Почему наши умозаключения так часто оказываются ошибочными? Что такое корреляция и причинность? Как рассуждать и делать выводы, опираясь на научный метод? Умение видеть взаимосвязь между явлениями нельзя рассматривать как необязательную опцию. Нам нужен этот навык, чтобы извлекать из массивов данных полезную информацию и уверенно прокладывать курс в океане повседневных решений.
Книга «Почему» научит правильно анализировать данные и определять причинно-следственные связи там, где они есть. Делимся интересными мыслями из нее.
Восприятие и умозаключения
Как вы впервые обнаружили, что лампочка загорается, если повернуть выключатель? Откуда вы знаете, что ружье, выстреливая, производит громкий звук, а не наоборот?
Мы получаем знания о причинах двумя основными путями:
- Восприятие (каузальный опыт). Видя, как в окно влетает кирпич, один бильярдный шар ударяет другой, заставляя катиться, горящая спичка поджигает фитиль свечи, мы получаем впечатления о причинной зависимости на основе входящей сенсорной информации.
- Умозаключения (опосредованные выводы о причинности с помощью дедуктивного метода и на основе некаузальной информации). Причины таких событий, как пищевые отравления, войны и хорошее здоровье, нельзя воспринять непосредственным образом — их предстоит вывести путем логического мышления на основе чего-то, отличающегося от непосредственных наблюдений.
Доверие, которое мы питаем к причинному восприятию, может нас подвести. Если вы слышите громкий звук, а после этого в комнате зажигается свет, легко решить, что эти события взаимосвязаны; однако временная привязка громкого звука и момента, когда некто щелкает выключателем, может быть простым совпадением.

Доверие к причинному восприятию может нас подвести. Источник
Временная и пространственная близость событий — параметры, из-за которых мы нередко делаем ложные выводы.
Например, мы часто слышим, что человеку сделали прививку от гриппа, а к вечеру у него развились схожие с гриппом симптомы, и люди верят, что именно укол стал поводом к этому. Но вакцина против гриппа, содержащая неактивную форму вируса, не может вызвать болезнь. Среди огромного количества привитых у некоторых развиваются другие сходные болезни (по чистому совпадению), или они подхватывают вирус, ожидая приема в клинике.
Время
Близлежащие по времени события могут привести к ошибочным заключениям о причинности. Представьте: у вас разболелась голова и вы приняли некое средство. Через несколько часов боль ушла. Можно ли утверждать, что помогло лекарство?
Временной паттерн позволяет сделать предположение, что ослабление симптома произошло благодаря приему лекарства, однако вы не можете сказать наверняка, что боль не прошла бы сама. Вам пришлось бы провести множество выборочных экспериментов, где вы бы принимали или не принимали препарат, а потом записывали, как быстро исчезала головная боль, чтобы иметь возможность утверждать хоть что-то относительно подобной причинной зависимости. Также пришлось бы сравнить действия лекарства и плацебо.

Причинная зависимость не всегда может быть оправдана. Источник
Длительные задержки между причиной и следствием тоже способны помешать достоверному установлению причинно-следственных связей. Некоторые следствия наступают быстро (удар по бильярдному шару заставляет его двигаться), а некоторые процессы протекают в замедленном режиме. Известно, что курение вызывает рак легких; но между первой сигаретой и днем, когда диагностируют рак, пролегают долгие годы.
Побочные эффекты от приема некоторых препаратов проявляются через десятилетия. Перемены в состоянии здоровья благодаря физическим упражнениям достигаются медленно и не сразу, и, если мы будем ориентироваться только на стрелку весов, может показаться, что вес сначала даже увеличивается, потому что мускулы наращиваются быстрее, чем уходит жир. Ожидая, что следствие должно идти непосредственно за причиной, мы не видим связи между этими глубоко взаимозависимыми факторами.
Корреляция
Корреляция (соотношение, взаимосвязь) не обязательно означает причинную зависимость. Эта мысль прочно вбита в мозги любого студента, изучающего статистику; но порой ошибаются даже те, кто понимает это высказывание и согласен с ним.
Сильная взаимосвязь может показаться убедительной и инициировать ряд успешных прогнозов. Но видимые корреляции иногда объясняются еще не измеренными причинами.
К примеру, мы нашли соотношение в ситуации, когда человек, съевший плотный завтрак, вовремя успевает на работу; однако, вероятно, оба фактора имеют общую причину: человек рано встал, а значит, у него было время хорошо позавтракать, вместо того чтобы в спешке бежать на службу.

Корреляция не обязательно означает причинную зависимость. Источник
Выявив корреляцию между двумя переменными, нужно проверить, способен ли подобный неизмеренный фактор (общая причина) объяснить эту взаимосвязь.
Более того, соотношения способны существовать, даже когда две переменные вообще никак не связаны. Корреляции бывают результатом абсолютной случайности (например, вы много раз за неделю сталкиваетесь с подругой на улице), искусственных условий эксперимента (вопросы могут быть подстроены под конкретные реакции), ошибки или сбоя (баг в компьютерной программе).
Без вариации нет корреляции
Представьте такую ситуацию: вы хотите узнать, как получить грант, поэтому спрашиваете всех друзей, которые его имеют, что, по их мнению, помогло им. Все кандидаты оформляли заявку шрифтом Times New Roman; согласно мнению половины, важно, чтобы на каждой странице была как минимум одна иллюстрация; а треть рекомендуют представить заявку за 24 часа до установленного срока. Означает ли это, что есть корреляция между названными условиями и получением гранта? Нет, не означает.
