
Одним из основных статистических показателей последовательности чисел является коэффициент вариации. Для его нахождения производятся довольно сложные расчеты. Инструменты Microsoft Excel позволяют значительно облегчить их для пользователя.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.
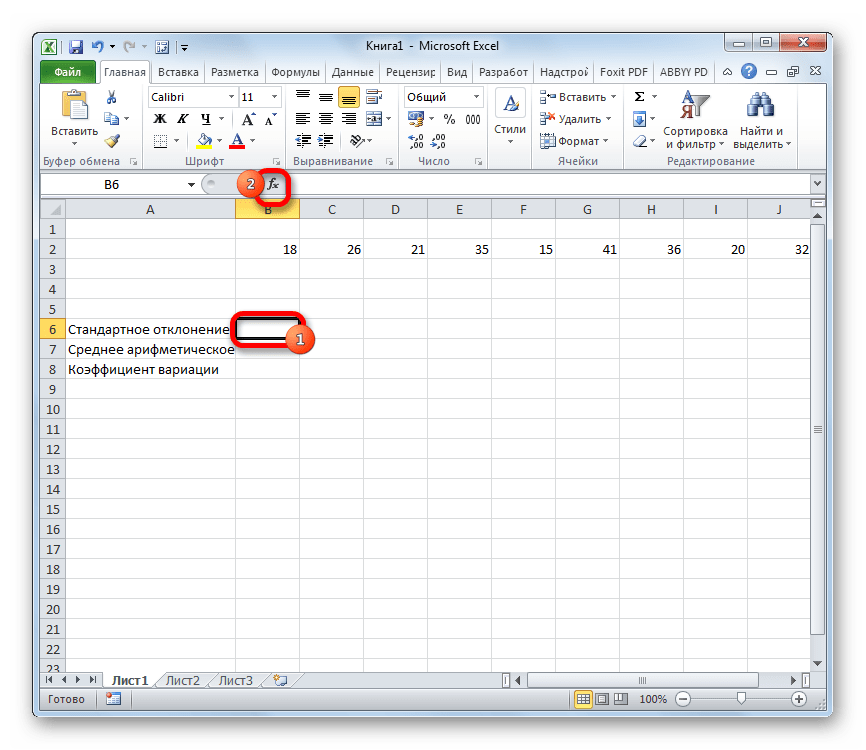
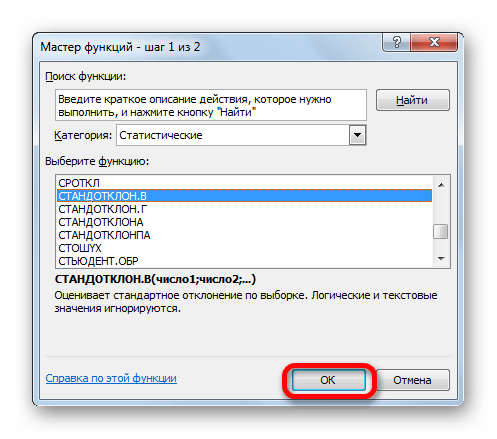
Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».
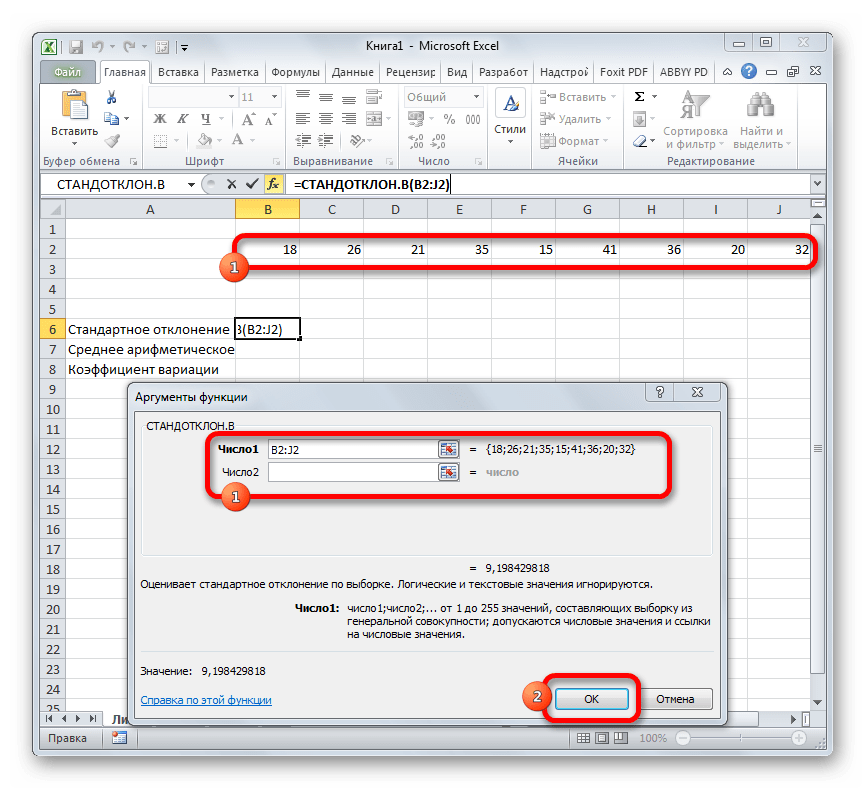
Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»
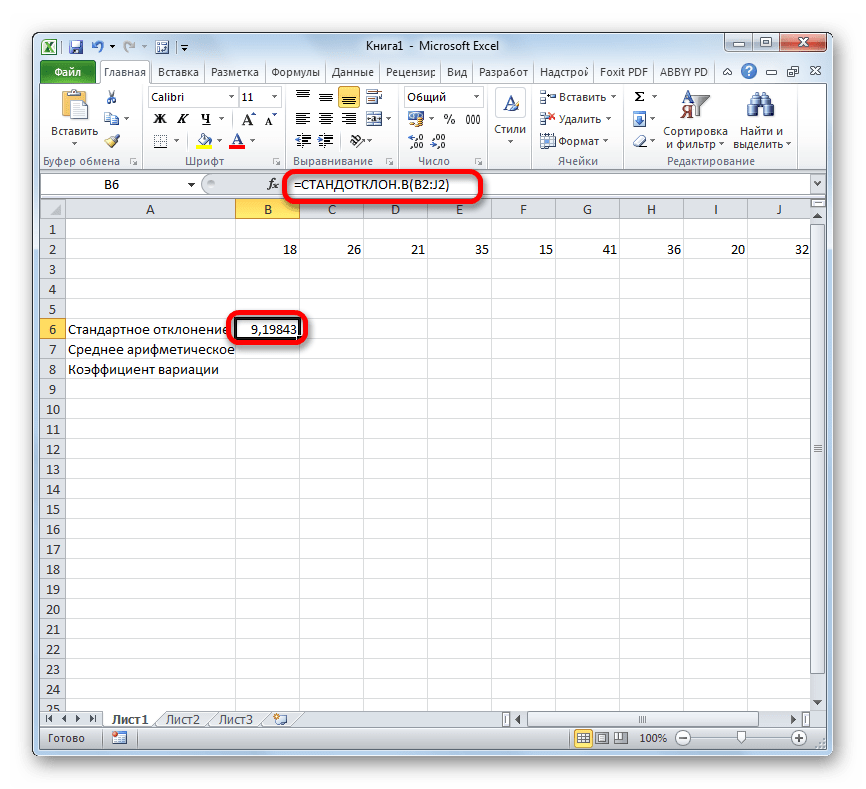
Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».
