Статистические оценки параметров генеральной совокупности
Определение статистической оценки. Точечные статистические оценки: смещенные и несмещенные, эффективные и состоятельные. Интервальные статистические оценки. Точность и надежность оценки; определение доверительного интервала; построение доверительных интервалов для средней при известном и неизвестном среднеквадратическом отклонении.
Определение статистической оценки
Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Возникает задача оценки параметров, которыми определяется это распределение. Например, если известно, что изучаемый признак распределен в генеральной совокупности по нормальному закону, то необходимо оценить математическое ожидание и среднеквадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение. Если имеются основания считать, что признак имеет распределение Пуассона, то необходимо оценить параметр , которым это распределение определяется. Обычно имеются лишь данные выборки, полученные в результате
наблюдений:
. Через эти данные и выражают оцениваемый параметр. Рассматривая
как значения независимых случайных величин
можно сказать, что найти статистическую оценку неизвестного параметра теоретического распределения означает найти функцию от наблюдаемых случайных величин, которая и дает приближенное значение оцениваемого параметра.
Точечные статистические оценки
Статистической оценкой неизвестного параметра теоретического распределения называют функцию от наблюдаемых случайных величин. Статистическая оценка неизвестного параметра генеральной совокупности одним числом называется точечной. Рассмотрим следующие точечные оценки: смещенные и несмещенные, эффективные и состоятельные.
Для того чтобы статистические оценки давали хорошие приближения оцениваемых параметров, они должны удовлетворять определенным требованиям. Укажем эти требования. Пусть есть статистическая оценка неизвестного параметра
теоретического распределения. Допустим, что по выборке объема
найдена оценка
. Повторим опыт, т. е. извлечем из генеральной совокупности другую выборку того же объема и по ее данным найдем оценку
и т. д. Получим числа
, которые будут различаться. Таким образом, оценку
можно рассматривать как случайную величину, а числа
— как возможные ее значения.
Если оценка дает приближенное значение
с избытком, то найденное по данным выборок число
будет больше истинного значения
. Следовательно, и математическое ожидание (среднее значение) случайной величины
будет превышать
, то есть
. Если
дает приближенное значение
с недостатком, то
.
Использование статистической оценки, математическое ожидание которой не равно оцениваемому параметру, приводит к систематическим ошибкам. Поэтому нужно потребовать, чтобы математическое ожидание оценки было равно оцениваемому параметру. Соблюдение требования
устраняет систематические ошибки.
Несмещенной называют статистическую оценку , математическое ожидание которой равно оцениваемому параметру
, то есть
.
Смещенной называют статистическую оценку , математическое ожидание которой не равно оцениваемому параметру.
Однако ошибочно считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Действительно, возможные значения могут быть сильно рассеяны вокруг своего среднего значения, т. е. дисперсия величины
может быть значительной. В этом случае найденная по данным одной выборки оценка, например
, может оказаться удаленной от своего среднего значения
, а значит, и от самого оцениваемого параметра
. Приняв
в качестве приближенного значения
, мы допустили бы ошибку. Если потребовать, чтобы дисперсия величины
была малой, то возможность допустить ошибку будет исключена. Поэтому к статистической оценке предъявляются требования эффективности.
Эффективной называют статистическую оценку, которая (при заданном объеме выборки ) имеет наименьшую возможную дисперсию. При рассмотрении выборок большого объема к статистическим оценкам предъявляется требование состоятельности.
Состоятельной называют статистическую оценку, которая при стремится по вероятности к оцениваемому параметру. Например, если дисперсия несмещенной оценки при
стремится к нулю, то такая оценка оказывается также состоятельной.
Рассмотрим вопрос о том, какие выборочные характеристики лучше всего в смысле несмещённости, эффективности и состоятельности оценивают генеральную среднюю и дисперсию.
Пусть изучается дискретная генеральная совокупность относительно количественного признака. Генеральной средней называется среднее арифметическое значений признака генеральной совокупности. Она вычисляется по формуле
или
где — значения признака генеральной совокупности объема
;
— соответствующие частоты, причем
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком извлечена выборка объема со значениями признака
. Выборочной средней называется среднее арифметическое значений признака выборочной совокупности и вычисляется по формуле
или
где — значения, признака в выборочной совокупности объема
;
— соответствующие частоты, причем
Если генеральная средняя неизвестна и требуется оценить ее по данным выборки, то в качестве оценки генеральной средней принимают выборочную среднюю, которая является несмещенной и состоятельной оценкой. Отсюда следует, что если по нескольким выборкам достаточно большого объема из одной и той же генеральной совокупности будут найдены выборочные средние, то они будут приближенно равны между собой. В этом состоит свойство устойчивости выборочных средних.
Если дисперсии двух совокупностей одинаковы, то близость выборочных средних к генеральным не зависит от отношения объема выборки к объему генеральной совокупности. Она зависит- от объема выборки: чем больше объем выборки, тем меньше выборочная средняя отличается от генеральной.
Для того чтобы охарактеризовать рассеяние значений количественного признака генеральной совокупности вокруг своего среднего значения, вводят сводную характеристику — генеральную дисперсию. Генеральной дисперсией
называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от их среднего значения
, которое вычисляется по формуле
или
Для того чтобы охарактеризовать рассеяние наблюденных значений количественного признака выборки вокруг своего среднего значения хв, вводят сводную характеристику — выборочную дисперсию. Выборочной дисперсией называется среднее арифметическое квадратов отклонений наблюденных значений признака от их среднего значения
, которое вычисляется по формуле
или
Кроме дисперсии для характеристики рассеяния значений признака генеральной (выборочной) совокупности вокруг своего среднего значения используют сводную характеристику — среднее квадратическое отклонение. Генеральным средним квадратическим отклонением называют квадратный корень из генеральной дисперсии: . Выборочным средним квадратическим отклонением называют квадратный корень из выборочной дисперсии:
.
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком
извлечена выборка объема
. Требуется по данным выборки оценить неизвестную генеральную дисперсию
. Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то эта оценка приведет к систематическим ошибкам, давая заниженное значение генеральной дисперсии. Объясняется это тем, что выборочная дисперсия является смещенной оценкой
. Другими словами, математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
.
Легко исправить выборочную дисперсию так, чтобы ее математическое ожидание было равно генеральной дисперсии. Для этого нужно умножить на дробь
. В результате получим исправленную дисперсию
, которая будет несмещенной оценкой генеральной дисперсии:
Интервальные оценки
Наряду с точечным оцениванием, статистическая теория оценивания параметров занимается вопросами интервального оценивания. Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал, относительно которого с заранее выбранной вероятностью можно сказать, что внутри него находится оцениваемый параметр. Интервальное оценивание особенно необходимо при малом количестве наблюдений, когда точечная оценка малонадежна.
Доверительным интервалом для параметра
называется такой интервал, относительно которого с заранее выбранной вероятностью
, близкой к единице, можно утверждать, что он содержит неизвестное значение параметра
, то есть
. Чем меньше для выбранной вероятности число
, тем точнее оценка неизвестного параметра
. И, наоборот, если это число велико, то оценка, проведенная с помощью данного интервала, малопригодна для практики. Так как концы доверительного интервала зависят от элементов выборки, то значения
и
могут изменяться от выборки к выборке. Вероятность
принято называть доверительной (надежностью). Обычно надежность оценки задается наперед, причем в качестве
берут число, близкое к единице. Выбор доверительной вероятности не является математической задачей, а определяется конкретной решаемой проблемой. Наиболее часто задают надежность, равную 0,95; 0,99; 0,999.
Доверительный интервал для генеральной средней при известном значении среднего квадратического отклонения и при условии, что случайная величина (количественный признак ) распределена нормально, задается выражением
где — наперед заданное число, близкое к единице, а значения функции
приведены в таблице прил. 2.
Смысл этого соотношения заключается в следующем: с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
, точность оценки
. Число
определяется из равенства
, или
. По прил. 2 находят аргумент
, которому соответствует значение функции Лапласа, равное
.
Пример 1. Случайная величина имеет нормальное распределение с известным средним квадратическим отклонением
. Найти доверительные интервалы для оценки неизвестной генеральной средней по выборочным средним, если объем выборок
и надежность оценки
.
Решение. Найдем . Из соотношения
получим, что
. По прил. 2 находим
. Найдем точность оценки
. Доверительные интервалы будут таковы:
. Например, если
, то доверительный интервал имеет следующие доверительные границы:
. Таким образом, значения неизвестного параметра
, согласующиеся с данными выборки, удовлетворяют неравенству
.
Доверительный интервал для генеральной средней нормального распределения признака при неизвестном значении среднего квадратического отклонения задается выражением
Отсюда следует, что с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
.
Существуют таблицы (прил. 4), пользуясь которыми, по заданным и
находят вероятность
и, наоборот, по заданным
и
находят
.
Пример 2. Количественный признак генеральной совокупности распределен нормально. По выборке объема
найдены выборочная средняя
и исправленное среднеквадратическое отклонение
. Оценить неизвестную генеральную среднюю с помощью доверительного интервала с надежностью
.
Решение. Найдем . Пользуясь прил. 4 по
и
находим
. Найдем доверительные границы:
Итак, с надежностью неизвестный параметр
заключен в доверительном интервале
.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
Дисциплина «Статистическая обработка информации»
-
Разделы статистической обработки информации: теория оценок, теория проверки статистических гипотез
Статистика
является разделом математики, посвященным
анализу экспериментальных данных,
полученных в ходе наблюдения за некоторым
объектом. В зависимости от решаемых в
ходе анализа задач можно провести
условное разделение математической
статистики на два направления:
описательная (дескриптивная) статистика
и теория статистических выводов
(индуктивная статистика).
Описательная
(дескриптивная) статистика (англ.
descriptive statistics) решает задачи систематизации
экспериментальных данных, их наглядного
представления в виде графиков и
эмпирических зависимостей, а также
количественного анализа отдельных
статистических показателей (напр.
среднего значения, разброса, тренда и
пр.). Типичным примером применения
описательной статистики является
представление результатов соц. опроса
в виде круговых диаграмм или графики
колебания цен на нефть.
Теория
статистических выводов
(англ.
inferential statistics) решает задачи применения
выборочной информации (полученной,
например, в ходе эксперимента) для
выявления количественных и качественных
характеристик наблюдаемого объекта.
Примером может служить экспериментальная
оценка среднего времени выполнения
запроса к базе данных или попытка дать
ответ на вопрос, прием данных с какого
из доступных серверов наиболее надежен.
Приведенное
деление является в известной степени
условным, и зачастую статистическая
обработка информации начинается с
применения чисто описательных методов,
а в дальнейшем завершается применением
теории статистических выводов.
Теорию
статистических выводов, в свою очередь,
можно разделить на теорию оценивания
и
теорию проверки гипотез. Теория
оценивания призвана количественно
охарактеризовать интересующий
исследователя параметр объекта: либо
предположить его конкретное значение
(точечное оценивание), либо предположить
наиболее вероятный диапазон его значений
(интервальное оценивание). Теория
проверки гипотез позволяет на основе
экспериментальных данных
дать
ответ на заранее заданный вопрос
касательно свойств объекта (осуществить
выбор одной из альтернативных гипотез).
-
Смещенность оценки; примеры смещенных и несмещенных оценок
Так
как оценка является функцией от
нескольких случайных величин (элементов
выборки), то очевидно, что и сама оценка
является случайной величиной. Таким
образом, оценка может принимать значение
как превышающее истинное, так и, наоборот,
заниженное. Естественным желанием
является то, чтобы в
среднем
оценка совпадала с истинным значением,
т.е.:
![]()
.
Такая
оценка называется несмещенной.
Можно ввести величину
![]()
,
характеризующую величину смещения,
вносимого при использовании алгоритма
![]()
по выборке объема N:
![]()
Здесь
и далее
![]()
обозначает оценку параметра
![]()
при помощи алгоритма
по выборке объема N.
Если
![]()
,
то оценка является смещенной.
Возможны также случаи, когда для
конечного N
оценка – смещенная, но:
![]()
.
Данная
оценка называется асимптотически
несмещенной.
Т.е. при достаточно большом объеме
выборки N,
величиной смещения можно пренебречь.
Таким
образом, можно сказать, что смещение
оценки –
это разность между математическим
ожиданием оценки и истинным значением
оцениваемого параметра, несмещенная
оценка –
это оценка, имеющая нулевое смещение
при любом объеме выборки, а смещенная
оценка –
это оценка, имеющая не нулевое смещение.
Пример
несмещенной оценки:
При
анализе трафика, передаваемого с сервера
на компьютеры клиентов, производится
оценка среднего размера пакета
передаваемого по сети. Для этого из
общего потока выбирается N
пакетов,
размеры которых фиксируются и усредняются.
В данном примере случайная величина
![]()
характеризует размер пакета, искомый
параметр
— среднее значение
(т.е.
![]()
),
элементы выборки
![]()
— размеры зарегистрированных пакетов,
алгоритм оценивания