Поскольку все результаты идентичны, нельзя сказать, что произойдет, если поменять шрифт или представить заявку за минуту до истечения срока.

Без вариации нет корреляции. Источник
И тем не менее широко распространена ситуация, когда анализируются только факторы, ведущие к определенному исходу. Только представьте, насколько часто победителей спрашивают, как именно они добились успеха, а потом стараются этот успех воспроизвести, выполняя в точности те же действия.
Подобный подход полон недостатков по многим причинам, включая то, что люди просто не слишком хорошо умеют определять существенные факторы, недооценивают роль случайностей и переоценивают свои способности. В результате мы не только путаем факторы, которые по чистой случайности сопутствуют желаемому эффекту, с теми, которые действительно его обеспечивают, но и видим иллюзорные корреляции там, где их нет.

Люди не слишком хорошо умеют определять существенные факторы, недооценивают роль случайностей и переоценивают свои способности. Источник
Беседы с победителями бесполезны, поскольку можно сделать то же самое, но не преуспеть. Возможно, все кандидаты оформляют заявки на грант шрифтом Times New Roman (а значит, те, кто не получил гранты, порекомендуют использовать другой шрифт), а может, успешные кандидаты получили грант, несмотря на избыточное количество иллюстраций в документах. Не зная совокупности положительных и отрицательных примеров, мы не сможем даже предположить наличие корреляции.
Ошибка отбора
Одна из важных причин, почему мы ошибаемся с выводами, заключается в том, что данные могут не быть репрезентативными с точки зрения исходного распределения.
Если бы нам разрешили взглянуть на статистику смертей от гриппа, но предоставили только данные о количестве больных, поступивших в лечебные учреждения, мы наблюдали бы гораздо более высокий процент летальных исходов, чем в масштабах всего населения. Это происходит потому, что люди оказываются в стационаре, как правило, с более тяжелыми случаями или дополнительными заболеваниями (и с высокими шансами смерти от гриппа). Так мы сравниваем не все исходы, а только статистику для обратившихся к врачам на фоне симптоматики гриппа.

Данные отбора должны быть репрезентативными. Источник
Или возьмем, к примеру, сайты, опрашивающие посетителей насчет их политических взглядов. В интернете не получится отобрать участников опроса случайно в масштабах всего населения, а данные источников с сильным политическим уклоном искажены еще сильнее.
Если посетители конкретной страницы активно поддерживают действующего президента, то результаты по ним, возможно, покажут, что рейтинг главы государства растет каждый раз, когда он произносит важную речь. Однако это показывает лишь то, что есть корреляция одобрения президента и произнесения им речей перед сторонниками.
Предвзятость подтверждения
Некоторые из когнитивных смещений, заставляющие нас видеть соотношение несвязанных факторов, сходны с ошибкой отбора. К примеру, предвзятость подтверждения заставляет искать доказательства в пользу определенного убеждения.
Иными словами, если вы верите, что лекарство вызывает некий побочный эффект, вы приметесь читать в интернете отзывы тех, кто уже принимал его и наблюдал это действие. Но таким образом вы игнорируете весь набор данных, не поддерживающих вашу гипотезу, вместо того чтобы искать свидетельства, которые, возможно, заставят ее переоценить.
Предвзятость подтверждения также может заставить вас отказаться от свидетельств, противоречащих вашей гипотезе; вы можете предположить, что источник сведений ненадежен или что исследование основывалось на ошибочных экспериментальных методах.

Предвзятость подтверждения. Источник
Помимо предвзятости с точки зрения доказательств, может случиться ошибка интерпретации аргументов. Если в ходе «неслепого» тестирования нового лекарства доктор помнит, что пациент принимает это средство и считает, что оно ему помогает, то может начать искать признаки его эффективности. Поскольку многие параметры субъективны (например, подвижность или усталость), это может привести к отклонениям в оценке данных индикаторов и логическим заключениям о наличии несуществующих корреляций.
Есть и специфическая форма предвзятости подтверждения — иллюзорная корреляция. Она означает поиск соотношения там, где его нет. Возможная взаимосвязь симптомов артрита и погоды настолько широко разрекламирована, что считается доказанной. Однако знание о ней может привести к тому, что пациенты будут говорить о корреляции просто из ожидания ее увидеть. Когда ученые попытались проанализировать эту проблему, взяв за основу обращения пациентов, клинические анализы и объективные показатели, то не обнаружили абсолютно никакой связи.
По материалам книги «Почему».
Обложка поста отсюда.
Мы все через это проходили. Конечно, чаще вы скорее случайным образом колошматите пальцем в кнопки новенькой, излишне навороченной микроволновки, после чего она внезапно оживает. Идет ли речь о спасении от неминуемой гибели или о микроволновой печи, чтобы знать, что X вызвало Y, мозг должен одновременно решить две задачи:
Задача идентификации себя как агента действия — субъектности: это я был?
Задача соотнесения (приписывания) заслуги: какое именно из всех только что совершенных мной действий обусловило Y?
Решить их дико непросто. Мы совершаем множество действий, и последствий у этих действий также множество. Но вокруг постоянно происходит больше штук, чем порождаем и провоцируем мы сами. То есть мозг должен обособить, выделить из этого непрерывного потока обстоятельств критически важный итог Y. Затем ему надо разобраться, мы ли обусловили такой итог, и это при том, что чувственную информацию об этом событии временами подвозят лишь спустя некоторое время после действий, которые могли ее предопределить. Судя по всему, вся эта история сводится к универсальному компоненту всех теорий, пытающихся объяснить работу мозга — дофамину.
