concat(COLUMN_NAME,',''|'''),',') cols
FROM information_schema.columns
WHERE TABLE_NAME != 'dtproperties'
GROUP BY TABLE_NAME
Ниже приведены результаты выполнения кода. В качестве примера используется учебная база данных сайта.
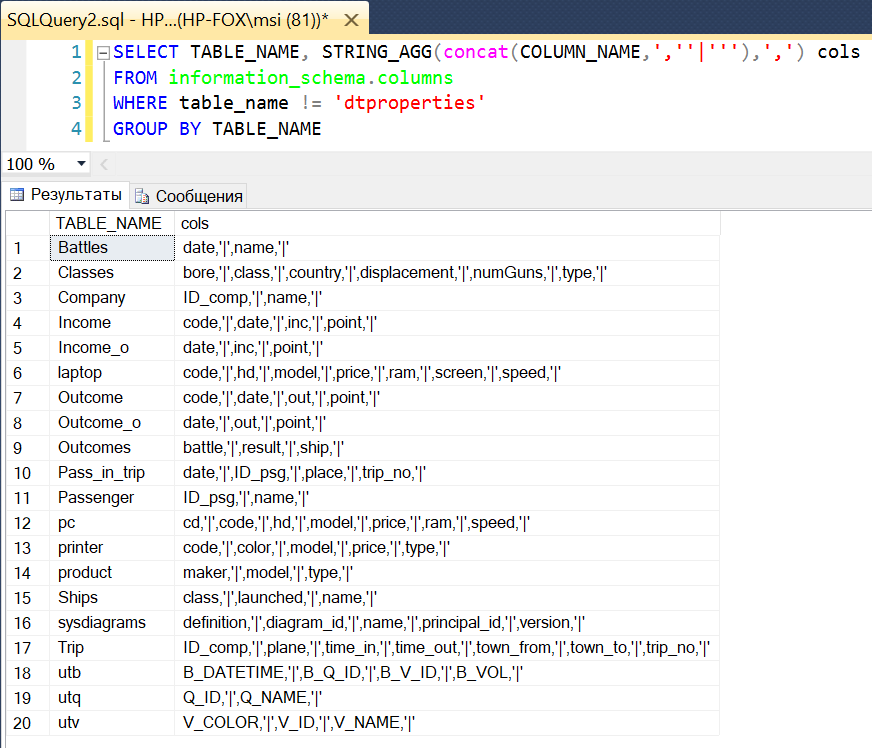
Пункт 2 алгоритма
Формируем строку запроса, конкатенируя строки. Переменная @search будет содержать поисковую строку. Для примера в качестве поисковой строки используется небезызвестный Bismarck, т.е. мы будем искать текст содержащий слово Bismarck в любом месте строки. Сам поисковый запрос находится во втором столбце результирующего набора, а в первом мы будем выводить имя таблицы. Для нашей задачи имя таблицы в первом столбце не используется в дальнейшем. Но оно может потребоваться для расширения функциональности. Вот к чему мы пришли:
DECLARE @search varchar(200) ='bismarck';
WITH tbls AS
(SELECT TABLE_NAME, STRING_AGG(concat(COLUMN_NAME,',''|'''),',') cols
FROM information_schema.columns
WHERE TABLE_NAME != 'dtproperties'
GROUP BY TABLE_NAME)
SELECT TABLE_NAME, CONCAT('select ''',TABLE_NAME,''' table_name,* from ',
TABLE_NAME,' where concat(',cols,') like ''%', @search,'%''' ) stmt
FROM tbls;
И фрагмент результата:
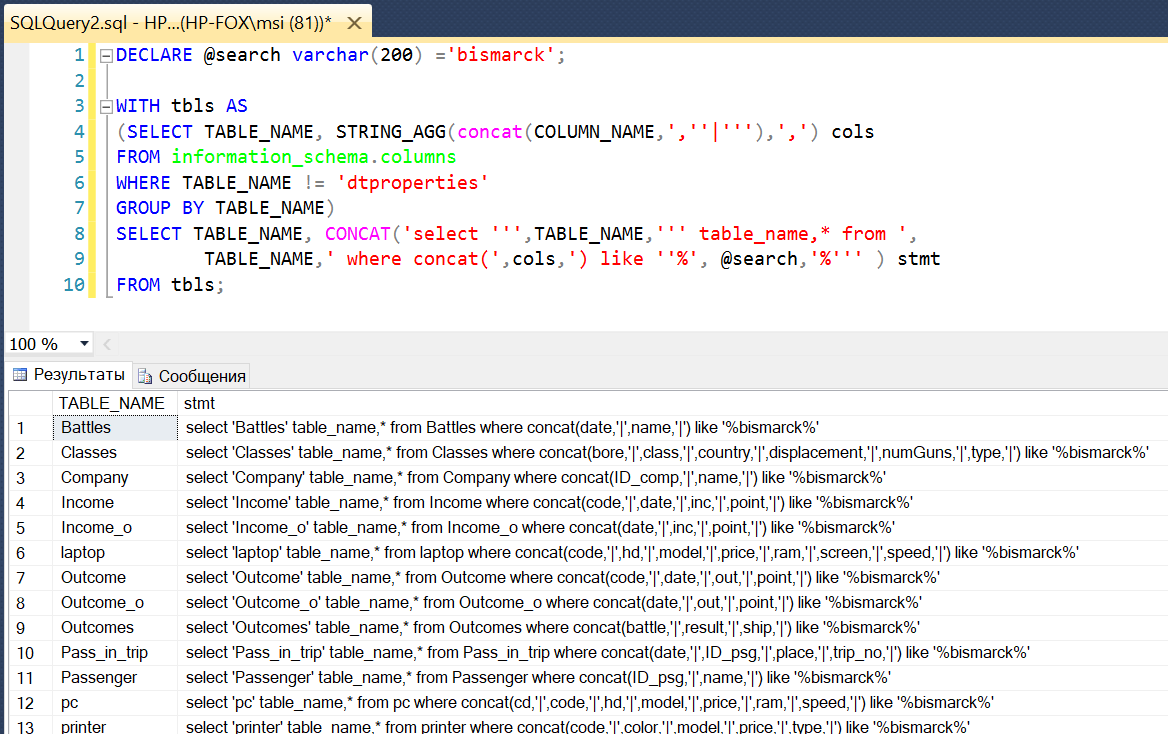
Напомню, что мы исходим из того, что разделитель столбцов (у нас «|») не должен присутствовать в поисковой фразе. В противном случае, нужно этот символ заменить на другой (другие).
Пункт 3 алгоритма