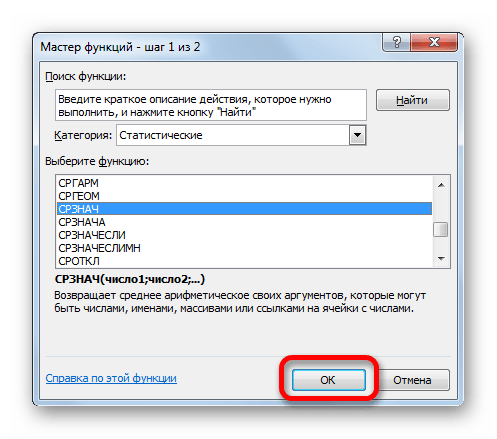
Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».
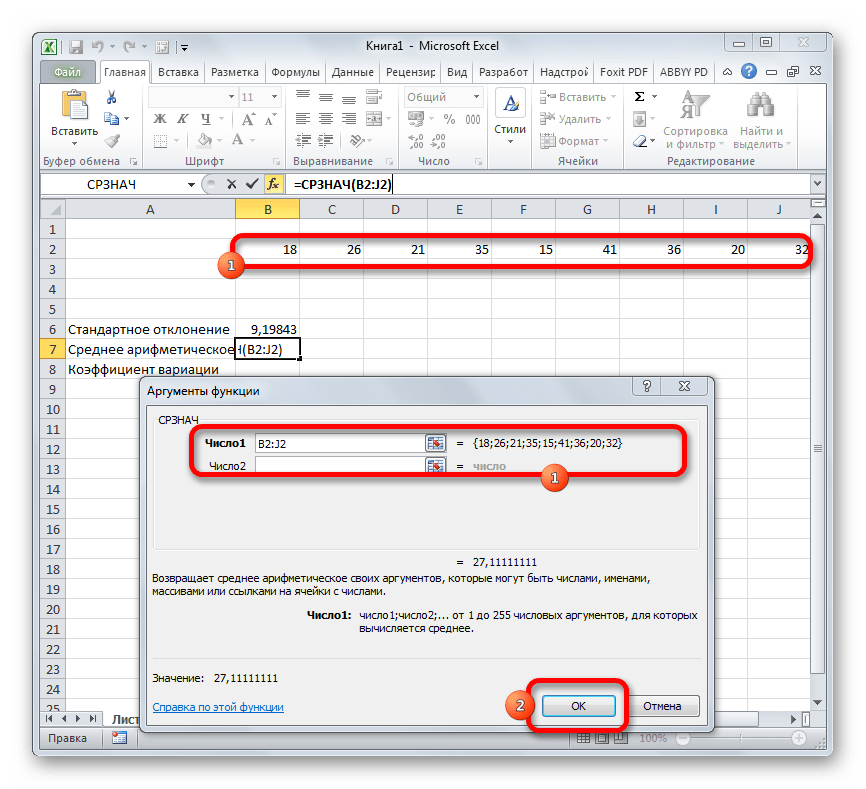
Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.
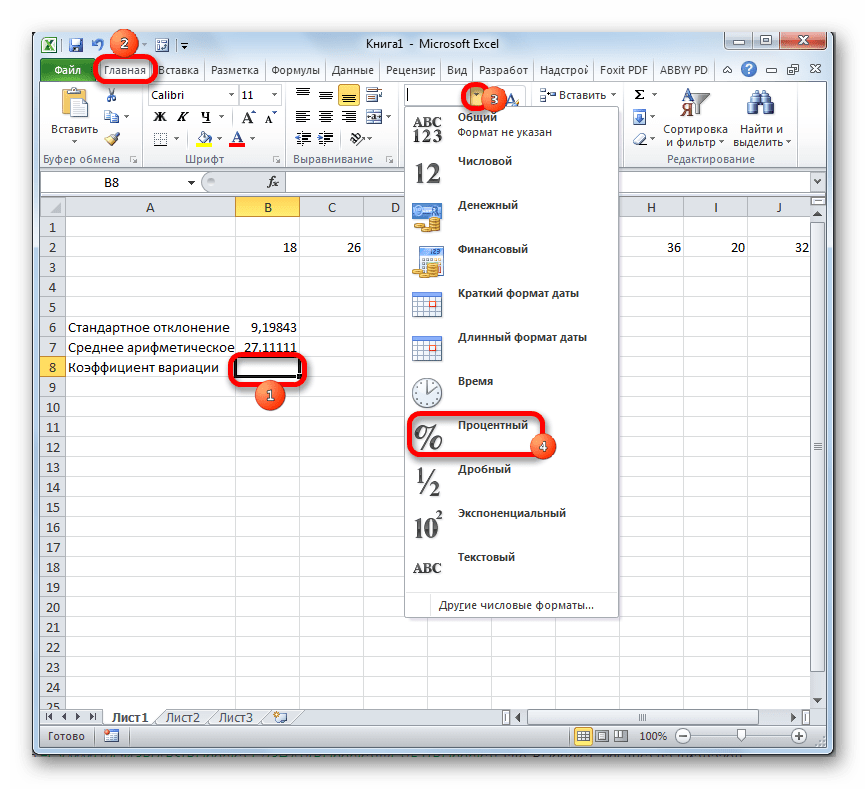
Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.