.
Проверим, является ли данная оценка
смещенной:

Таким
образом, данная оценка является
несмещенной.
Пример
смещенной оценки:
Пусть
известно, что время отклика базы данных
на запрос пользователя является
равномерно распределенной случайной
величиной в диапазоне
![]()
.
Задачей исследователя является выяснение
величины
— т.е. худшего случая, при котором задержка
максимальна. Применяется следующая
оценка:
![]()
,
т.е. максимальная задержка, зарегистрированная
в ход проведения эксперимента, состоящего
из N
запросов. Для упрощения выкладок при
проверке смещенности данной оценки
введем следующее обозначение для
максимального элемента выборки
![]()
(т.е.
![]()
и
![]()
).
Найдем интегральную функцию распределения
величины
![]()
:
![]()
Для
того чтобы максимальный элемент выборки
не превосходил x,
необходимо и достаточно, чтобы каждый
элемент выборки не превосходил x.
Обратное также верно. Тогда, учитывая
независимость случайных величин
![]()
получим:

Учитывая,
что функция
![]()
описывает равномерное распределение
в диапазоне
,
получим:

.
Воспользовавшись
формулой
![]()
получим
выражение для плотности вероятности
:

.
Тогда:

Таким
образом, данная оценка является
смещенной, причем:
![]()
Очевидно,
что
и рассмотренная оценка является
асимптотически несмещенной.
Соседние файлы в предмете Государственный экзамен
- #
- #
Содержание:
Точечные оценки:
Пусть случайная величина имеет неизвестную характеристику а. Такой характеристикой может быть, например, закон распределения, математическое ожидание, дисперсия, параметр закона распределения, вероятность определенного значения случайной величины и т.д. Пронаблюдаем случайную величину n раз и получим выборку из ее возможных значений 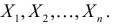
Существует два подхода к решению этой задачи. Можно по результатам наблюдений вычислить приближенное значение характеристики, а можно указать целый интервал ее значений, согласующихся с опытными данными. В первом случае говорят о точечной оценке, во втором – об интервальной.
Определение. Функция результатов наблюдений 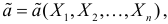
Для одной и той же характеристики можно предложить разные точечные оценки. Необходимо иметь критерии сравнения оценок, для суждения об их качестве. Оценка 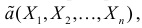 как функция случайных результатов наблюдений
как функция случайных результатов наблюдений 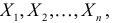 сама является случайной величиной. Значения
сама является случайной величиной. Значения 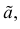 найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики
найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики 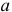 в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
Определение. Оценка называется несмещенной, если ее математическое ожидание равно оцениваемой величине: 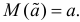 В противном случае оценку называют смещенной.
В противном случае оценку называют смещенной.
Определение. Оценка называется состоятельной, если при увеличении числа наблюдений она сходится по вероятности к оцениваемой величине, т.е. для любого сколь угодно малого 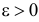
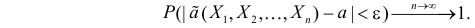
Если известно, что оценка 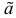 несмещенная, то для ее состоятельности достаточно, чтобы
несмещенная, то для ее состоятельности достаточно, чтобы
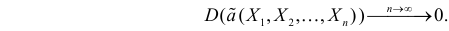
Последнее условие удобно для проверки. В качестве меры разброса значений оценки относительно  можно рассматривать величину
можно рассматривать величину 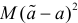 Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по
Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по 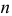 наблюдениям, то оценку называют эффективной.
наблюдениям, то оценку называют эффективной.
Следует отметить, что несмещенность и состоятельность являются желательными свойствами оценок, но не всегда разумно требовать наличия этих свойств у оценки. Например, может оказаться предпочтительней оценка хотя и обладающая небольшим смещением, но имеющая значительно меньший разброс значений, нежели несмещенная оценка. Более того, есть характеристики, для которых нет одновременно несмещенных и состоятельных оценок.
Оценки для математического ожидания и дисперсии
Пусть случайная величина имеет неизвестные математическое ожидание и дисперсию, причем 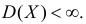 Если
Если 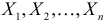 – результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений
– результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений 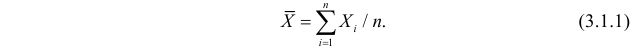
Несмещенность такой оценки следует из равенств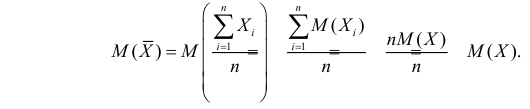
В силу независимости наблюдений 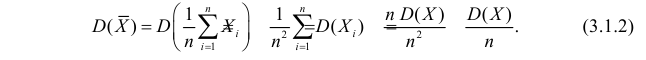
При условии 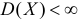 имеем
имеем 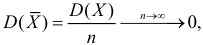 что означает состоятельность оценки
что означает состоятельность оценки 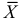 .
.
Доказано, что для математического ожидания нормально распределенной случайной величины оценка 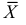 еще и эффективна.
еще и эффективна.
Оценка математического ожидания посредством среднего арифметического наблюдаемых значений наводит на мысль предложить в качестве оценки для дисперсии величину