У нас есть обстоятельная развернутая гипотеза о том, как нейроны приписывают субъектность (которую также определяют терминами «агентивность» или «агентность») и соотносят последствие с тем действием, которое его обусловило. Она опирается на два важных соображения. Во-первых, в мозге человека есть модель того, как устроен мир, и она постоянно строит прогнозы о том, что должно произойти. Если предсказания не оправдываются, это вызывает изумление — и оттого повлекшее за собой удивление событие выделяется из окружающего потока постоянных ожидаемых, предвычисленных событий.
Во-вторых, мозг отслеживает действия, которые человек только что совершил, и в случае какого-то явления или происшествия их можно связать с воспоминаниями о последних по времени действиях. Как только связь установлена, можно повторить действие и проверить, повлечет ли оно за собой такой же исход. Если да, то раз! — и у нас есть подтверждение причинно-следственной связи.
На сцену выходит наш давний друг дофамин. На первый взгляд, этот нейромедиатор может показаться самым неподходящим способом решить задачу наделения действия X причинностью в отношении исхода Y.
Дофамин выделяется в огромных количествах и сразу во многих областях мозга. В случаях, когда мозгу необходимо подобрать способ для выделения одной конкретной связи между множеством нейронов — скажем, только стыковку нейронов в отношении действия X и последствия Y, дофамин представляется чудовищно неэффективным вариантом.
Однако в действительности он очень ловок. Дофамин — сигнал оповещения. Он незамедлительно и одномоментно сообщает обширным участкам мозга следующее: «Снаружи только что произошло нечто крайне любопытное. Кто из вас, ребзя, готов это взять на себя?»

Он транслирует удивление. Удивление — это сбой в системе построения прогнозов вероятных последующих событий. Есть масса свидетельств того, что дофаминовые нейроны передают весть об ошибке в расчетах о поощрении (вознаграждении). Если мозг сообщает, что ничего поощрительного в ближайшее время не предвидится, после чего совершенно незнакомый человек вручает вам пончик, дофаминовые нейроны резко вспыхивают. Они передают остальной части мозга удивление в связи с тем, что неожиданно случилось нечто приятное. Они как бы твердят: «Не суть важно, чьих рук дело этот внезапный пончик, я жажду от вас повторения!»
Однако ошибки в прогнозах — это не только про вознаграждение или поощрение. Нам также известно, что дофаминовые нейроны еще сигнализируют об ошибках в предсказании неблагоприятных исходов и ситуаций, которых вы хотели бы избежать, — типа нажатия на кнопку, которая запускает в ванную комнату змей.
Так вот эти нейроны сообщают о неточностях в оценке того, сколько времени истекло с момента предыдущего эпизода (события). А еще оповещают о расхождении между тем, что вы намеревались петь, и тем, что вы по факту спели (о да, в среднем мозге промышляет музыкальный критик, а вы разве не знали?)
Все эти примеры того, как различного рода сбои, ошибки и погрешности вызывают кратковременный всплеск дофамина, можно замечательно отразить одним простым соображением — дофаминовые нейроны предупреждают о неожиданности, дают отмашку на удивление. И, что самое важное, этот короткий всплеск дофамина всегда происходит очень скоро после неожиданного события Y. Этот всплеск имеет временную отметку чего-то поразительного, которое творится прямо сейчас.
Итак, мозг обнаружил, что в мире случилась какая-то классная новая вещь, а дофамин доносит это до других зон мозга. Теперь мозг должен узнать, не является ли эта штука последствием каких-то ваших действий, после чего привязать такой итог к этому действию, укрепив связь между ними — и только ними.
Для этого мозгу нужно найти представление (репрезентацию) действий(-я), что имели место до представления итоговых последствий. Все-таки у причинно-следственной связи есть лишь одно направление. Маловероятно, чтобы особый ритуальный танец с кручением курицы, который вы исполнили после того, как включился свет, послужил причиной того, что включился свет. Гораздо вероятнее, что вы, по всей видимости, задели выключатель, вытанцовывая свой путь в комнату (свободной от курицы рукой задели, ясное дело).
Эта стремительная передача дофамина через мозг по сути нацелена на поиск следов действий, которые имели место непосредственно в самом недавнем прошлом. Когда электрический импульс нейрона проносится по основному отростку вперед для передачи сообщения всем запланированным нейронам, он запускает длительный процесс внутри нейрона, в рамках которого различные молекулы медленно меняют свою концентрацию — в особенности кальций. Кроме того, активность на всех входящих соединениях этого нейрона также оставляет после себя следы кальция на этих соединениях, помечая эту входящую связь как потенциально значимую для активирования нейрона.
Теперь дофамин появляется на связи между двумя нейронами. К примеру, один нейрон обусловил действие, оно что-то за собой повлекло, а входной сигнал этому нейрону от другого нейрона сообщает: «Я тут был».
Тогда соединение между этими двумя нейронами закодирует следующую информацию: «Совершите такое-то действие, когда тут есть я». Если нейрон «я тут был» только что вызвал срабатывание нейрона «совершите такое-то действие», значит внутри нейрона действия останутся следы кальция — один, указывающий на активность соединения, а второй — на то, что нейрон действия возбудился. Дофамин обеспечивает наращивание прочности связи между этими двумя нейронами только в случае наличия этих следов. Таким образом, модель «cовершите такое-то действие, когда тут есть я» закрепляется лишь в том случае, если два нейрона были активны в нужный момент.