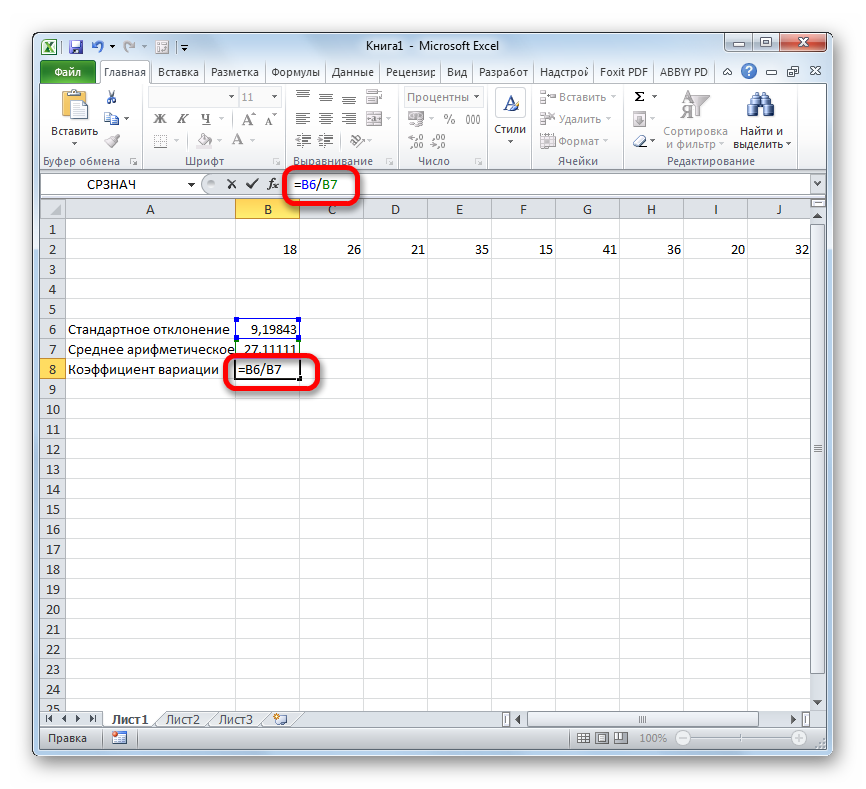
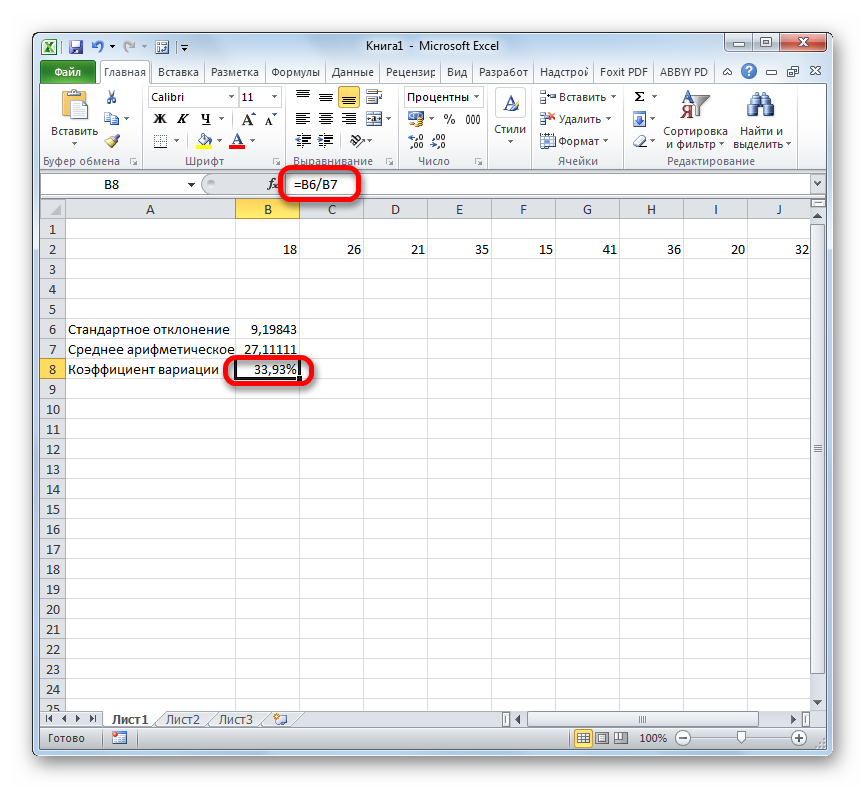
Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.
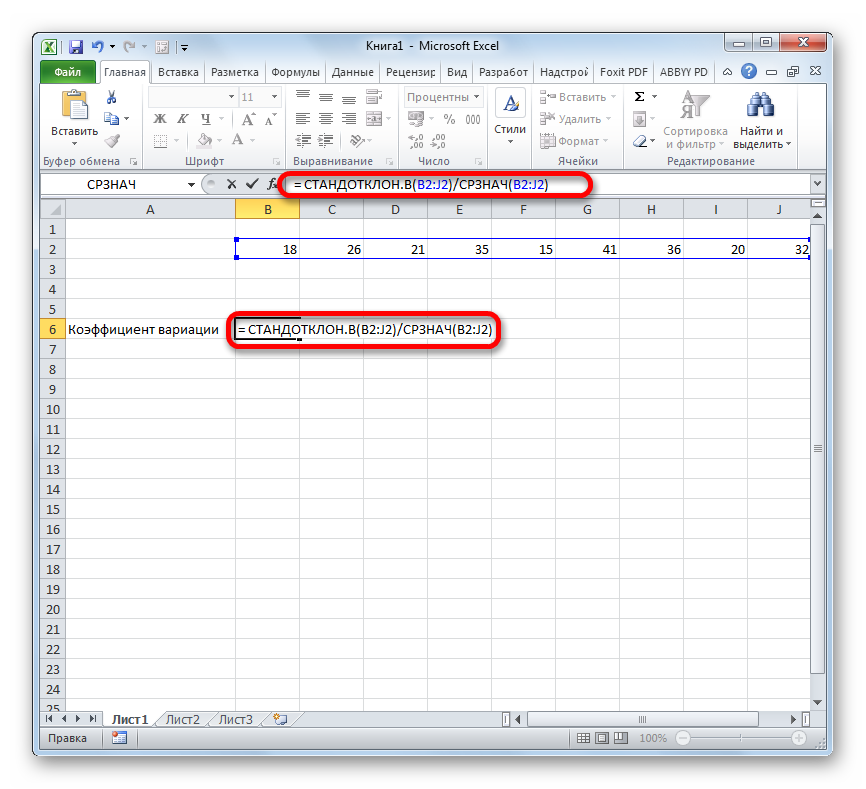
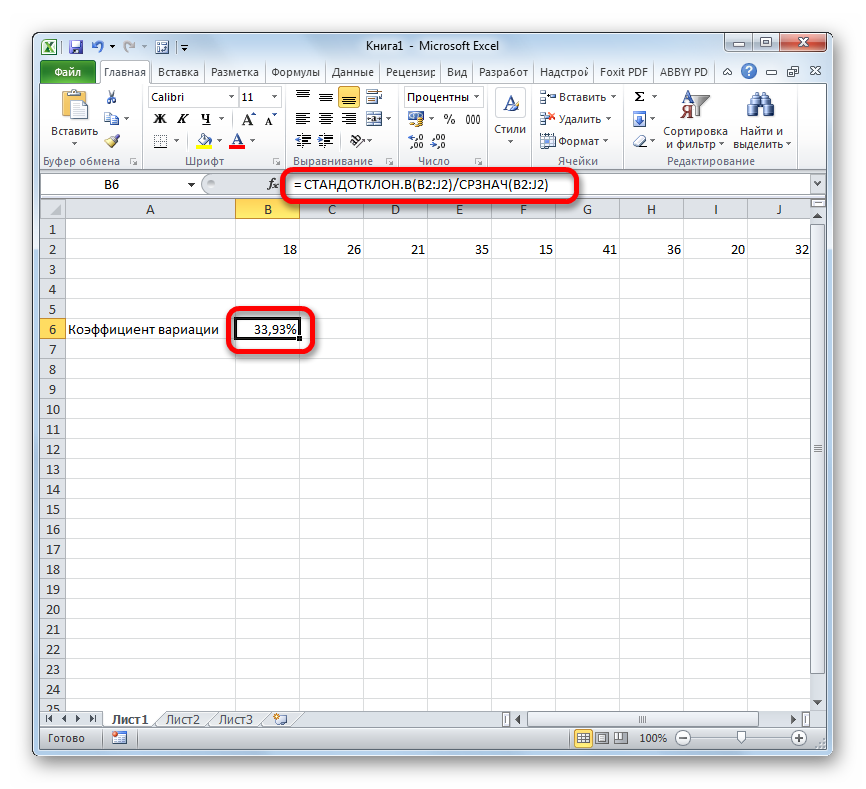
Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
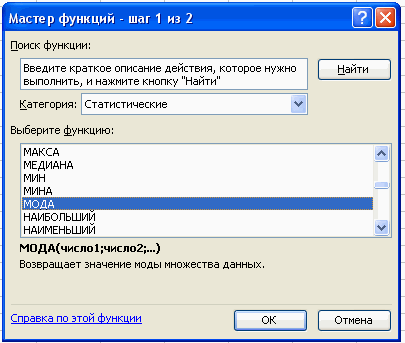
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
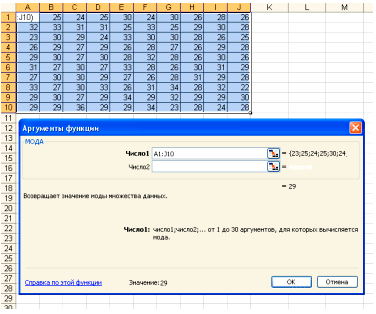
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
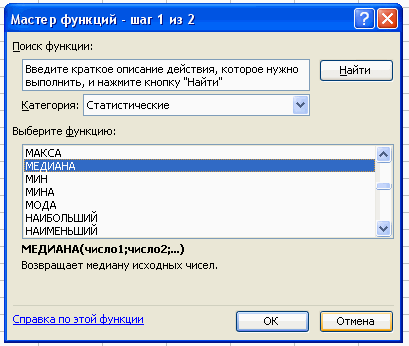
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
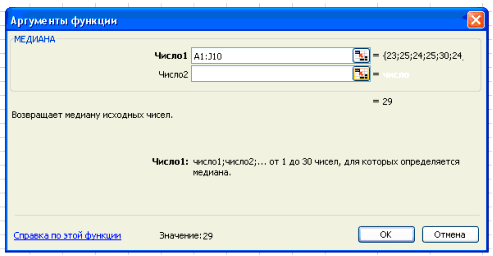
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
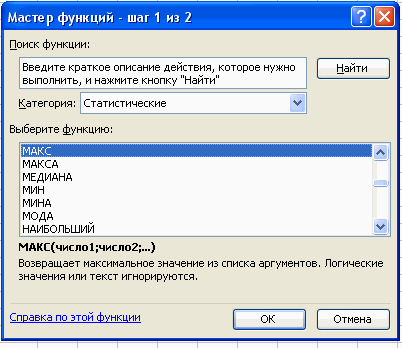
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
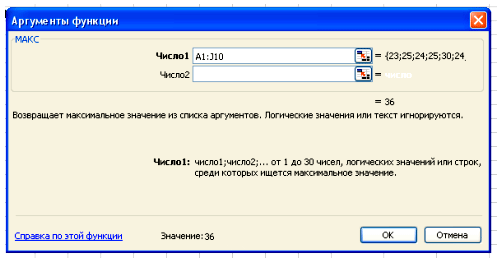