Преобразуем величину 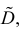 обозначая для краткости
обозначая для краткости 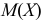 через
через 
В силу (3.1.2) имеем  Поэтому
Поэтому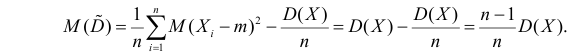
Последняя запись означает, что оценка 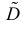 имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя
имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя 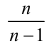 и полученную оценку обозначим через
и полученную оценку обозначим через 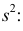
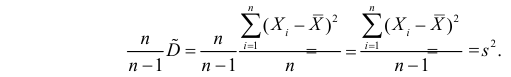
Величина
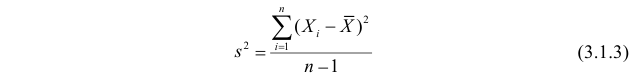
является несмещенной и состоятельной оценкой дисперсии.
Пример:
Оценить математическое ожидание и дисперсию случайной величины Х по результатам ее независимых наблюдений: 7, 3, 4, 8, 4, 6, 3.
Решение. По формулам (3.1.1) и (3.1.3) имеем 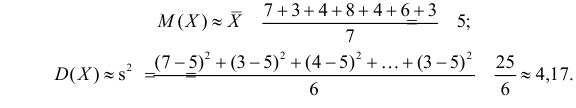
Ответ. 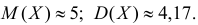
Пример:
Данные 25 независимых наблюдений случайной величины представлены в сгруппированном виде: 
Требуется оценить математическое ожидание и дисперсию этой случайной величины.
Решение. Представителем каждого интервала можно считать его середину. С учетом этого формулы (3.1.1) и (3.1.3) дают следующие оценки: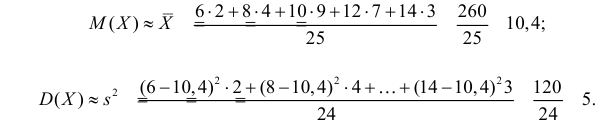
Ответ. 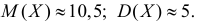
Метод наибольшего правдоподобия для оценки параметров распределений
В теории вероятностей и ее приложениях часто приходится иметь дело с законами распределения, которые определяются некоторыми параметрами. В качестве примера можно назвать нормальный закон распределения 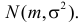 Его параметры
Его параметры 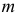 и
и 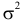 имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью
имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью 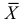 и
и 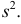 В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
Пусть случайная величина Х имеет функцию распределения 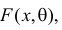 причем тип функции распределения F известен, но неизвестно значение параметра
причем тип функции распределения F известен, но неизвестно значение параметра 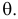 По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
Продемонстрируем идею метода наибольшего правдоподобия на упрощенном примере. Пусть по результатам наблюдений, отмеченных на рис. 3.1.1 звездочками, нужно отдать предпочтение одной из двух функций плотности вероятности 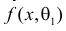 или
или 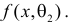
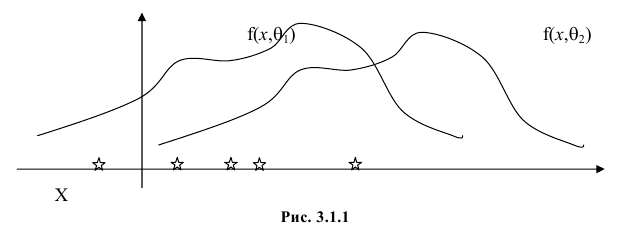
Из рисунка видно, что при значении параметра 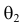 такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же
такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же 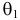 эти результаты наблюдений вполне возможны. Поэтому значение параметра
эти результаты наблюдений вполне возможны. Поэтому значение параметра 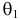 более правдоподобно, чем значение
более правдоподобно, чем значение 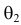 . Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
. Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
Этот принцип приводит к следующему способу действий. Пусть закон распределения случайной величины Х зависит от неизвестного значения параметра 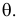 Обозначим через
Обозначим через 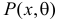 для непрерывной случайной величины плотность вероятности в точке
для непрерывной случайной величины плотность вероятности в точке 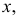 а для дискретной случайной величины – вероятность того, что
а для дискретной случайной величины – вероятность того, что 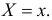 Если в
Если в 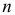 независимых наблюдениях реализовались значения случайной величины
независимых наблюдениях реализовались значения случайной величины 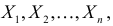 то выражение
то выражение 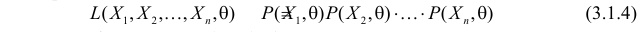
называют функцией правдоподобия. Величина 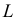 зависит только от параметра
зависит только от параметра 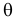 при фиксированных результатах наблюдений
при фиксированных результатах наблюдений 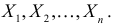 При каждом значении параметра
При каждом значении параметра 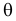 функция
функция 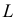 равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства
равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства 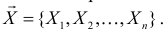
Сформулированный принцип предлагает в качестве оценки значения параметра выбрать такое 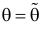 при котором принимает наибольшее значение. Величина
при котором принимает наибольшее значение. Величина 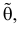 будучи функцией от результатов наблюдений
будучи функцией от результатов наблюдений 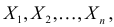 называется оценкой наибольшего правдоподобия.
называется оценкой наибольшего правдоподобия.
Во многих случаях, когда дифференцируема, оценка наибольшего правдоподобия находится как решение уравнения 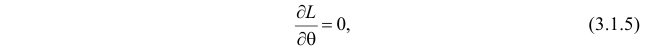
которое следует из необходимого условия экстремума. Поскольку 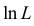 достигает максимума при том же значении
достигает максимума при том же значении 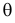 , что и , то можно решать относительно
, что и , то можно решать относительно 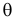 эквивалентное уравнение
эквивалентное уравнение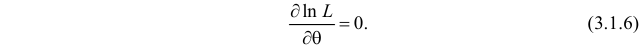
Это уравнение называют уравнением правдоподобия. Им пользоваться удобнее, чем уравнением (3.1.5), так как функция равна произведению, а – сумме, а дифференцировать проще.
Если параметров несколько (многомерный параметр), то следует взять частные производные от функции правдоподобия по всем параметрам, приравнять частные производные нулю и решить полученную систему уравнений.
Оценку, получаемую в результате поиска максимума функции правдоподобия, называют еще оценкой максимального правдоподобия.
Известно, что оценки максимального правдоподобия состоятельны. Кроме того, если для q существует эффективная оценка, то уравнение правдоподобия имеет единственное решение, совпадающее с этой оценкой. Оценка максимального правдоподобия может оказаться смещенной.
Метод моментов
Начальным моментом 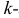 го порядка случайной величины Х называется математическое ожидание
го порядка случайной величины Х называется математическое ожидание 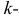 й степени этой величины, т.е.
й степени этой величины, т.е. 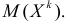 Само математическое ожидание считается начальным моментом первого порядка.
Само математическое ожидание считается начальным моментом первого порядка.
Центральным моментом 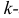 го порядка называется
го порядка называется 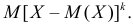 Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Для оценки параметров распределения по методу моментов находят на основе опытных данных оценки моментов в количестве, равном числу оцениваемых параметров. Эти оценки приравнивают к соответствующим теоретическим моментам, величины которых выражены через параметры. Из полученной системы уравнений можно определить искомые оценки.
Например, если Х имеет плотность распределения 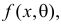 то
то 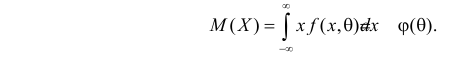
Если воспользоваться величиной 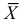 как оценкой для
как оценкой для 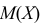 на основе опытных данных, то оценкой по методу моментов будет решение уравнения
на основе опытных данных, то оценкой по методу моментов будет решение уравнения 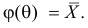
Пример:
Найти оценку параметра показательного закона распределения по методу моментов.
Решение. Плотность вероятности показательного закона распределения имеет вид 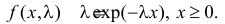 Поэтому
Поэтому 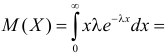
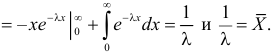 Откуда
Откуда 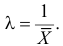
Ответ. 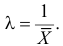
Пример:
Пусть имеется простейший поток событий неизвестной интенсивности 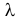 . Для оценки параметра
. Для оценки параметра 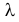 проведено наблюдение потока и зарегистрированы
проведено наблюдение потока и зарегистрированы 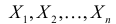 – длительности
– длительности 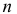 последовательных интервалов времени между моментами наступления событий. Найти оценку для
последовательных интервалов времени между моментами наступления событий. Найти оценку для 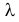 .
.
Решение. В простейшем потоке интервалы времени между последовательными моментами наступления событий потока имеют показательный закон распределения 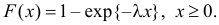 Так как плотность вероятности показательного закона распределения равна
Так как плотность вероятности показательного закона распределения равна 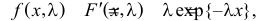 то функция правдоподобия (3.1.4) имеет вид
то функция правдоподобия (3.1.4) имеет вид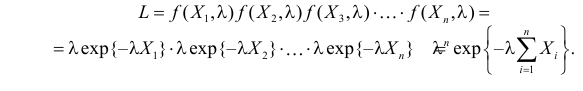
Тогда 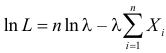 и уравнение правдоподобия
и уравнение правдоподобия 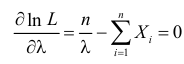 имеет решение
имеет решение 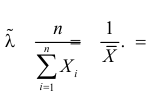
При таком значении 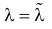 функция правдоподобия действительно достигает наибольшего значения, так как
функция правдоподобия действительно достигает наибольшего значения, так как 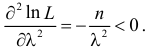
Ответ. 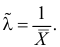
Определение. Пусть 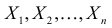 – результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:
– результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:

В этой записи 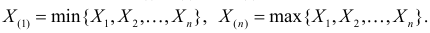
Величины 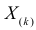 называют порядковыми статистиками.
называют порядковыми статистиками.
Пример:
Случайная величина Х имеет равномерное распределение на отрезке 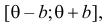 где
где 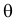 и
и 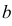 неизвестны. Пусть
неизвестны. Пусть 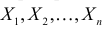 – результаты независимых наблюдений. Найти оценку параметра .
– результаты независимых наблюдений. Найти оценку параметра .
Решение. Функция плотности вероятности величины Х имеет вид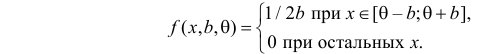
В этом случае функция правдоподобия 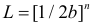 от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в
от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в 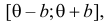 поэтому можно записать:
поэтому можно записать:
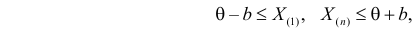
где 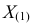 – наименьший, а
– наименьший, а 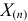 – наибольший из результатов наблюдений. При минимально возможном
– наибольший из результатов наблюдений. При минимально возможном
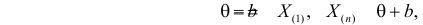
откуда 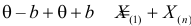 или
или 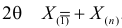
Оценкой наибольшего правдоподобия для параметра будет величина
Ответ. 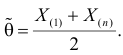
Пример:
Случайная величина X имеет функцию распределения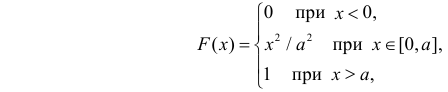
где 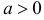 неизвестный параметр.
неизвестный параметр.
Пусть 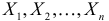 – результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра
– результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра 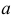 и найти оценку для M(X).
и найти оценку для M(X).
Решение. Для построения функции правдоподобия найдем сначала функцию плотности вероятности
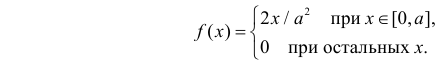
Тогда функция правдоподобия: 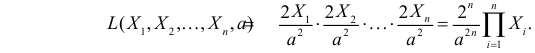
Логарифмическая функция правдоподобия: 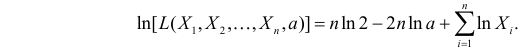
Уравнение правдоподобия