Что еще более примечательно, судя по всему, мозг выстраивает причинно-следственную связь аккурат в соответствии с распорядком изменения каждой отдельной связи между нейронами. Связь между нейроном A и нейроном B, очевидно, учитывает порядок, в котором срабатывают нейрон A и нейрон B. Если нейрон A срабатывает незадолго до нейрона B, значит по логике он мог обусловить срабатывание нейрона B. Таким связям свойственно укрепляться.

А вот если нейрон A выстрелил вскоре после нейрона B, значит, он в принципе не мог обусловить срабатывание нейрона B. Такая связь, скорее всего, ослабнет. Если нейрон A активизируется задолго до или спустя много времени после нейрона B, сила связи не изменится. Воистину, складывается ощущение, что принципы изменения силы связей были выстроены специально для постижения причинной обусловленности.
И тогда мозг решает задачу соотнесения. Он находит действие X, которое обусловило последствие Y, передавая оснащенный пометкой о времени сигнал о том, что за пределами мозга только что произошло нечто удивительное, и этот сигнал дает желаемый результат, только если обнаружит признаки того, что нейрон действия только что активировался в нужном месте. Теперь в этом самом месте нейроны для действия X активируются с большей вероятностью — а вы с большей вероятностью это действие совершите. Так мы узнаем, действительно ли X вызывает Y, и получаем улучшенную модель предсказания мира.
Задачу идентификации агента теперь решить просто. Как мозг понимает, что это были не вы? Если дофаминовый сигнал срабатывает, а в нейронах действия нет следов активности.
(Окей, бывают нетипичные случаи, когда по случайности нейроны действия активны непосредственно перед итоговым событием, но не явились его причиной. Поэтому действие нужно повторить: если намеренно повторить действие X и оно не вызовет исход Y, значит, свидетельств связи между ними нет).
Поиск ответов на тему того, как мозг распознает причинную связь, — одновременно и передовая линия фронта современной нейробиологии, и затаившаяся в глубине подлодка. В основном глубоко запрятанные элементы теории причинно-следственной связи встречаются в самых разных местах в литературе, но нечасто упомянуты как таковые. Это значит, что область еще предстоит изучать — у нее богатый потенциал и множество не решенных пока вопросов. Вот, к примеру, один из них: а что насчет применения последних обнаруженных данных в будущем?
Изучение причинной связи основано на соображении о том, что мозг оснащен моделью предсказания мира. Но ведь если это так, значит, он, наверное, оснащен и обратной моделью — того, как менять мир. Мы должны иметь возможность сказать «я хочу итог Y» и применить обратную модель для поиска «действия X», обеспечивающую такой исход.
Это значит, что нужно усовершенствовать две модели: прогнозирующую модель («мир должен быть в таком состоянии») и обратную модель («чтобы мир вышел таким, как мне надо, необходимо совершить действие X»). Судя по всему, обе модели завязаны на дофамин. Но где? И обновляются ли они одновременно? Этого мы не знаем. Сколько моделей мира задействует мозг, как они взаимодействуют друг с другом и как их обучать, — это важные вопросы без ответа.

Выяснение причинной связи методом проб и ошибок встречается у разных видов — и животных, и птиц, которые методично связывают последовательность событий («если я сделаю X, за ним последует Y»). Некоторые виды выясняют причинно-следственную связь благодаря мимикрии: лазоревка способна научиться открывать бутылку из-под молока, наблюдая за тем, как это делают другие лазоревки (не советую связываться с лазоревками, серьезно).
Но у человека есть преимущество — речь. Это значит, что мы не связаны необходимостью старательно наблюдать за местными, конкретными цепочками событий.
Мы можем рассказывать о причинах и следствиях словами и передавать это знание в абстрактной форме: книги, журналы, документальные фильмы — и ютуб-видео в 300 частях о том, как пересобрать восьмицилиндровый двигатель. Мы можем записывать свои наблюдения и оставлять пробелы на месте недостающих звеньев цепи между X и Y (это зовется наукой). Мы можем обмениваться информацией и обнаруживать причинно-следственные связи в таких больших выборках и в таком масштабе, что один человек за всю свою жизнь не может осилить.
Сам факт того, что нам известна причинно-следственная связь вымирания каких-то видов или изменения климата, свидетельствует о способности постигать смыслы за пределами местных, конкретных последствий своих действий. Уникальным образом наши мозги могут освоить не только «это все я», но и «это все мы».
Почему её легко упустить и как доказать наличие причинно-следственной связи.
В работе над продуктом часто можно услышать такую логику рассуждений от продакт-менеджера или продуктового аналитика: «Я проанализировал данные и увидел, что пользователи, которые делают Х, с большей вероятностью покупают премиум-версию или становятся успешными». На основе этого инсайта они решают инвестировать время и силы в то, чтобы большая доля пользователей делала X.
Проблема в том, что в этом случае корреляция выдается за причинно-следственную связь. Может быть, там и есть зависимость между переменными, а может быть, это частный случай корреляции, когда рост одной метрики сопровождается ростом другой.
В этом материале разберемся, почему легко упустить разницу между корреляцией и причинно-следственной связью, как доказать наличие причинно-следственной связи и почему это важно при работе над продуктом.