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
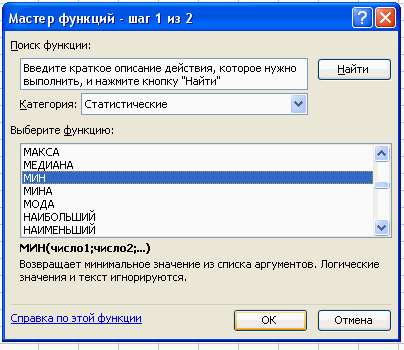
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
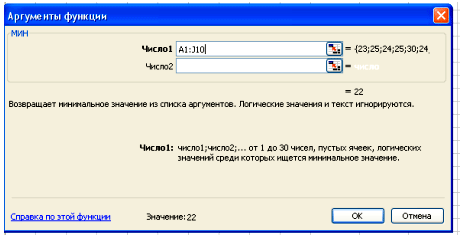
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
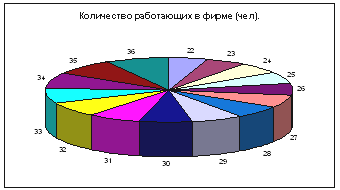
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Основная идея
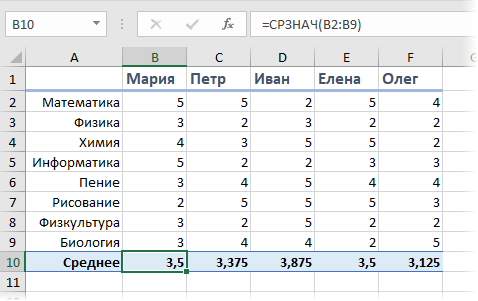
Предположим, что мы с вами сидим в приемно-экзаменационной комиссии и оцениваем абитуриентов, которые хотят поступить в наш ВУЗ. Оценки по различным предметам у наших кандидатов следующие:
Свободное место, допустим, только одно, и наша задача — выбрать достойного.
Первое, что обычно приходит в голову — это рассчитать классический средний балл с помощью стандартной функции Excel СРЗНАЧ (AVERAGE).