не имеет решений. Критических точек нет. Наибольшее и наименьшее значения находятся на границе допустимых значений 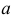 .
.
По виду функции можно заключить, что значение тем больше, чем меньше величина . Но не может быть меньше 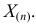 Поэтому наиболее правдоподобное значение
Поэтому наиболее правдоподобное значение 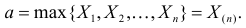
Так как 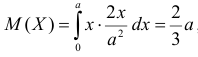 , то оценкой наибольшего правдоподобия для
, то оценкой наибольшего правдоподобия для 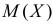 будет величина
будет величина 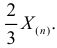
Ответ. 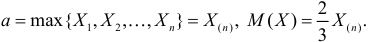
Пример:
Случайная величина Х имеет нормальный закон распределения 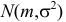 c неизвестными параметрами
c неизвестными параметрами 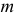 и
и 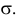 По результатам независимых наблюдений
По результатам независимых наблюдений 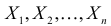 найти наиболее правдоподобные значения этих параметров.
найти наиболее правдоподобные значения этих параметров.
Решение. В соответствии с (3.1.4) функция правдоподобия имеет вид 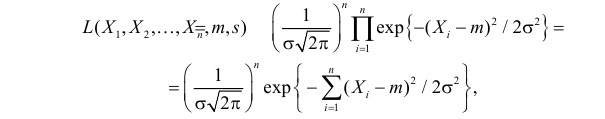
а логарифмическая функция правдоподобия: 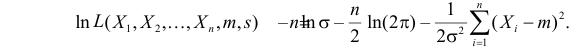
Необходимые условия экстремума дают систему двух уравнений: 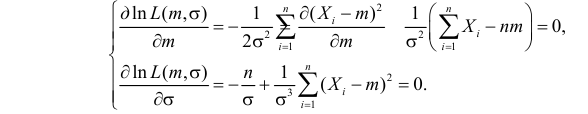
Решения этой системы имеют вид: 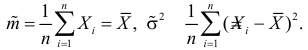
Отметим, что обе оценки являются состоятельными, причем оценка для 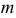 несмещенная, а для
несмещенная, а для 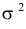 смещенная (сравните с формулой (3.1.3)).
смещенная (сравните с формулой (3.1.3)).
Ответ. 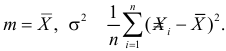
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. 1) Число экспериментальных данных вычисляется по формуле:
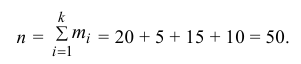
Значит, объем выборки n = 50.
2) Вычислим среднее арифметическое значение эксперимента:
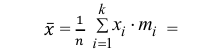
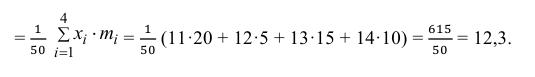
Значит, найдена оценка математического ожидания 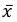 = 12,3.
= 12,3.
3) Вычислим исправленную выборочную дисперсию:
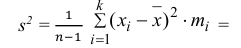
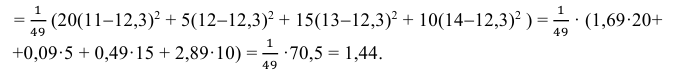
Значит, найдена оценка дисперсии: 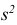 = 1,44.
= 1,44.
5) Вычислим оценку среднего квадратического отклонения:
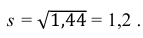
Ответ: 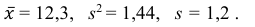
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. По формуле
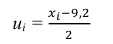
перейдем к условным вариантам:

Для них произведем расчет точечных оценок параметров:
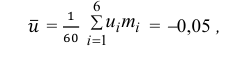
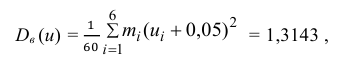
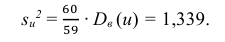
Следовательно, вычисляем искомые точечные оценки:
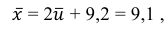
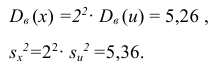
Ответ: 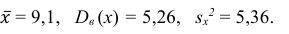
Пример:
По данным эксперимента построен интервальный статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения.
Решение. 1) От интервального ряда перейдем к статистическому ряду, заменив интервалы их серединами 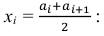

2) Объем выборки вычислим по формуле:
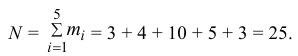
3) Вычислим среднее арифметическое значений эксперимента:
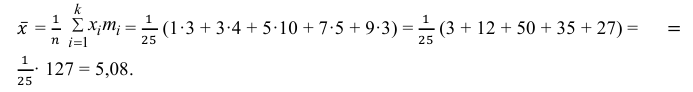
3) Вычислим исправленную выборочную дисперсию:
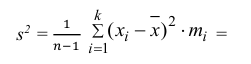
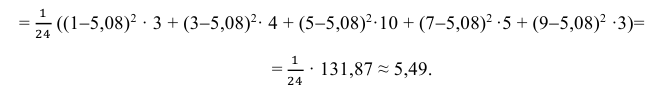
Можно было воспользоваться следующей формулой:
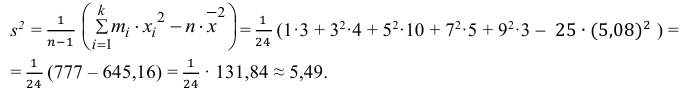
5) Вычислим оценку среднего квадратического отклонения:
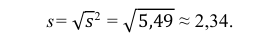
Ответ: 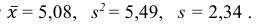
Пример:
Найти доверительный интервал с надежностью 0,95 для оценки математического ожидания M(X) нормально распределенной случайной величины X, если известно среднее квадратическое отклонение σ = 2, оценка математического ожидания 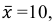 объем выборки n = 25.
объем выборки n = 25.
Решение. Доверительный интервал для истинного математического ожидания с доверительной вероятностью 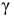 = 0,95 при известной дисперсии σ находится по формуле:
= 0,95 при известной дисперсии σ находится по формуле:
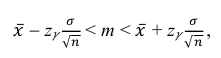
где m = M(X) – истинное математическое ожидание; 𝑥̅ − оценка M(X) по выборке; n – объем выборки; 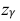 – находится по доверительной вероятности
– находится по доверительной вероятности 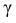 = 0,95 из равенства:
= 0,95 из равенства:
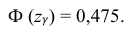
Из табл. П 2.2 приложения 2 находим: 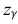 = 1,96. Следовательно, найден доверительный интервал для M(X):
= 1,96. Следовательно, найден доверительный интервал для M(X):
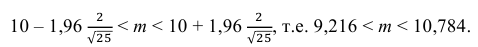
Ответ: (9,216 ; 10,784).
Пример:
По данным эксперимента построен статистический ряд:

Найти доверительный интервал для математического ожидания M (X) с надежностью 0,95.
Решение. Воспользуемся формулой для доверительного интервала математического ожидания при неизвестной дисперсии:
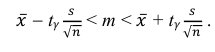
где n – объем выборки; 𝑥̅ оценка M(X); s – оценка среднего квадратического отклонения; 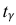 − находится по доверительной вероятности
− находится по доверительной вероятности 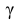 = 0,95.
= 0,95.
По числам 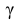 = 0,95 и n = 20 находим:
= 0,95 и n = 20 находим: 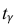 = 2,093.
= 2,093.
Теперь вычисляем оценки для M(X) и D(X):
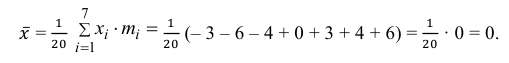
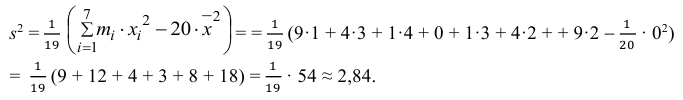
Следовательно, s ≈ 1,685. Поэтому искомый доверительный интервал математического ожидания задается формулой:
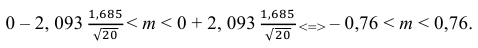
Ответ: (– 0,76; 0,76).
Пример:
По данным десяти независимых измерений найдена оценка квадратического отклонения 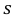 = 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
= 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
Решение. Задача сводится к нахождению доверительного интервала для истинного квадратического отклонения, так как точность прибора характеризуется средним квадратическим отклонением случайных ошибок измерений.
Доверительный интервал для среднего квадратического отклонения находим по формуле:
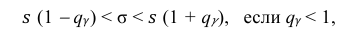
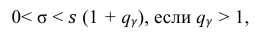
где 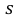 = 0,5 − оценка среднего квадратического отклонения;
= 0,5 − оценка среднего квадратического отклонения; 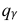 – число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности
– число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности 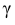 = 0,99 и заданному объему выборки n = 10.
= 0,99 и заданному объему выборки n = 10.
Находим: 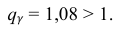
Тогда можно записать:
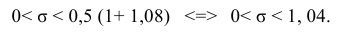
Ответ: (0; 1,04).
- Доверительный интервал для вероятности события
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Системы случайных величин
- Вероятность и риск
- Определения вероятности событий
- Предельные теоремы теории вероятностей
Содержание:
- Точечные статистические оценки параметров генеральной совокупности
- Методы определения точечных статистических оценок
- Законы распределения вероятностей для
- Интервальные статистические оценки для параметров генеральной совокупности
- Построение доверчивого интервала для при известном значении с заданной надежностью
- Построение доверительного интервала для при неизвестном значении из заданной надежности
- Построение доверительных интервалов с заданной надежностью для
- Построение доверительного интервала для генеральной совокупности с заданной надежностью
- Построение доверительного интервала для с помощью неравенства Чебишова с заданной надежностью
Информация, которую получили на основе обработки выборки про признак генеральной совокупности, всегда содержит определенные погрешности, поскольку выборка содержит только незначительную часть от нее  то есть объем выборки значительно меньше объема генеральной совокупности.
то есть объем выборки значительно меньше объема генеральной совокупности.
Потому, следует организовать выборку так, чтобы эта информация была более полной (выборка может быть репрезентабельной) и обеспечивала с наибольшей степенью доверия о параметрах генеральной совокупности ил закон распределение ее признака.
Параметры генеральной совокупности  являются величинами постоянными, но их числовые значения неизвестные. Эти параметры оцениваются параметрами выборки:
являются величинами постоянными, но их числовые значения неизвестные. Эти параметры оцениваются параметрами выборки:  которые получаются при обработке выборки. Они являются величинами непредсказуемыми, то есть случайными. Схематично это можно показать так (рис. 115).
которые получаются при обработке выборки. Они являются величинами непредсказуемыми, то есть случайными. Схематично это можно показать так (рис. 115).