На первый взгляд, выражение «корреляция не означает причинно-следственную связь» не требует дополнительных разъяснений: звучит как прописная истина. Но снова и снова люди с разным уровнем опыта приравнивают эти понятия. Иногда умышленно, а иногда по невнимательности.
Корреляция и причинно-следственная связь
Корреляция — это взаимосвязь между двумя переменными, при которой изменение одной из них сопровождается изменением в другой. Здесь важно подчеркнуть слово«сопровождается», поскольку при корреляции эти изменения могут происходить без прямого влияния одной переменной на другую.
В ситуации же, когда такое прямое влияние доказано — можно говорить о причинно-следственной связи.
Пример корреляции может звучать так:
Рост потребления мороженого сопровождается ростом числа лесных пожаров.
Cнижение потребления маргарина сопровождается снижением количества разводов.
Отличие корреляции от причинно-следственной связи
У корреляции может быть несколько причин. Например, на две переменные влияет некий третий фактор, как в случае с ростом продаж мороженого и лесными пожарами. Этот фактор — теплое время года и высокая интенсивность солнечного излучения.
В случае с корреляцией не всегда можно идентифицировать другие факторы, которые влияют на обе переменные, а иногда их может не быть вовсе. В таком случае уместно говорить о случайности. Одновременное снижение числа разводов и потребления маргарина — пример такой ложной корреляции (spurious correlation).
В чем отличие корреляции от причинно-следственной связи?
Причинно-следственная связь всегда подразумевает наличие корреляции. Корреляция не обязательно означает наличие причинно-следственной связи. Корреляция может быть случайной, но причинно-следственная связь по определению не может быть случайностью.
Если корреляция есть, то для доказательства причинно-следственной связи должны соблюдаться еще два условия:
- Отсутствие сторонних факторов, которые влияют на обе переменные;
- Прямая временная последовательность между изменением первого и второго показателя, между событием A и событием B.
Хотя разница между корреляцией и причинно-следственной связью кажется очевидной, на практике принять одно за другое очень просто.
Примеры корреляций, которые ошибочно принимают за причинно следственную связь
Рассмотрим типовые ситуации из жизни, когда наличие корреляции приводит к ложному выводу о наличии причинно-следственной связи в бытовых ситуациях.
В своей книге «Thinking, Fast and Slow» Daniel Kahneman (Даниэль Канеман) описывает случай на лекции для израильских летчиков. Один из инструкторов настаивал, что курсанты лучше справляются с задачей после того, как он жестко критикует их за ошибки. Канеман предложил провести эксперимент, в ходе которого эти курсанты должны были не глядя дважды бросить монетку в нарисованную на полу мишень. Опыт показал: те, у кого первый бросок был ближе к цели, во второй раз бросали не так точно. И наоборот.
Таким экспериментом Канеман продемонстрировал феномен регрессии к среднему. Когда летчик очень плохо или очень хорошо исполнил упражнение, то часто для него это было отклонением от среднего значения. Поэтому с высокой вероятностью его следующее исполнение будет ближе к среднему, то есть лучше или хуже предыдущего.
Получается, что не критика помогала курсантам показывать лучшие результаты после провального опыта, а регрессия к среднему. Инструктор ошибочно принял корреляцию между критикой и улучшением результатов курсантов после нее за причинно-следственную связь.
Некоторые широко известные убеждения тоже являются корреляцией, которая маскируется под причинно-следственную связь.
Например, идея о том, что занятия музыкой в дошкольном возрасте улучшают когнитивные способности, память и внимание ребенка. Хотя корреляция между этими факторами действительно может быть, говорить о прямой причинно-следственной связи нельзя, так как на результат может влиять масса факторов.
Может быть, занятия музыкой для ребенка требуют от семьи дополнительных финансовых ресурсов. То есть, если семья может направить деньги не только на базовые потребности, но и на дополнительное образование, с высокой вероятностью ребенок имеет доступ к лучшему питанию, лучшему основному образованию и другим благам, которые могут позитивно отражаться на интеллекте ребенка.
Еще один пример.
В одном из материалов Washington Post пришла к выводу, что рост затрат на полицию в США не привел к сокращению преступности. Автор через кажущееся отсутствие прямой корреляции пытается опровергнуть причинно-следственную связь между событиями: увеличение бюджета полиции не приводит к пропорциональному сокращению уровня преступности.
Но говорить о том, что здесь обязательно должна быть причинно-следственная связь, нельзя. Например, именно рост преступности может быть драйвером расходов на полицию, а не наоборот. Без тщательного исследования мы не можем утверждать ни того, ни другого.
Корреляция в бизнесе
В 2013 году eBay тратил десятки миллионов долларов на поисковую рекламу по брендовым запросам “eBay”. В компании были уверены, что рост продаж обусловлен именно покупным трафиком. Но исследование показало, что реклама оказалась направлена как раз на ту аудиторию, которая в любом случае совершила бы покупку на eBay.
В данном случае именно намерение пользователей совершить покупку приводило и к показу рекламы, и к продажам на площадке. В eBay же думали, что именно реклама выступала причиной, а продажи — ее следствием.
Корреляцию часто ошибочно принимают за причинно-следственную связь при анализе успеха чужих продуктов со стороны. «Продукт А выстрелил и нашел product/market fit, благодаря фиче X. Мы можем повторить успех, добавив ту же фичу в нашем продукте и на нашем локальном рынке».