На первый взгляд кажется, что лучше всех подходит Иван, т.к. у него средний бал максимальный. Но тут мы вовремя вспоминаем, что факультет-то наш называется «Программирование», а у Ивана хорошие оценки только по рисованию, пению и прочей физкультуре, а по математике и информатике как раз не очень. Возникает вопрос: а как присвоить нашим предметам различную важность (ценность), чтобы учитывать ее при расчете среднего? И вот тут на помощь приходит средневзвешенное значение.
Средневзвешенное — это среднее с учетом различной ценности (веса, важности) каждого из элементов.
В бизнесе средневзвешенное часто используется в таких задачах, как:
- оценка портфеля акций, когда у каждой из них своя ценность/рисковость
- оценка прогресса по проекту, когда у задач не равный вес и важность
- оценка персонала по набору навыков (компетенций) с разной значимостью для требуемой должности
- и т.д.
Расчет средневзвешенного формулами
Добавим к нашей таблице еще один столбец, где укажем некие безразмерные баллы важности каждого предмета по шкале, например, от 0 до 9 при поступлении на наш факультет программирования. Затем расчитаем средневзвешенный бал для каждого абитурента, т.е. среднее с учетом веса каждого предмета. Нужная нам формула будет выглядеть так:
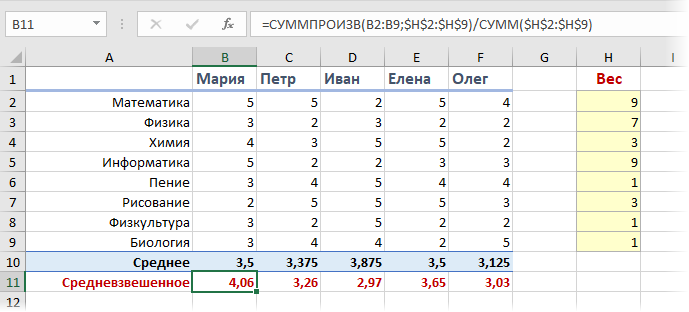
Функция СУММПРОИЗВ (SUMPRODUCT) попарно перемножает друг на друга ячейки в двух указанных диапазонах — оценки абитурента и вес каждого предмета — а затем суммирует все полученные произведения. Потом полученная сумма делится на сумму всех баллов важности, чтобы усреднить результат. Вот и вся премудрость.
Так что берем Машу, а Иван пусть поступает в институт физкультуры 😉
Расчет средневзвешенного в сводной таблице
Поднимем ставки и усложним задачу. Допустим, что теперь нам нужно подсчитать средневзвешенное, но не в обычной, а в сводной таблице. Предположим, что у нас есть вот такая таблица с данными по продажам:
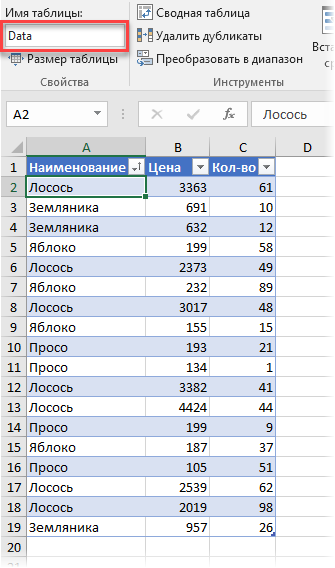
Обратите внимание, что я преобразовал ее в «умную» таблицу с помощью команды Главная — Форматировать как таблицу (Home — Format as Table) и дал ей на вкладке Конструктор (Design) имя Data.
Заметьте, что цена на один и тот же товар может различаться. Наша задача: рассчитать средневзвешенные цены для каждого товара. Следуя той же логике, что и в предыдущем пункте, например, для земляники, которая продавалась 3 раза, это должно быть:
=(691*10 + 632*12 + 957*26)/(10+12+26) = 820,33
То есть мы суммируем стоимости всех сделок (цена каждой сделки умножается на количество по сделке) и потом делим получившееся число на общее количество этого товара.
Правда, с реализацией этой нехитрой логики именно в сводной таблице нас ждет небольшой облом. Если вы работали со сводными раньше, то, наверное, помните, что можно легко переключить поле значений сводной в нужную нам функцию, щелкнув по нему правой кнопкой мыши и выбрав команду Итоги по (Summarize Values By) :
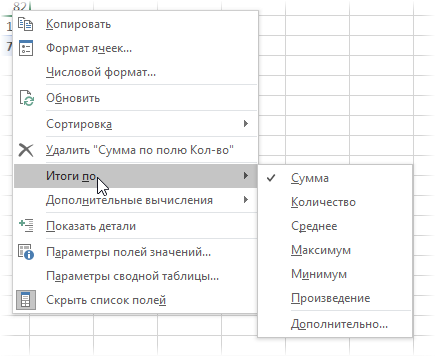
В этом списке есть среднее, но нет средневзвешенного 🙁
Можно частично решить проблему, если добавить в исходную таблицу вспомогательный столбец, где будет считаться стоимость каждой сделки:
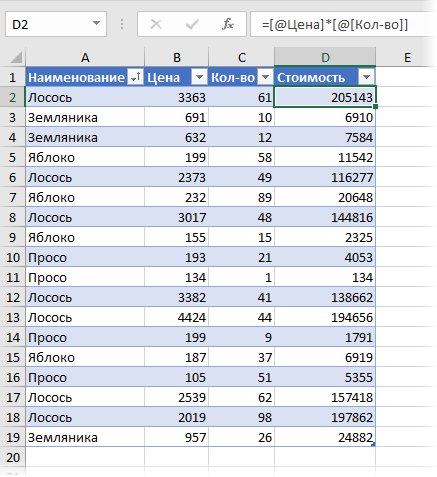
Теперь можно рядом закинуть в область значений стоимость и количество — и мы получим почти то, что требуется:
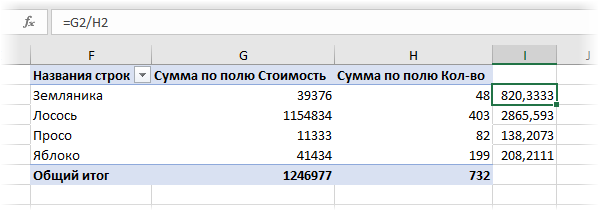
Останется поделить одно на другое, но сделать это, вроде бы, простое математическое действие внутри сводной не так просто. Придется либо добавлять в сводную вычисляемое поле (вкладка Анализ — Поля, элементы, наборы — Вычисляемое поле), либо считать обычной формулой в соседних ячейках или привлекать функцию ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ (GET.PIVOT.DATA) , о которой я уже писал. А если завтра изменятся размеры сводной (ассортимент товаров), то все эти формулы придется вручную корректировать.