Тут через  обозначен оценочный параметр генеральной совокупности, а через
обозначен оценочный параметр генеральной совокупности, а через  — его статистическую оценку, Которую называют еще статистикой. При этом
— его статистическую оценку, Которую называют еще статистикой. При этом  а — случайная величина, что имеет полный закон распределения вероятностей. заметим, что для реализации выборки каждую ее варианту рассматривают как случайную величину, что имеет закон распределения вероятностей признака генеральной совокупности с соответственными числовыми характеристиками:
а — случайная величина, что имеет полный закон распределения вероятностей. заметим, что для реализации выборки каждую ее варианту рассматривают как случайную величину, что имеет закон распределения вероятностей признака генеральной совокупности с соответственными числовыми характеристиками:

Точечные статистические оценки параметров генеральной совокупности
Статистическая оценка  , которая обозначается одном числом, называется точечной. Возьмем во внимание, что
, которая обозначается одном числом, называется точечной. Возьмем во внимание, что  является случайной величиной, точечная статистическая оценка может быть смещенной или несмещенной: когда математическое надежда этой оценки точно равны оценочному параметру
является случайной величиной, точечная статистическая оценка может быть смещенной или несмещенной: когда математическое надежда этой оценки точно равны оценочному параметру  а именно:
а именно:

то  называется несмещенной; в противоположном случае, то есть когда
называется несмещенной; в противоположном случае, то есть когда

точечная статистическая оценка  называется смещенной относительно параметра генеральной совокупности
называется смещенной относительно параметра генеральной совокупности 
Разница

называется смещением статистической оценки 
Оценочный параметр может иметь несколько точечных несмещенных статистических оценок, что можно изобразить так (рис. 116):

Например, пусть  которая имеет две несмещенные точечные статистические оценки —
которая имеет две несмещенные точечные статистические оценки —  и
и  Тогда плотность вероятностей для
Тогда плотность вероятностей для 
 имеют такой вид (рис. 117):
имеют такой вид (рис. 117):

Из графиков плотности видим, что оценка  сравнено с оценкой
сравнено с оценкой  имеет то преимущество, что около параметра
имеет то преимущество, что около параметра 
 Отсюда получается, что оценка чаще получает значение в этой области, чем оценка
Отсюда получается, что оценка чаще получает значение в этой области, чем оценка 
Но на «хвостах» распределений имеет другую картину: большие отклонения от  будут наблюдаться для статистической оценки , чаще, чем для Потому, сравнивая дисперсии статистических
будут наблюдаться для статистической оценки , чаще, чем для Потому, сравнивая дисперсии статистических  как меру рассеивания, видим, что
как меру рассеивания, видим, что  имеет меньшую дисперсию, чем оценка .
имеет меньшую дисперсию, чем оценка .
Точечная статистическая оценка называется эффективной, когда при заданном объеме выборки она имеет минимальную дисперсию. Следует, оценка будет несмещенной и эффективной.
Точечная статистическая оценка называется основой, если в случае неограниченного увеличения объема выборки  приближается к оценке параметра , а именно:
приближается к оценке параметра , а именно:

Методы определения точечных статистических оценок
Существует три метода определения точечных статистических оценок для параметров генеральной совокупности.
Метод аналогий. Этот метод основывается на том, что для параметров генеральной совокупности выбирают такие же параметры выборки, то есть для оценки  выбирают аналогичные статистики —
выбирают аналогичные статистики — 
Метод наименьших квадратов. Согласно с этим методом статистические оценки обозначаются с условием минимизации суммы квадратов отклонений вариант выборки от статистической оценки .
Итак, используя метод наименьших квадратов, можно, например, обозначить статистическую оценку для  Для этого воспользуемся функцией
Для этого воспользуемся функцией  Используя условие экстремума, получим:
Используя условие экстремума, получим:

Отсюда, для  точечной статистической оценкой будет
точечной статистической оценкой будет  — выборочная средняя.
— выборочная средняя.
Метод максимальной правдоподобности. Этот метод занимает центральное место в теории статистической оценки параметров  На него в свое время обратил внимание К. Гаусс, а разработал его Р. Фишер. Этот метод рассмотрим подробнее.
На него в свое время обратил внимание К. Гаусс, а разработал его Р. Фишер. Этот метод рассмотрим подробнее.
Пусть признак генеральной совокупности  обозначается только одном параметром
обозначается только одном параметром  и имеет плотность вероятности
и имеет плотность вероятности  В случае реализации выборки с вариантами
В случае реализации выборки с вариантами  плотность вероятности выборки будет такой:
плотность вероятности выборки будет такой:

В этом варианте рассматриваются как независимые случайные величины, которые имеют один и тот же закон распределения, что ее признак генеральной совокупности .
Суть этого метода состоит в том, что фиксируя значение вариант , обозначают такие значение параметра  , при котором функция
, при котором функция  максимизуется. Она называется функцией максимальной правдоподобности и обозначается так:
максимизуется. Она называется функцией максимальной правдоподобности и обозначается так: 
Например, когда признак генеральной совокупности  имеет нормальный закон распределения, то функция максимальной правдоподобности приобретет такой вид:
имеет нормальный закон распределения, то функция максимальной правдоподобности приобретет такой вид:

При этом статистические оценки  выбирают и ее значения, по которых заданная выборка будет верной, то есть функция
выбирают и ее значения, по которых заданная выборка будет верной, то есть функция  достигает максимума.
достигает максимума.
На практике удобно от функции перейти к ее логарифму, а именно:

согласно с необходимым условием экстремума для этой функции получим:

Из первого уравнения системы  получим:
получим:

из уравнение системы получим:

Следует, для  точечной функции статистической оценкой будет
точечной функции статистической оценкой будет  для
для 
Свойства  Исправленная дисперсия, исправленное среднее квадратичное отклонение. Точечной несмещенной статистической оценкой для
Исправленная дисперсия, исправленное среднее квадратичное отклонение. Точечной несмещенной статистической оценкой для  будет
будет 
И на самом деле,
 учитывая то. что
учитывая то. что 

Следует, 
Проверим на несмещенность статистической оценки 



Таким образом, получим 
Следует,  будет точечной смещенной статистической оценкой для
будет точечной смещенной статистической оценкой для  , где
, где  — коэффициент смещения, который уменьшается с увеличением объема выборки
— коэффициент смещения, который уменьшается с увеличением объема выборки 
Когда умножить на  то получим
то получим 
Тогда

Следует,  будут точеной несмещенной статистической оценкой для
будут точеной несмещенной статистической оценкой для  Ее называли исправленной дисперсией и обозначили через
Ее называли исправленной дисперсией и обозначили через 
Отсюда точечной несмещенной статистической оценкой для  будет исправленная дисперсия
будет исправленная дисперсия  или
или

Величину

называют исправленным средним квадратичным отклонением.
Исправленное среднее квадратичное отклонение, следует подчеркнуть, будет смещенной точечной статистической оценкой для  поскольку
поскольку

где  является ступенью свободы;
является ступенью свободы;
 — коэффициенты смещения.
— коэффициенты смещения.
Пример. 200 однотипных деталей были отданы на шлифование. Результаты измерения приведены как дискретное статистическое распределение, подан в табличной форме:

Найти точечные смещенные статистические оценки для 

Решение. Поскольку точечной несмещенной оценки для  будет
будет  то вычислим
то вычислим

Для обозначение точечной несмещенной статистической оценки для  вычислим
вычислим 


тогда точечная несмещенная статистическая оценка для  равно:
равно:

Пример. Граничная нагрузка на стальной болт  что измерялась в лабораторных условий, задано как интервальное статистическое распределение:
что измерялась в лабораторных условий, задано как интервальное статистическое распределение:

Обозначить точечные несмещенные статистические оценки для 
Решение. Для обозначения точечных несмещенных статистических распределений к дискретному, который приобретает такой вид:

Вычислим 

Следует, точечная несмещенная статистическая оценка для 

Для обозначения  вычислим
вычислим 

Отсюда точечная несмещенная статистическая оценка для  будет
будет 
Законы распределения вероятностей для 

Как уже обозначалось, числовые характеристики выборки являются случайными величинами, что имеют определенные законы распределения вероятностей. Так,  (выборочная средняя) на основании центральной граничной теоремы теории вероятностей (теоремы Ляпунова) имеем нормальный закон распределения с числовыми характеристиками
(выборочная средняя) на основании центральной граничной теоремы теории вероятностей (теоремы Ляпунова) имеем нормальный закон распределения с числовыми характеристиками

следует, случайная величина имеет закон распределения 
Чтобы обозначить закон распределения для  необходимо выявить связь между
необходимо выявить связь между  и распределением
и распределением  .
.
Пусть признак генеральной совокупности  имеет нормальный закон распределения
имеет нормальный закон распределения  . При реализации выборки каждую из вариант
. При реализации выборки каждую из вариант  рассматривают как случайную величину. то также имеет закон распределения . При этом вариант выборки является независимым, то есть
рассматривают как случайную величину. то также имеет закон распределения . При этом вариант выборки является независимым, то есть  а случайная величина
а случайная величина  соответственно имеет закон распределения
соответственно имеет закон распределения 
Рассмотрим случай, когда варианты выборки имеют частоты  тогда
тогда

Перейдем от случайных величин  к случайным величинам
к случайным величинам  которые линейно выражаются через
которые линейно выражаются через  а именно:
а именно:

Поскольку случайные величины  будут линейными комбинациями случайных величин
будут линейными комбинациями случайных величин  то
то  тоже имеют нормальный закон распределения с числовыми характеристиками:
тоже имеют нормальный закон распределения с числовыми характеристиками:


Следует, случайные величины  имеют закон распределения
имеют закон распределения 
Построим матрицу  элементы которой будут коэффициенты при
элементы которой будут коэффициенты при  в линейных зависимостях для
в линейных зависимостях для 

Транспортируем матрицу получим:

Если перемножить матрицы  и
и  то получим:
то получим:

где  будет единичная матрица.
будет единичная матрица.
Следует, случайные величины  обозначены ортогональными преобразованиями случайных величин
обозначены ортогональными преобразованиями случайных величин  В векторной — матричной форме это можно записать так:
В векторной — матричной форме это можно записать так:
Из курса алгебры известно, что во время ортогональных преобразований вектора сохраняется его длина, то есть