Допустим, что продукт А действительно стал успешным после того, как внедрил определенную фичу. Но нельзя назвать причиной сам факт добавления фичи. Причина зачастую более комплексна и опирается на массу факторов. Но главное, что для определенного сегмента пользователей продукт решает некоторую задачу эффективнее всех доступных альтернатив.
Например, WeChat Pay набрал популярность как платежный инструмент в Китае не потому, что они соединили мессенджер и платежный инструмент. Дело в том, что этот инструмент стал намного более эффективной альтернативой наличным деньгам, поэтому его добавочная ценность оказалась столь высока, а продукт — столь успешным.
На этом фоне становится понятно, почему Facebook Messenger так тяжело давались попытки запустить свой платежный сервис. Просто прикрутить функциональность к мессенджеру недостаточно, потому что на рынке США гораздо сильнее развиты платежные инструменты, а значит, добавочная ценность решения от Facebook для клиента менее ощутима или не ощутима вовсе.
Корреляция в работе над продуктом
Работа над продуктом подразумевает постоянные вопросы о причинах тех или иных изменений в метриках. И зачастую велик соблазн объяснить их через что-то, что мы сделали осознанно и недавно. Однако важно помнить, что продукт и пользователи не существуют в вакууме.
Пример с притоком пользователей в продукт
Вы фиксируете приток пользователей за последнюю неделю, а перед этим вы добавили в продукт новую большую фичу. Кажется, что продуктовое изменение привело к росту.
Однако позже выясняется, что приток пользователей в ваш продукт стал следствием того, что ваш прямой конкурент резко ограничил возможности базового тарифа. Ваш отдел маркетинга заметил это и стал активно использовать этот аргумент в разных каналах коммуникации. Отсюда — приток новых пользователей.
Между добавлением новой фичи и приростом пользовательской базы действительно была корреляция. Но, как мы выяснили, причина этого роста скрывалась в другом.
Пример с монетизацией мобильной игры
Работая над мобильной игрой, вы заметили, что пользователи, которые подключают соцсети, делают больше покупок. На этом этапе может возникнуть соблазн предположить наличие между событиями причинно-следственную связь и решить, что увеличение конверсии игроков в подключение соцсетей пропорционально увеличит выручку с таких пользователей. Если это правда так, то у вас есть множество гипотез, как повлиять на этот параметр.
Однако на деле в такой ситуации вполне может быть еще один или несколько факторов, которые одинаково влияют и на первое, и на второе явление. Скрытым от глаз фактором может быть то, что пользователи, которые и активно подключают соцсети, и чаще делают покупки, просто изначально сильнее мотивированы и больше заинтересованы в игре. То есть это не подключение соцсетей влияет на их поведение, а изначальная предрасположенность к игре.
Если это так, то на практике активное навязывание пользователям возможности подключиться к соцсети в действительности не даст никакого результата. С другой стороны, сразу решить, что такое навязывание не даст никаких изменений, тоже нельзя. Чтобы выяснить это, нужно провести эксперимент.
Как эксперименты помогают доказать причинно-следственную связь
Суеверия, псевдонаучные дисциплины и архаичные методы лечения появились во многом благодаря путанице между корреляцией и причинно-следственной связью. Так появились ритуалы, которые призывают дождь, и жертвоприношения, которые гарантируют удачную охоту и богатые урожаи.
Примерно такой подход прослеживается в древней и средневековой медицине. Например, эффективным способом поправить здоровье больного считалось кровопускание. Если пациент после этой процедуры выживает, то успех приписывается именно ей. Если нет, то значит, болезнь была слишком сильной.
То есть в этом случае корреляция между процедурой и выздоровлением не только ложная, но и избирательная.
Мы не случайно упомянули архаичные методы лечения, потому что именно развитие медицины дало дорогу появлению эффективных методов доказательства причинно-следственной связи.
Одним из важнейших этапов на пути развития доказательной медицины стало проведение в середине XX века первого рандомизированного контролируемого испытания (randomized controlled trial). Его суть заключается в том, чтобы взять две группы людей — тестовую и контрольную, — и одной вручить лекарство, а другой плацебо. Отсутствие различий в других переменных позволяет сделать вывод о влиянии лишь одного конкретного фактора.
В интернете практика подобных испытаний получит название A/B-тестов.
A/B-тестирование для проверки наличия причинно-следственной связи
Вы наблюдаете корреляцию между событиями X и Y. Но для принятия решения вам нужно понять, есть ли между ними причинно-следственная связь.
Для ответа на этот вопрос надо провести эксперимент.
Например, когда одна группа пользователей получает фичу, а другая нет. Все остальные условия для них идентичны. По итогам теста собираются и анализируются данные. На их основе вы можете понять, оказала ли фича влияние на интересующую нас метрику.
Хотя порядок действий и звучит просто, на деле проведение A/B-тестов требует внимания ко множеству деталей и дисциплины. В частности, вам нужно быть очень аккуратными, чтобы не спутать случайное изменение в значение целевой метрики с влиянием тестируемого изменения. Для этого используется понятие статистической значимости — подробнее об этом читайте здесь.
Понимание корреляции и причинно-следственной связи уберегает от ошибок и помогает глубже видеть продукт
В работе над продуктом легко принять корреляцию за причинно-следственную связь. Допускают такую ошибку в разных случаях: либо человек не знает про эту разницу, либо — что чаще — знает в теории, но не всегда может заметить на практике, либо умышленно хочет выдать одно за другое, чтобы добиться желаемого.