В общем, как-то все неудобно, трудоемко и нагоняет тоску. Да еще и дополнительный столбец в исходных данных нужно руками делать. Но красивое решение есть.
Расчет средневзвешенного в сводной таблице с помощью Power Pivot и языка DAX
Если у вас Excel 2013-2016, то в него встроен супермощный инструмент для анализа данных — надстройка Power Pivot, по сравнению с которой сводные таблицы с их возможностями — как счеты против калькулятора. Если у вас Excel 2010, то эту надстройку можно совершенно бесплатно скачать с сайта Microsoft и тоже себе установить. С помощью Power Pivot расчет средневзвешенного (и других невозможных в обычных сводных штук) очень сильно упрощается.
1. Для начала, загрузим нашу таблицу в Power Pivot. Это можно сделать на вкладке Power Pivot кнопкой Добавить в модель данных (Add to Data Model) . Откроется окно Power Pivot и в нем появится наша таблица.
2. Затем щелкните мышью в строку формул и введите туда формулу для расчета средневзвешенного:
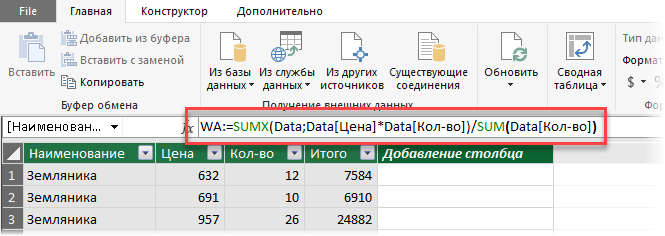
Несколько нюансов по формуле:
- В Power Pivot есть свой встроенный язык с набором функций, инструментов и определенным синтаксисом, который называется DAX. Так что можно сказать, что эта формула — на языке DAX.
- Здесь WA — это название вычисляемого поля (в Power Pivot они еще называются меры), которое вы придумываете сами (я называл WA, имея ввиду Weighted Average — «средневзвешенное» по-английски).
- Обратите внимание, что после WA идет не равно, как в обычном Excel, а двоеточие и равно.
- При вводе формулы будут выпадать подсказки — используйте их.
- После завершения ввода формулы нужно нажать Enter , как и в обычном Excel.
3. Теперь строим сводную. Для этого в окне Power Pivot выберите на вкладке Главная — Сводная таблица (Home — Pivot Table). Вы автоматически вернетесь в окно Excel и увидите привычный интерфейс построения сводной таблицы и список полей на панели справа. Осталось закинуть поле Наименование в область строк, а нашу созданную формулой меру WA в область значений — и задача решена:
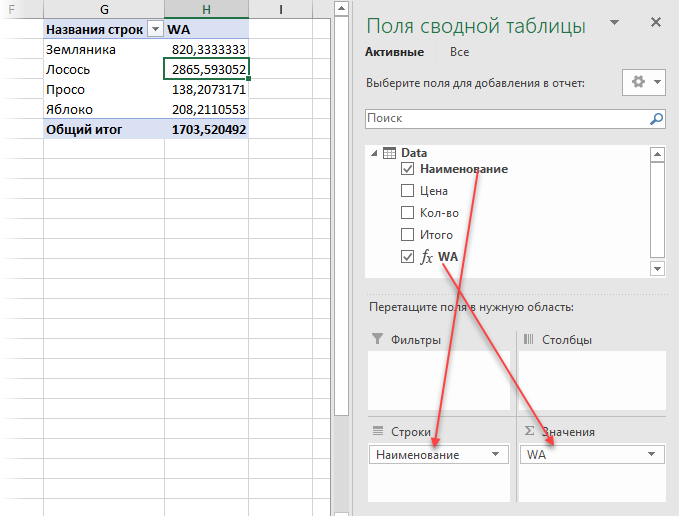
Вот так — красиво и изящно.
Общая мораль: если вы много и часто работаете со сводными таблицами и вам их возможности «тесноваты» — копайте в сторону Power Pivot и DAX — и будет вам счастье!
Размах варьирования. Наибольшее и наименьшее значения
Лабораторная работа № 1
Статистический анализ данных
Цель работы: научиться обрабатывать статистические данные с помощью встроенных функций.
Порядок выполнения работы:
1. Основные статистические характеристики:
— Выборочная дисперсия (вариабельность)
2. Самостоятельная работа
— Диаграмма рассеяния (задание 1)
— Основные статистические показатели (задание 2)
— Отклонение случайного распределения от нормального (задание 3)
1. Основные статистические характеристики.
Электронные таблицы Excel имеют огромный набор средств для анализа статистических данных. Наиболее часто используемые статистические функции встроены в основное ядро программы, то есть эти функции доступны с момента запуска программы.
Среднее значение.
Функция СРЗНАЧ (или AVERAGE) вычисляет выборочное (или генеральное) среднее, то есть среднее арифметическое значение признака выборочной (или генеральной) совокупности. Аргументом функции СРЗНАЧ является набор чисел, как правило, задаваемый в виде интервала ячеек, например, =СРЗНАЧ (А3:А201).
Дисперсия и среднее квадратическое отклонение.
Для оценки разброса данных используются такие статистические характеристики, как дисперсия D и среднее квадратическое (или стандартное) отклонение . Стандартное отклонение есть квадратный корень из дисперсии: . Большое стандартное отклонение указывает на то, что значения измерения сильно разбросаны относительно среднего, а малое – на то, что значения сосредоточены около среднего.
В Excel имеются функции, отдельно вычисляющие выборочную дисперсию Dви стандартное отклонение в и генеральные дисперсию Dг и стандартное отклонение г. Поэтому, прежде чем вычислять дисперсию и стандартное отклонение, следует четко определиться, являются ли ваши данные генеральной совокупностью или выборочной. В зависимости от этого нужно использовать для расчета Dг и г , Dв и в.
Для вычисления выборочной дисперсии Dв и выборочного стандартного отклонения в имеются функции ДИСП (или VAR) и СТАНДОТКЛОН (или STDEV). Аргументом этих функций является набор чисел, как правило, заданный диапазоном ячеек, например, =ДИСП (В1:В48).
Для вычисления генеральной дисперсии Dг и генерального стандартного отклонения г имеются функции ДИСПР (или VARP) и СТАНДОТКЛОНП (или STDEVP), соответственно.
Аргументы этих функций такие же как и для выборочной дисперсии.
Объем совокупности.
Объем совокупности выборочной или генеральной – это число элементов совокупности. Функция СЧЕТ (или COUNT) определяет количество ячеек в заданном диапазоне, которые содержат числовые данные. Пустые ячейки или ячейки, содержащие текст, функция СЧЕТ пропускает. Аргументом функции СЧЕТ является интервал ячеек, например: =СЧЕТ (С2:С16).