Тогда из формулы для  получим:
получим:

Поскольку  далее вычислим:
далее вычислим:

Следует, получим 
Когда поделим левую и правую часть  на
на  то получим,
то получим,

Поскольку  имеет закон распределения
имеет закон распределения  то
то  получим закон распределения
получим закон распределения  то есть нормированный нормальный закон.
то есть нормированный нормальный закон.
То случайная величина

получим распределение  из
из  ступенями свободы.
ступенями свободы.
Отсюда получается, что случайная величина  получим распределение
получим распределение  из
из  ступенями свободы.
ступенями свободы.
Таким образом, приведена: случайная величина  тут символ
тут символ  нужно читать «распределена как»;
нужно читать «распределена как»;
случайная величина 
случайная величина 
Интервальные статистические оценки для параметров генеральной совокупности
Точечные статистические оценки  являются случайными величинами, а потому приближенная замена
являются случайными величинами, а потому приближенная замена  на часто приводит к существенным погрешностям, особенно когда объем выборки не большой. В этом случае используют интервальные статистические оценки.
на часто приводит к существенным погрешностям, особенно когда объем выборки не большой. В этом случае используют интервальные статистические оценки.
Статистическая оценка, что обозначается двумя числами, концами интервалов, называется интервальной.
Разница между статистической оценкой  и ее оценкой параметром
и ее оценкой параметром  взята с абсолютным значением, называется точностью оценки, а именно:
взята с абсолютным значением, называется точностью оценки, а именно:

где  является точностью оценки.
является точностью оценки.
Поскольку является случайной величиной, то и будет случайной, потому неравенство  справедливо с определенной вероятностью.
справедливо с определенной вероятностью.
Вероятность, с которой берется неравенство  , то есть
, то есть

называется надежностью
Равенство  можно записать так:
можно записать так:

Интервал  что покрывает оценочный параметр
что покрывает оценочный параметр  генеральной совокупности с заданной надежностью
генеральной совокупности с заданной надежностью  называют доверчивым.
называют доверчивым.
Построение доверчивого интервала для при известном значении с заданной надежностью
 при известном значении
при известном значении  с заданной надежностью
с заданной надежностью 
Пусть признак  генеральной совокупностью имеет нормальный закон распределению. Построим доверительный интервал для
генеральной совокупностью имеет нормальный закон распределению. Построим доверительный интервал для  зная числовое значение среднего квадратичному отклонению генеральной совокупности
зная числовое значение среднего квадратичному отклонению генеральной совокупности  с заданной надежностью
с заданной надежностью  Поскольку
Поскольку  как точечная несмещенная статистическая оценка для
как точечная несмещенная статистическая оценка для  имеет нормальный закон распределения с числовыми характеристиками
имеет нормальный закон распределения с числовыми характеристиками 
 то воспользовавшись
то воспользовавшись  получим
получим

Случайная величина  имеет нормальный закон распределения с числовыми характеристиками
имеет нормальный закон распределения с числовыми характеристиками

Потому  будет нормированный нормальный закон распределения
будет нормированный нормальный закон распределения 
Отсюда равенство  можно записать, обозначив
можно записать, обозначив  так;
так;

или

Согласно с формулой нормированного нормального закона

для  она получает такой вид:
она получает такой вид:

Из равенства  находим аргументы
находим аргументы  а именно:
а именно:

Аргумент  находим значение функции Лапласа, которая равна
находим значение функции Лапласа, которая равна  по таблице (дополнение 2).
по таблице (дополнение 2).
Следует, доверительный интервал равен:

что можно изобразить условно на рисунке 118.

Величина  называется точностью оценки, или погрешностью выборки.
называется точностью оценки, или погрешностью выборки.
Пример. Измеряя 40 случайно отобранных после изготовления деталей, нашли выборку средней, что равна 15 см. Из надежности  построить доверительный интервал для средней величины всей партии деталей, если генеральная дисперсия равна
построить доверительный интервал для средней величины всей партии деталей, если генеральная дисперсия равна 
Решение. Для построенного доверчивого интервала необходимо найти: 
Из условия задачи имеем: 
 Величина
Величина  вычисляется из уравнения
вычисляется из уравнения

 {с таблицей значения функции Лапласа}.
{с таблицей значения функции Лапласа}.
Найдем числовые значения концов доверчивого интервала:

Таким образом, получим: 
Следует, с надежностью  (99% гарантии) оценочный параметр
(99% гарантии) оценочный параметр  пребывает в середина интервала
пребывает в середина интервала 
Пример. Имеем такие данные про размеры основных фондов (в млн руб.) на 30-ти случайно выбранных предприятий:

построить интервальное статистическое распределение с длиной шага  млн рублей.
млн рублей.
С надежностью  найти доверительный интеграл для
найти доверительный интеграл для  если
если  млн рублей.
млн рублей.
Решение. Интервальное статистическое распределение будет таким:

Для обозначение  необходимо построить дискретное статистическое распределение, что имеет такой вид:
необходимо построить дискретное статистическое распределение, что имеет такой вид:

Тогда

 млн рублей.
млн рублей.
Для построения доверительного интервала с заданной надежностью  необходимо найти
необходимо найти 

Вычислим концы интервала:
 млн руб.
млн руб.
 млн руб.
млн руб.
Следует, доверительный интервал для  будет
будет 
Пример. Какое значение может получит надежность оценки  чтобы за объем выборки
чтобы за объем выборки  погрешность ее не превышала
погрешность ее не превышала  при
при 
Решение. Обозначим погрешность выборки

Далее получим:

как видим, надежность мала.
Пример. Обозначить объем выборки  по которому погрешность
по которому погрешность  гарантируется с вероятностью
гарантируется с вероятностью  если
если 
Решение. По условию задачи  Поскольку
Поскольку  то получим:
то получим:  Величину
Величину  находим из равенства
находим из равенства  Тогда
Тогда 
Построение доверительного интервала для при неизвестном значении из заданной надежности
 при неизвестном значении
при неизвестном значении  из заданной надежности
из заданной надежности 
Для малых выборок, с какими сталкиваемся, исследуя разные признаки в техники или сельском хозяйстве, для оценки  при неизвестном значении
при неизвестном значении  невозможно воспользоваться нормальным законом распределения. Потому для построения доверительного интервала используется случайная величина.
невозможно воспользоваться нормальным законом распределения. Потому для построения доверительного интервала используется случайная величина.

что имеет распределение Стьюдента с  ступенями свободы.
ступенями свободы.
Тогда  получает вид:
получает вид:

поскольку  для распределения Стьюдента является функцией четной.
для распределения Стьюдента является функцией четной.
Вычислив по данному статистическому распределению 
 и обозначив по таблице распределения Стьюдента значения
и обозначив по таблице распределения Стьюдента значения  построим доверительный интервал
построим доверительный интервал

Тут  вычислим по заданной надежностью
вычислим по заданной надежностью  и числом степеней свободы
и числом степеней свободы  по таблице (дополнение 3).
по таблице (дополнение 3).
Пример. Случайно выбранная партия из двадцати примеров была испытана относительно срока безотказной работы каждого из них  Результаты испытаний приведено в виде дискретного статистического распределения:
Результаты испытаний приведено в виде дискретного статистического распределения:

С надежностью  построить доверительный интервал для
построить доверительный интервал для  (среднего времени безотказной работы прибора.)
(среднего времени безотказной работы прибора.)
Решение. Для построения доверительного интеграла необходимо найти среднее выборочное и исправленное среднее квадратичное отклонение.
Вычислим 

следует, получили  часов.
часов.
Обозначим 

следует, 
Исправленное среднее квадратичное отклонение равно:
 часов.
часов.
По таблице значений  (дополнение 3) распределение Стьюдента по заданной надежностью
(дополнение 3) распределение Стьюдента по заданной надежностью  и числом ступеней свободы
и числом ступеней свободы  находим значение
находим значение 
Вычислим концы доверительного интервала:
 час.
час.
 час.
час.
Следует, с надежностью  можно утверждать, что
можно утверждать, что  будет содержится в интервале
будет содержится в интервале

При больших объемах выборки, а именно:  на основании центральной граничной теоремы теории вероятностей (теоремы Ляпунова) распределение Стьюдента приближается к нормальному закону. В этом случае
на основании центральной граничной теоремы теории вероятностей (теоремы Ляпунова) распределение Стьюдента приближается к нормальному закону. В этом случае  находиться по таблице значений функции Лапласа.
находиться по таблице значений функции Лапласа.
Пример. В таблице приведены отклонения диаметров валиков, изготовленных на станке, от номинального размера:

с надежностью  построить доверительный интервал для
построить доверительный интервал для 
Решение. Для постройки доверительного интервала необходимо найти 
Для этого от интегрального статистического распределения, приведенного в условии задачи, необходимо перейти к дискретному, а именно:

Вычислим 
 поскольку
поскольку 

Следует, 
Обозначим 

Вычислим исправленное среднее квадратичное отклонение 

Учитывая на большой  объем выборки можно считать, что распределение Стьюдента близкий к нормальному закону. Тогда по таблице значения функции Лапласа
объем выборки можно считать, что распределение Стьюдента близкий к нормальному закону. Тогда по таблице значения функции Лапласа

Вычислим концы интервалов:


Итак, доверчивый интервал для среднего значения отклонений будет таким: 
Отсюда с надежностью  можно утверждать, что
можно утверждать, что
Построение доверительных интервалов с заданной надежностью для
 для
для 
В случае, если признак  имеем нормальный закон распределения, для построения доверительного интервала с заданной надежностью
имеем нормальный закон распределения, для построения доверительного интервала с заданной надежностью  для
для  используем случайную величину
используем случайную величину

что имеет распределение  из
из  ступенями свободы.
ступенями свободы.
Поскольку случайные действия
 и
и 
являются равновероятными, то есть их вероятности равны  получим:
получим:

Подставляя в 
 получим
получим

Следует, доверительный интервал для  получит вид:
получит вид:

Тогда доверительный интервал для  получается из
получается из  и будет таким:
и будет таким:

Значения  находятся по таблице (дополнение 4) согласно с равенствами:
находятся по таблице (дополнение 4) согласно с равенствами:

где 
Пример. Проверена партия однотипных телевизоров  на чувствительность к видео-программ
на чувствительность к видео-программ  данные проверки приведены как дискретное статистическое распределение:
данные проверки приведены как дискретное статистическое распределение:

С надежностью  построить доверительные интервалы для
построить доверительные интервалы для 
Решение. Для построении доверительных интервалов необходимо найти значения 
Вычислим значения 
 так как
так как 

Вычислим 


Следует 
Исправленная дисперсия и исправленное среднее квадратичное отклонение равны:

Поскольку  то согласно с
то согласно с  находим значения
находим значения  а именно:
а именно:

По таблице (дополнение 4) находим:

вычислим концы доверительного интервала для 


Следует, доверительный интеграл для  будет таким:
будет таким:

Доверительный интервал для  станет
станет

Доверительный интервал для  можно построить с заданной надежностью
можно построить с заданной надежностью  взяв распределение
взяв распределение 
Поскольку

то равенство  можно записать так:
можно записать так:

или

Обозначив  получим
получим

чтобы найти  возьмем случайную величину
возьмем случайную величину

что имеет распределение 
Учитывая то, что события
 и
и 
при  является равновероятными, получим:
является равновероятными, получим:

Если умножить все члены двойного неравенства 
 на
на  то получим:
то получим:

Отсюда получим:

Из уравнения  по заданной надежностью
по заданной надежностью  и объемом выборки
и объемом выборки  находим по таблице (дополнение 5) значение величины
находим по таблице (дополнение 5) значение величины 
Доверительный интервал будет таким:

Пример. С надежностью  построить доверительный интервал вычислим значения
построить доверительный интервал вычислим значения  по таблице (дополнение 5).
по таблице (дополнение 5). 
Обозначим концы интервала:

Следует, доверительный интервал для  с надежностью
с надежностью  будет такой
будет такой

Построение доверительного интервала для генеральной совокупности с заданной надежностью
 генеральной совокупности с заданной надежностью
генеральной совокупности с заданной надежностью 
Как величина, полученная по результатам выборки,  является случайной и представляет собой точечную несмещенную статистическую оценку для
является случайной и представляет собой точечную несмещенную статистическую оценку для 
Исправленное среднее квадратичное отклонение для 

Для построения доверительного интервала для  используется случайная величина
используется случайная величина

что имеет нормированный нормальный закон распределения 
Воспользовавшись  получим
получим

Следует. доверительный интервал для будет таким:

где  находим из равенства
находим из равенства

по таблице значений функции Лапласа.
Пример. Случайно выбранных студентов из потока университета были подвергнуты тестированию по математике и химии. Результаты этих тестирования преподнесено статистическим распределением, где  — оценки по математике,
— оценки по математике,  — по химии. Ответы оценивались по десятибалльной системе:
— по химии. Ответы оценивались по десятибалльной системе:

Необходимо:
1) с надежностью  построить доверительный интервал для
построить доверительный интервал для  если
если 
2) с надежностью  построить доверительный интервал для
построить доверительный интервал для 
Решение. Вычислим основные числовые характеристики признак  и
и  а также
а также  Поскольку
Поскольку  получим:
получим:


1. Построим доверительный интервал с надежностью  для
для  если
если 

нам известные значения  Значения
Значения  вычисляем из уравнения
вычисляем из уравнения

где  находим по таблице значений функции Лапласа.
находим по таблице значений функции Лапласа.
Обозначим концы интервала:

Следует, доверительный интервал для  будет таким:
будет таким:

2. Построим доверительный интервал с надежностью  для
для 
Поскольку  нам не известно, то доверительный интервал в этом случае обозначается так:
нам не известно, то доверительный интервал в этом случае обозначается так:

На известное значение  находим по таблице распределения Стьюдента (дополнение 3),
находим по таблице распределения Стьюдента (дополнение 3),

Вычислим концы доверительного интервала:

Таким образом, доверительный интервал для  будет в таких границах:
будет в таких границах:

Доверительный интеграл с надежностью  для
для  будет таким:
будет таким:

Нам известно значение  Учитывая, что
Учитывая, что  найдем по таблице (дополнение 5) значения
найдем по таблице (дополнение 5) значения 
Обозначим концы доверительного интервала:

Следует, доверительный интервал для  подается таким неравенством:
подается таким неравенством:

Доверительный интервал для  с заданной надежностью
с заданной надежностью  будет таким:
будет таким:

Нам известны значения  обозначаем по таблице значений функции Лапласа
обозначаем по таблице значений функции Лапласа  где
где 
Обозначим концы доверительного интервала:

таким образом, доверительный интервал для  будет в таких границах:
будет в таких границах:

Построение доверительного интервала для с помощью неравенства Чебишова с заданной надежностью
 с помощью неравенства Чебишова с заданной надежностью
с помощью неравенства Чебишова с заданной надежностью В случае, если отсутствует информация про закон распределения признака генеральной совокупности  оценка вероятностей события
оценка вероятностей события  где
где  и построение доверительного интервала для
и построение доверительного интервала для  с заданной надежностью
с заданной надежностью  выполняется с использованием неравенства Чебишова по условию, что известно значение
выполняется с использованием неравенства Чебишова по условию, что известно значение  а именно:
а именно:

Из  обозначаем величину
обозначаем величину 

Доверительный интервал дается таким неравенством:

Когда  неизвестно, используем исправленную дисперсию
неизвестно, используем исправленную дисперсию  и доверительный интервал приобретает такой вид:
и доверительный интервал приобретает такой вид:

Пример. Полученные данные с 100 наугад выбранных предприятий относительно возрастания выработки на одного работника  которые имеют такой интервальное статистическое распределение:
которые имеют такой интервальное статистическое распределение:

Воспользовавшись неравенством Чебишова, построить доверительный интервал для  если известно значение
если известно значение  с надежностью
с надежностью 
Решение. Для построения доверительного интервала с помощью неравенства Чебишова необходимо вычислить  Чтобы обозначить
Чтобы обозначить  перейдем от интервального к дискретному статистическому распределению, а именно:
перейдем от интервального к дискретному статистическому распределению, а именно:

Тогда получим:

Воспользовавшись  вычислим
вычислим 

таким образом, доверительный интервал для  преподноситься такими неравенствами:
преподноситься такими неравенствами:

или

Пример. Заданы размеры основных фондов  на 30- ти предприятий дискретным статистическим распределением:
на 30- ти предприятий дискретным статистическим распределением:

Воспользовавшись неравенством Чебишова с надежностью  построить доверительный интервал для
построить доверительный интервал для 
Решение. Для постройки доверительного интервала для  с помощью неравенства Чебишова необходимо вычислить
с помощью неравенства Чебишова необходимо вычислить 

 млн руб.
млн руб.
Следует,  млн рублей.
млн рублей.

 млн рублей.
млн рублей.
Обозначить концы доверительного интервала:
 млн рублей
млн рублей
 н рублей
н рублей
Итак, доверительный интервал для  подается неравенствами
подается неравенствами