Путанице между корреляцией и причинно-следственной связью способствуют различные когнитивные искажения, например confirmation bias или иллюзия контроля. Confirmation bias заставляет нас отметать те факторы, которые не укладываются в желаемую картину происходящего. Иллюзия контроля создает впечатление, что мы знаем о продукте все и понимаем, что и отчего напрямую зависит.
Понимать разницу между корреляцией и причинно-следственной связью важно, чтобы не прийти к ошибочным решениям или не потратить время и ресурсы без какого-либо результата.
Проверка гипотез через эксперименты, дотошное выяснение причин тех или иных наблюдаемых изменений не только помогает ответить на один конкретный вопрос (например, почему падает конверсия в покупку), но и позволяет глубже понять продукт. Такое понимание помогает находить новые инсайты и увеличивать ценность продукта для пользователей.
Чтобы глубже разобраться в том, как создаются, развиваются и масштабируются продукты, пройдите обучение в симуляторах GoPractice.
- «Симулятор управления продуктом на основе данных» поможет научиться принимать решения с помощью данных и исследований при создании продукта.
- «Симулятор управления ростом продукта» поможет найти пути управляемого роста и масштабирования продукта. Вы построите модель роста и составите стратегию развития продукта.
- «Симулятор SQL для продуктовой аналитики» поможет освоить SQL и применять его для решения продуктовых и маркетинговых задач.
- Не знаете с чего начать? Пройдите бесплатный тест для оценки навыков управления продуктом. Вы определите свои сильные стороны и слепые зоны, получите план профессионального развития.
- Ещё больше ценных материалов и инсайтов — в Telegram-канале GoPractice.

В любом важном научно-исследовательском проекте автору предстоит грамотно диагностировать и описать проблему, оценить текущее положение дел (следствие) и выработать оптимальное решение, способное разрешить все нюансы и привести к положительному исходу (избежать больших потерь). Но на самом деле важно не просто констатировать «уязвимое звено» и показать ее воздействие на объект, но и установить причинно-следственные связи.
Что это такое?
Прежде чем решать какую-либо проблему, важно понять: почему она возникла, что спровоцировало такие изменения? Поэтому каждому автору предстоит провести целый комплекс действий и определить потенциальные или реальные первопричины негативных перемен и текущих событий. Согласитесь, ведь у каждого начала есть свое основание, причина, определенный толчок. Уже на этой почве у автора зарождаются определения предположения-гипотезы, которые он должен проверить. Ведь целесообразно лечить не симптом болезни, а первопричину.
Установление причинно-следственных связей в исследовании предполагает определение связей между конкретными событиями, результатами и определение степени воздействия каждого элемента или фактора в этой цепи на объект. Такой подход позволяет определить «самое слабое звено» и определить максимально эффективную траекторию по решению проблемы.
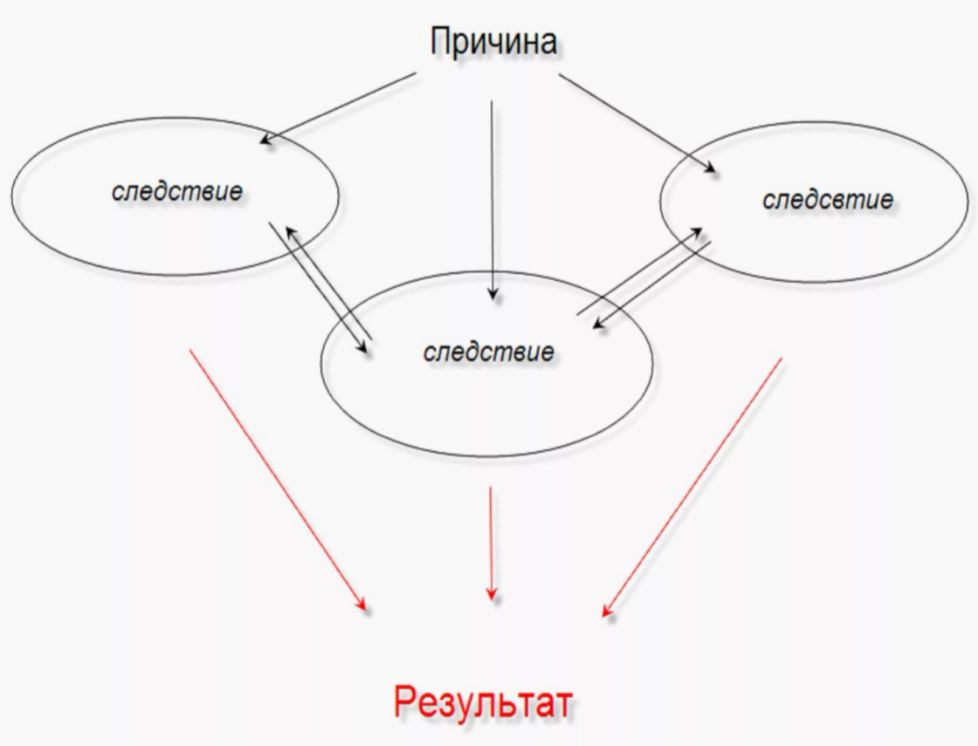
Анализ причинно-следственных связей можно представить, как уникальный метод исследования, применяемый в любой студенческой и научно-исследовательской работе.