Для определения количества непустых ячеек, независимо от их содержимого, используется функция СЧЕТ3. Ее аргументом является интервал ячеек.
Мода и медиана.
Мода – это значение признака, которое чаще других встречается в совокупности данных. Она вычисляется функцией МОДА (или MODE). Ее аргументом является интервал ячеек с данными.
Медиана – это значение признака, которое разделяет совокупность на две равные по числу элементов части. Она вычисляется функцией МЕДИАНА (или MEDIAN). Ее аргументом является интервал ячеек.
Размах варьирования. Наибольшее и наименьшее значения.
Размах варьирования R – это разность между наибольшим xmax и наименьшим xmin значениями признака совокупности (генеральной или выборочной): R=xmax–xmin. Для нахождения наибольшего значения xmax имеется функция МАКС (или MAX), а для наименьшего xmin – функция МИН (или MIN). Их аргументом является интервал ячеек. Для того, чтобы вычислить размах варьирования данных в интервале ячеек, например, от А1 до А100, следует ввести формулу: =МАКС (А1:А100)-МИН (А1:А100).
Задание 1
Имеются данные о размерах располагаемого дохода DPI и расходов на личное потребление С для n семей в условных единицах, так что DPIi и Сi, соответственно, представляют располагаемый доход и расходы на личное потребление i-й семьи.
1. Построить диаграмму рассеяния, принимая за ось абсцисс — DPIi,а за ось ординатСi
| Доходы_расходы | |||||
| I | DPI | C | I | DPI | C |
2. Выполнить настройку формата оси Х и оси Y в соответствии с образцом диаграммы.
Задание 2
Имеются данные об уровне безработицы (в %) среди «белого» (коренное) и «цветного» (эмигранты) населения страны с марта 2000г. по июль 2001г. (месячные данные), так что BELi и ZVETi, соответственно, представляют уровни безработицы в i-м месяце.
1. Построить графики изменения уровней безработицы в обеих группах в течение указанного периода времени.
2. Вычислить средние значения уровней безработицы для BELi и ZVETi населения страны.
| Уровень безработицы | ||
| Исходные данные | ||
| I | BEL(%) | ZVET(%) |
| 3,2 | 6,9 | |
| 3,1 | 6,7 | |
| 3,2 | 6,5 | |
| 3,3 | 7,1 | |
| 3,3 | 6,8 | |
| 3,2 | 6,4 | |
| 3,2 | 6,6 | |
| 3,1 | 7,3 | |
| 3,0 | 6,5 | |
| 3,0 | 6,5 | |
| 3,0 | 6,0 | |
| 2,9 | 5,7 | |
| 3,1 | 6,0 | |
| 3,1 | 6,9 | |
| 3,1 | 6,5 | |
| 3,0 | 7,0 | |
| 3,2 | 6,4 |
3. Вычислить выборочные дисперсии, характеризующие степень разброса значений BELi и ZVETi вокруг своего среднего значения.
4. Вычислить стандартные отклоненияBELi и ZVETi относительно среднего значения.
5. Вычислить наибольшее и наименьшее значения для BELi и ZVETi.
6. Вычислить размах варьирования дляBELi и ZVETi.
7. Вычислить Моду и Медиану дляBELi и ZVETi.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
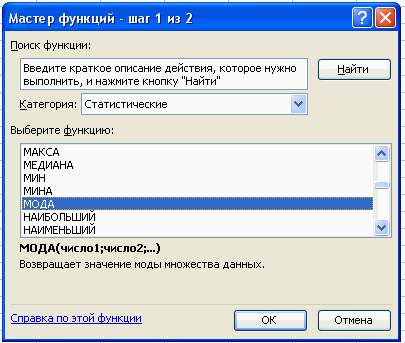
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
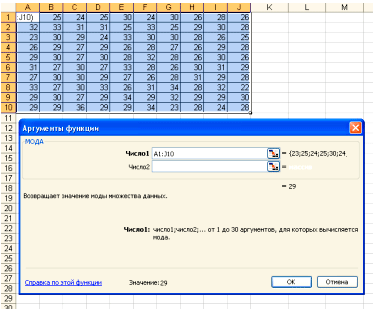
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
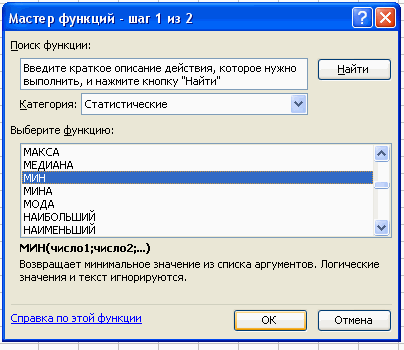
Вставка – Функция – Статистические – МИН.
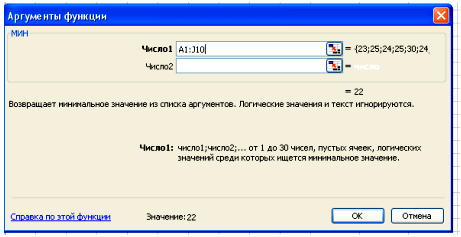
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
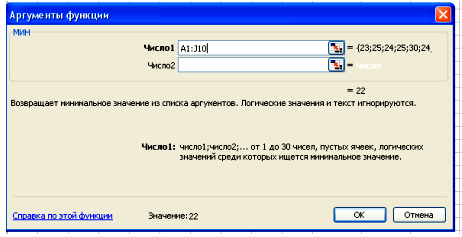
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
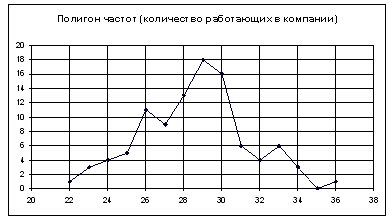
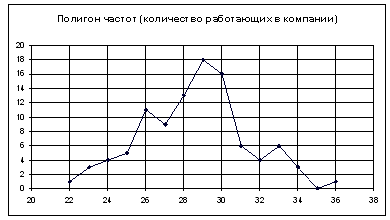
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xiслучайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
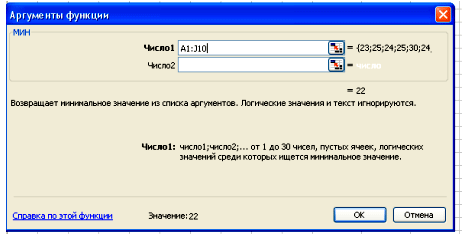
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
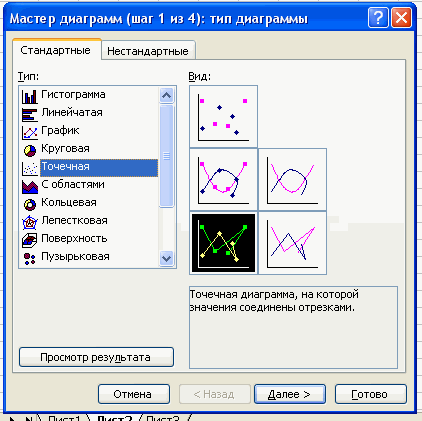
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
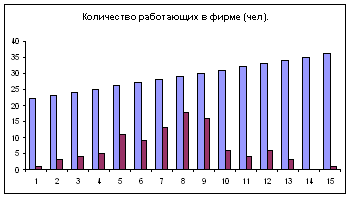
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Цель:
- Совершенствование умений и навыков нахождения статистических
характеристик случайной величины, работа с расчетами в Excel; - применение информационно коммутативных технологий для анализа данных;
работа с различными информационными носителями.