Лекции:
- Статистические гипотезы
- Корреляционный и регрессионный анализ
- Комбинаторика основные понятия и формулы с примерами
- Число перестановок
- Количество сочетаний
- Действия над событиями. Теоремы сложения и умножения вероятностей примеры с решением
- Примеры решения задач на тему: Случайные величины
- Примеры решения задач на тему: основные законы распределения
- Примеры решения задач на тему: совместный закон распределения двух случайных величин
- Статистические распределения выборок и их числовые характеристики
Отметим, что при соблюдении прочих предпосылок МНК автокорреляция остатков не влияет на свойства состоятельности и несмещенности оценок параметров уравнения регрессии обычным МНК, за исключением моделей авторегрессии. Применение МНК к моделям авторегрессии ведет к получению смещенных, несостоятельных и неэффективных оценок. [c.280]
Полученная модель есть модель двухфакторной линейной регрессии (точнее — авторегрессии). Определив ее параметры, мы найдем X и оценки параметров а п Ьо исходной модели. Далее с помощью соотношений (7.17) несложно определить параметры b, b2,… модели (7.16). Отметим, что применение обычного МНК к оценке параметров модели (7.22) приведет к получению смещенных оценок ее параметров ввиду наличия в этой модели в качестве фактора лаговой результативной переменной yt [c.307]
Однако, как было показано выше, оценка параметра с,, равная 0,440, является смещенной. Для получения несмещенных оценок параметров этого уравнения воспользуемся методом инструментальных переменных. Определим параметры уравнения регрессии (7.43) обычным МНК [c.327]
Если Ek> О, то кривая островершинная, при Ek <0 — плосковершинная (пологая). Метод моментов, как правило, приводит к состоятельным оценкам. Однако при малых выборках оценки могут оказаться значительно смещенными и малоэффективными. Метод моментов достаточно эффективен для оценки параметров нормально распределенных случайных величин. [c.48]
Бухгалтерские коэффициенты бета. Третий подход основывается на оценке параметров рыночного риска на основе бухгалтерских показателей прибыли, а не на рыночных ценах. Таким образом, изменения прибыли в филиале или фирме на квартальной или годовой основе могут быть отнесены к изменениям прибыли для рынка в те же периоды, которые используются для получения оценки бухгалтерского коэффициента бета, используемого в модели САРМ. Хотя данный подход обладает определенной привлекательностью, в нем таятся три потенциальных подводных камня. Во-первых, бухгалтерская прибыль, как правило, сглаживается по отношению к базовой ценности компании, поскольку бухгалтеры разносят расходы и доходы на множество периодов. Это приводит к коэффициентам бета, характеризуемым как смещенные в сторону занижения , особенно в отношении рискованных фирм, или смещенные в сторону завышения , если дело касается более безопасных фирм. Другими словами, коэффициенты бета, по всей вероятности, будут близки к 1 для всех фирм, использующих бухгалтерские данные. [c.267]
Покажем, что коэффициент gi является смещенной оценкой параметра pi. Действительно, gi вычисляется по формуле (4.14) [c.193]
Непосредственное использование МНК для оценки параметров каждого из уравнений регрессии, входящих в систему одновременных уравнений, в большинстве случаев приводит к неудовлетворительному результату. Чаще всего оценки получаются смещенными и несостоятельными, а статистические выводы по ним некорректными. Причины этого, а также возможные процедуры нахождения оценок параметров для систем одновременных уравнений анализируются в данной главе. [c.308]
Покажите, что смещение оценки параметра j во второй регрессии меньше, чем в первой. [c.137]
Дана выборка размера п из нормального распределения N(fj,, a2). Запишите логарифмическую функцию правдоподобия и найдите ML-оценки параметров ц и а2. Найдите смещения этих оценок. [c.260]
Часто индивидуальные факторы коррелированы с другими объясняющими переменными. Так, например, общий уровень культуры семьи и уровень ее дохода естественно считать связанными. В рамках моделей регрессии это означает, что индивидуальный фактор является существенной переменной в модели и ее исключение приводит к смещенным оценкам остальных параметров (см. п. 4.4). Иными словами, модели с панельными данными позволяют получать более точные оценки параметров. [c.359]
Следовательно, факт нулевого или ненулевого спроса на табак обусловлен ненаблюдаемым параметром е, описывающим потребительские предпочтения. Оценка зависимостей с подобными переключениями, которые обусловлены ненаблюдаемыми параметрами, обычно делается при помощи двухшаговых процедур, поскольку можно показать, что МНК — оценка в данном случае приведет к смещенным оценкам параметров функции спроса. Одной из наиболее известных подобных процедур является процедура [c.158]
Оценки, определяемые вектором (4.8), обладают в соответствии с теоремой Гаусса—Маркова минимальными дисперсиями в классе всех линейных несмещенных оценок, но при наличии мультиколлинеарности эти дисперсии могут оказаться слишком большими, и обращение к соответствующим смещенным оценкам может повысить точность оценивания параметров регрессии. На рис. 5.1 показан случай, когда смещенная оценка Ру, [c.110]
При подходе, использующем рыночную модель, в первую очередь необходимо оценить ожидаемую доходность на рыночный индекс. Затем для каждой ценной бумаги нужно оценить коэффициент вертикального смещения и коэффициент бета . В общей сложности надо произвести оценку (1 + 2ЛО параметров (1 для г,, 2Л/для коэффициента вертикального смещения и бета -коэффициентов для каждой из N рискованных ценных бумаг). Полученные значения могут быть использованы для проведения оценок ожидаемой доходности каждой ценной бумаги с помощью уравнения (8.3), которое в данном случае имеет следующий вид [c.226]
Вследствие этого оценка параметров для линеаризуемых функций МНК оказываются несколько смещенной. [c.75]
Основное различие моделей (7.37) и (7.44) состоит в том, что модель (7.37) включает ожидаемые значения факторной переменной, которые нельзя получить эмпирическим путем. Поэтому статистические методы для оценки параметров модели (7.37) неприемлемы. Модель (7.44) включает только фактические значения переменных, поэтому ее параметры можно определять на основе имеющейся статистической информации с помощью стандартных статистических методов. Однако, как и в случае с моделью Кдфка, применение ОМНК для оценки параметров уравнения (7.44) привело бы к получению их смещенных оценок ввиду наличия в правой части модели лагового значения результативного признака у, (. [c.321]
Вторая проблема состоит в том, что поскольку в модели авторегрессии в явном виде постулируется зависимость между текущими значениями результата. у, и текущими значениями остатков н очевидно, что между временными рядами у, и , , также существует взаимозависимость. Тем самым нарушается еще одна предпосылка МНК, а именно предпосылка об отсутствии связи между факторным признаком и остатками в уравнении регрессии. Поэтому применение обычного МНК для оценки параметров уравнения авторегрессии приводит к получению смещенной оценки параметра при переменной yt x. [c.325]
Уравнение (7.46) представляет собой модель с распределенным лагом, для которой не нарушаются предпосылки обычного МНК, приводящие к несостоятельности и смещенности оценок параметров. Определив параметры моделей (7.51) и (7.56), можно рассчитать параметры исходной модели (7.2) а, 40 и с,. Модель [c.326]
Следовательно, оценка bi является смещенной (скорее всего, завышенной при условии, что 0 < pi < 1) оценкой параметра pi. Причем эту смещенность нельзя преодолеть даже при бесконечном увеличении выборки. [c.314]
При анализе временных рядов часто приходится учитывать статистическую зависимость наблюдений в разные моменты времени. Иными словами, для многих временных рядов предположение о некоррелированности ошибок не выполняется. В этом разделе мы рассмотрим наиболее простую модель, в которой ошибки образуют так называемый авторегрессионный процесс первого порядка (точное определение будет дано ниже). Как было показано ранее (глава 5), применение обычного метода наименьших квадратов к этой системе дает несмещенные и состоятельные оценки параметров, однако можно показать (см., например, Johnston and DiNar-do, 1997), что получаемая при этом оценка дисперсии оказывается смещенной вниз, что может отрицательно сказаться при проверке гипотез о значимости коэффициентов. Образно говоря, МНК рисует более оптимистичную картину регрессии, чем есть на самом деле. [c.184]
В п. 4.4 мы рассмотрели проблемы исключения существенных и включения несущественных переменных для линейных регрессионных моделей. Можно поставить аналогичный вопрос какое влияние оказывает пропуск существенных переменных в уравнении (12.4) на оценивание модели бинарного выбора (12.3) Исчерпывающий ответ на него выходит за рамки нашей книги. Отметим лишь, что в данном случае, даже если исключенные существенные переменные ортогональны включенным, оценки параметров будут, в отличие от линейной схемы, смещенными и несостоятельными (подробнее см. (Greene, 1997) и (Johnston and DiNardo, 1997)). [c.329]
Из равенства (12.41) следует, что применение обычного метода наименьших квадратов к наблюдениям yt приведет, в общем случае, к смещенным оценкам параметров /3. Если же а и = 0, т. е. когда механизм выбора и степень участия независимы, смещение отсутствует. Величину (p(z t i]I (z tl B (12.41) обозначают A(zj7) и называют лямбда Хекмана (He kman lambda). [c.344]
Таким образом, нашей задачей является нахождение безусловных моментов pretest-оценки, принимая во внимание то, что процедуры выбора модели и оценки параметров интегрированы в одну процедуру. Мы не утверждаем, что следует избегать предварительного тестирования, хотя хорошо известно, что preiesf-оценки обладают плохими статистическими свойствами, одно из которых — равномерная неэффективность2. На практике избежать предварительного тестирования почти невозможно. Наша точка зрения состоит в том, что следует вычислять корректно смещение и дисперсию (или среднеквадратичное отклонение) оценки, полностью принимая во внимание то, что оценивание и отбор модели интегрированы в одну процедуру. [c.399]
Относительно просто решается такая задача для функций, преобразуемых к линейному виду. Например, степенную функцию можно прологарифмировать, получив линейную зависимость У от X в логарифмах, и применить для оценки параметров уже упоминавшийся метод наименьших квадратов. Однако надо иметь в виду, что при этом оценивается не сама нелинейная функция, но ее линейное преобразование, а это может вызвать смещение оценок параметров. [c.136]
Если матрица ковариации ошибок по наблюдениям отлична от О IN (нарушена 3-я гипотеза основной модели), то МНК-оценки параметров регрессии остаются несмещенными, но перестают быть эффективными в классе линейных. Смещенными оказываются МНК-оценки их ковариции, в частности оценки их стандартных ошибок (как правило, они преуменьшаются). [c.27]
Рассмотрим оценку Ъг параметра 32, полученную простой регрес сией у на xz на основе таблицы, построенной в результате классифи кации данных по переменной Xz, и оценку Ь3 параметра р3, получен ную в результате простой регрессии у на ха на основе таблицы, соот ветствующей классификации по Xs. Обе оценки окажутся смещенными поскольку в каждом случае допущена ошибка спецификации из-з исключения из регрессии существенной переменной. Поэтому [c.234]
Он приблизительно совпадет с оценкой параметра J3, полученной методом наименьших квадратов, если уравнение Yt = РУ< 1 + vt будет подгоняться с учетом свободного члена. Снова ограничиваясь порядком п-1, получим, что смещение для этой оценки равно2 [c.305]
Таким образом, входящие в уравнение возмущающее воздействие Y объясняющая переменная оказываются коррелированными, а значит, как и в случае ошибок в переменных (см. гл. 9), непосредственное применение к (12.1) метода наименьших квадратов приведет к смещенныь оценкам параметров ос и р. Это смещение возникает в случае конечные выборок, однако оценки, найденные обычным методом наименьшие квадратов, будут к тому же и несостоятельными, т. е. смещение сохранится и для бесконечно «больших выборок. [c.343]
В более общем случае, когда модель состоит из одновременных уравнений, не удовлетворяющих специальным предположениям о рекур-сивности, существует простой метод оценивания — косвенный метод наименьших квадратов, но он применим лишь к точно идентифицируемым уравнениям. Состоит этот метод в использовании обыкновенного метода наименьших квадратов для оценивания параметров каждого из уравнений структурной формы в отдельности и в последующем выводе оценок структурных параметров с помощью преобразования ВП = —Г, где вместо матрицы П берется матрица оценок параметров приведенной формы П. Элементы матрицы П будут наилучшими линейными несмещенными оценками, однако это свойство не сохраняется при преобразованиях, и полученные оценки структурных параметров, по-видимому, окажутся смещенными. Тем не менее и оценки П, и оценки косвенного метода наименьших квадратов будут состоятельными. Для [c.375]
Другой метод устранения или уменьшения мультиколлинеар-ности заключается в переходе от несмещенных оценок, определенных по методу наименьших квадратов, к смещенным оценкам, обладающим, однако, меньшим рассеянием относительно оцениваемого параметра, т. е. меньшим математическим ожиданием квадрата отклонения оценки fy от параметра ру или М (bj— p/)2. [c.110]