Описываем и открываем курсор, источником данных для которого будет полученный ранее запрос. Дополнительно опишем две переменных, куда будут заноситься данные, извлекаемые при обходе курсора. Тут все ясно.
DECLARE @t VARCHAR(100);
DECLARE @s VARCHAR(2000);
DECLARE @search VARCHAR(200) ='bismarck';
DECLARE X CURSOR for
WITH tbls AS
(SELECT TABLE_NAME, STRING_AGG(concat(COLUMN_NAME,',''|'''),',') cols
FROM information_schema.columns
WHERE TABLE_NAME != 'dtproperties'
GROUP BY TABLE_NAME)
SELECT TABLE_NAME, CONCAT('select ''',TABLE_NAME,''' table_name,* from ',
TABLE_NAME,' where concat(',cols,') like ''%', @search,'%''' ) stmt
FROM tbls;
OPEN X;
Пункт 4 алгоритма, последний
Обходим курсор, выполняя сформированный оператор во втором столбце курсора. Вернее, не совсем тот. Чтобы убрать неинформативный вывод таблиц, в которых не было найдено совпадение с поисковой фразой, мы дополняем оператор проверкой наличия строк на выходе. В итоге будут получаться операторы такого вида:
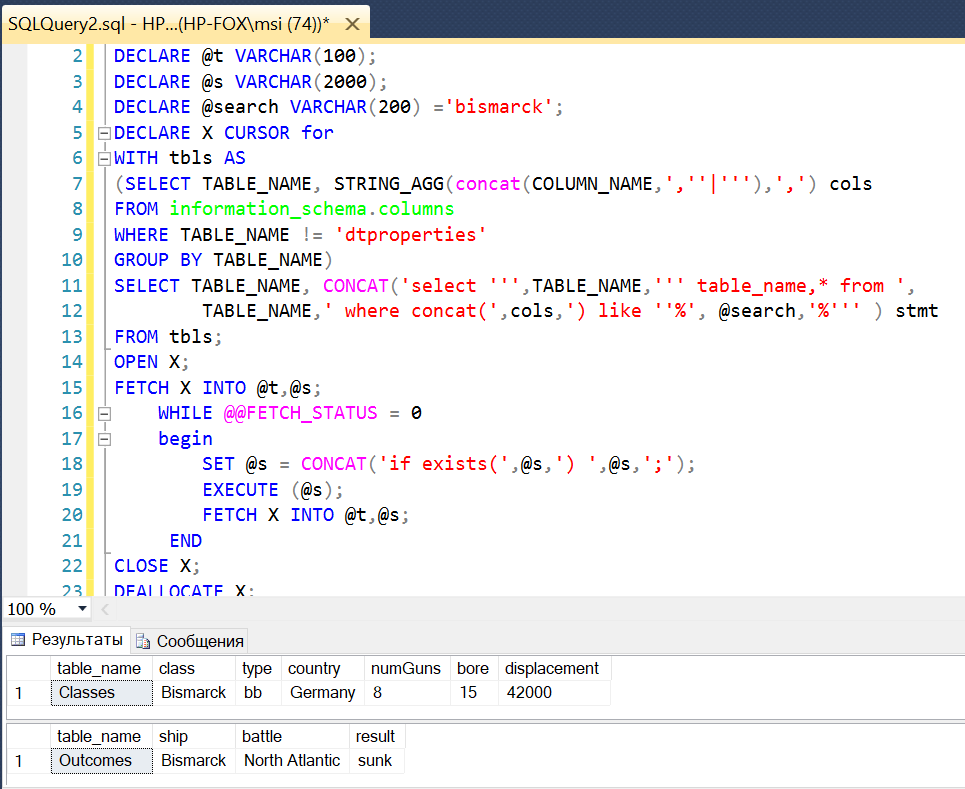
if exists(select 'Battles' table_name,* from Battles
where concat(date,'|',name,'|') like '%bismarck%')
select 'Battles' table_name,* from Battles
where concat(date,'|',name,'|') like '%bismarck%';
Возможно, это не очень оптимальный прием, но недостатки компенсируются удобством. 
Вот фрагмент кода, выполняющего обход курсора с выполнением поискового оператора:
FETCH X INTO @t,@s;
WHILE @@FETCH_STATUS = 0
begin