Ход урока
- Сегодня на уроке мы научимся рассчитывать статистические характеристики
для больших по объему выборок, используя возможности современных
компьютерных технологий. - Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют
переменную величину, которая в зависимости от исхода испытания принимает одно
значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных
случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода,
медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических
характеристик случайной величины (полигон частот, круговые и столбчатые
диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических
задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества
работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
Ход работы.
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в
появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в
штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
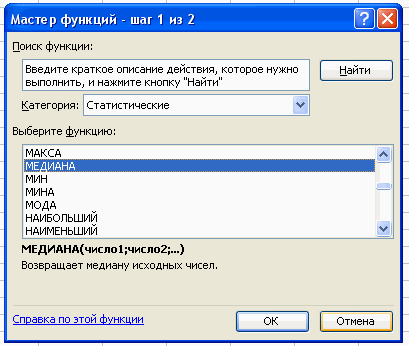
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
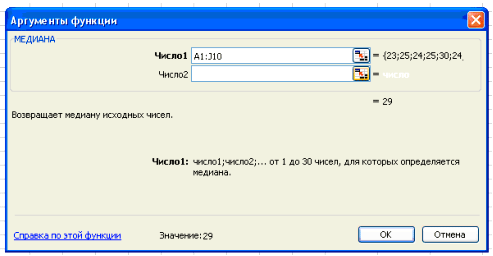
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение
сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением
случайной величины. Для вычисления размаха ряда нужно найти наибольшее и
наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
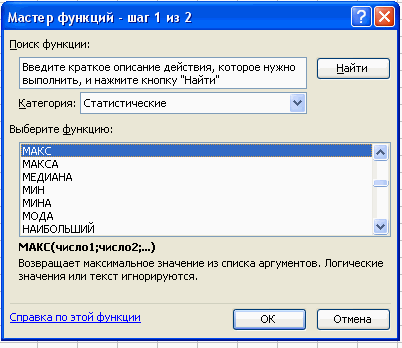
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
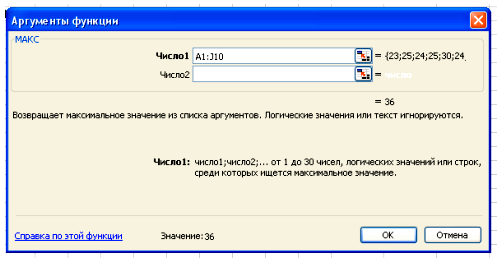
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и
фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон
распределения, т.е. составить таблицу значений случайной величины и
соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в
фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi
случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий
ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке
встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция –
Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма –
Стандартные – Точечная (точечная диаграмма на которой значения соединены
отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы
(Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы
для наибольшей наглядности.
Получаем:
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая
нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для
анализа и обработки статистической информации.
Процедура «Описательные статистики » пакета «Анализ данных.

В процедуре автоматически вычисляются следующие числовые характеристики выборки:
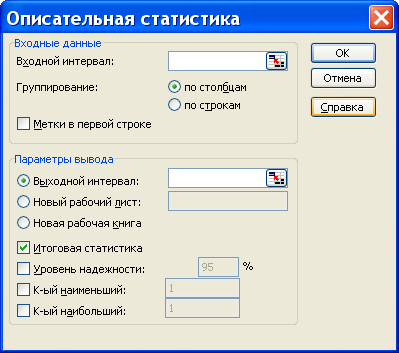
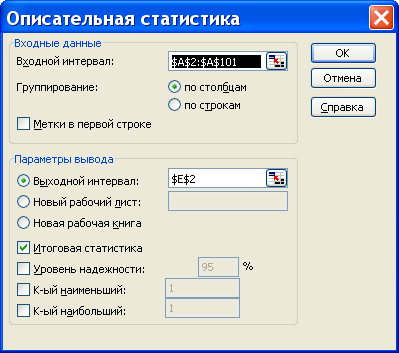
Для того чтобы выполнить вычисления, вводим в поле «Водной интервал» адреса ячеек, в которых записаны выборочные значения;
помечаем «Выходной интервал» и вводим в поле адрес первой ячейки, начиная с которой в листе Excel будет отображён резгультат; помечаем «Итоговая статистика»:
Результаты вычислений процедуры представлены в виде таблицы:
|
Столбец1 |
|
|
Среднее |
120.10 |
|
Стандартная ошибка |
0.22 |
|
Медиана |
120.12 |
|
Мода |
118.69 |
|
Стандартное отклонение |
2.15 |
|
Дисперсия выборки |
4.63 |
|
Эксцесс |
0.21 |
|
Асимметричность |
-0.16 |
|
Интервал |
11.21 |
|
Минимум |
114.46 |
|
Максимум |
125.67 |
|
Сумма |
12010.34 |
|
Счет |
100 |
Здесь: «Асимметричность» – коэффициент асимметрии, «Интервал» – размах варьирования, «Счёт» – объём выборки.
Функция «Квартиль» для вычисления квартилей и межквартильного размаха
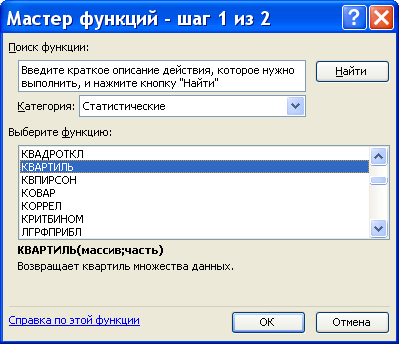
КВАРТИЛЬ(массив;часть)
Функция вычисляет (в зависимости от значения параметра «Часть»), выборочные значения верхней квартили («Часть» = 3) или нижней квартили («Часть» = 13), медиану («Часть» = 2) , наибольшее («Часть» = 4) или наименьшее («Часть» = 03) значения для выборки, определённой как «массив»..