SET @s = CONCAT('if exists(',@s,') ',@s,';');
EXECUTE (@s);
FETCH X INTO @t,@s;
END
И, наконец, скрипт целиком:
DECLARE @t VARCHAR(100);
DECLARE @s VARCHAR(2000);
DECLARE @search VARCHAR(200) ='bismarck';
DECLARE X CURSOR for
WITH tbls AS
(SELECT TABLE_NAME, STRING_AGG(concat(COLUMN_NAME,',''|'''),',') cols
FROM information_schema.columns
WHERE TABLE_NAME != 'dtproperties'
GROUP BY TABLE_NAME)
SELECT TABLE_NAME, CONCAT('select ''',TABLE_NAME,''' table_name,* from ',
TABLE_NAME,' where concat(',cols,') like ''%', @search,'%''' ) stmt
FROM tbls;
OPEN X;
FETCH X INTO @t,@s;
WHILE @@FETCH_STATUS = 0
begin
SET @s = CONCAT('if exists(',@s,') ',@s,';');
EXECUTE (@s);
FETCH X INTO @t,@s;
END
CLOSE X;
DEALLOCATE X;
Результаты поиска Бисмарка представлены на рисунке ниже.
Вы не совсем уверены в том, чего хотите достичь.
Если вы хотите, чтобы заголовок отображался в модальном окне, это будет либо «Успех», либо «Ошибка»:
//h4[@class="modal-titel"]/text()
Это предполагает, что на странице будет только один h4 элемент с классом modal-title.
// в любом месте документа
h4[@class="modal-titel"], элемент h4 с атрибутом class, установленным на modal-titel, если этот элемент может иметь другие классы, он должен быть h4[contains(@class, "modal-titel")]
text(), текстовое значение согласованного узла
Если вместо этого вы хотите, чтобы сообщение было в модальном окне, вы можете использовать:
//div[@class="modal-body"]/text()
person
mgor
schedule
13.04.2018