Этапы установления причинно-следственных связей в НИР
Установить причинно-следственную связь бывает непросто, но очень важно. Поэтому мы подготовили инструкцию по реализации действия для констатации основных моментов:
- Анамнез: для начала автору необходимо собрать максимум информации относительно объекта исследования и/или по теме НИР. Притом важно изучать не только текущее положение дел, но и иметь на руках сведения за последние 3-5 лет для определения динамики, изменения, оценки принимаемых ранее решений и пр.
Миссия данного этапа – сбор и проверка информации на предмет актуальности, достоверности и обоснованности;
- Непосредственная оценка положения: на данной стадии целесообразно изучить общее положение дел в науке и на объекте, провести первичную диагностику «проблемных зон» и определить конкретную причину, которая в значительной степени ухудшает деятельность компании/объекта. Здесь же уместно сформировать общую характеристику объекта исследования, проанализировать основные технико-экономические показатели или провести анализ согласно описанной в теории методике для получения информации относительно действующих проблем и нюансов.
Основная задача данного этапа – осмыслить текущие процессы, определить динамику основных показателей и характер изменений, выделить первичный (явные) проблемные зоны. Здесь же целесообразно определить признаки изменений и симптомы проблемы (как она начала проявляться и на каком этапе).
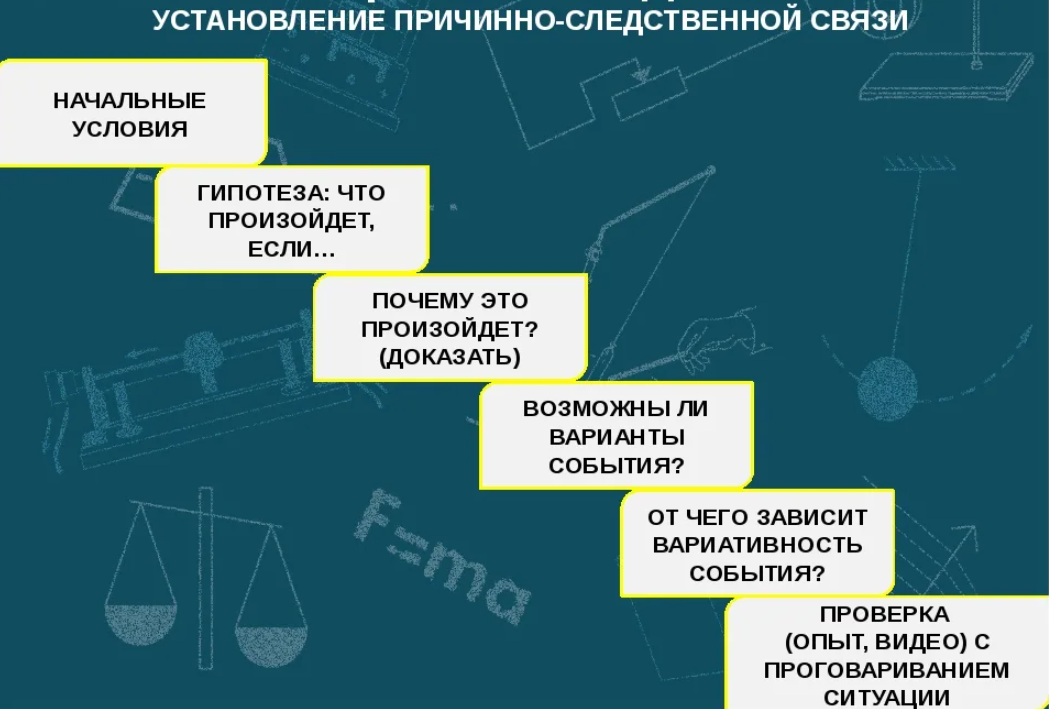
- Определение доминирующего фактора-провокатора, негативных изменений и существенных признаков, свидетельствующих об ухудшении ситуации. Здесь целесообразно выделить наиболее яркие, сильные изменения показателей в худшую сторону (из ранее реализованной методики) и провести факторный анализ для констатации первопричин (какой показатель или элемент провоцирует ухудшение и почему). Притом проводить оценку необходимо в динамике. Главное – определить степень воздействия доминирующего фактора на следствие (текущий результат). Фактически результаты данного этапа позволят определить корректирующее направление: что следует изменять и как;
- Описание установленной причинно-следственной связи с констатацией фактов по схеме: первопричина – проблема – действия – следствие.
Далее на основе полученных результатов автор НИР вырабатывает план мероприятий по решению проблемы, где будет опираться на устранение первопричины (доминирующего фактора) и проверять выработанный механизм: прогнозирование результатов или их апробация.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

Методы установления причинно-следственных связей в студенческих и научно-исследовательских работах
Диагностика причинно-следственных связей сводится не просто к осмыслению и поиску ответа на вопрос: почему возникла проблема и как ее решить? Для проведения констатации первопричины необходимо разобраться в ситуации «от» и «до». Для этого авторы НИР и студенты применяют следующие простые, но эффективные приемы и методы.
Вариант №1. Метод сходств. Суть данного приема сводится к установлению схожих черт в одном и том же событии, но в разных временных периодах или условиях. Притом доминирующим фактором будет считаться именно схожий признак.
Например, один и тот же результат Р достигается при выполнении определённый условий: АВС, АВД, АЛТ. Во всех случаях сходство очевидно – условие А. Тогда можно предположить, что именно этот параметр является «провокатором».
Вариант №2. Метод различий. Для реализации данного сценария необходимо анализировать две ситуации со схожим или одинаковым результатом. Притом здесь важно установить, при каком действии в первой ситуации возникает явление, а во втором оно не происходит (то есть выявить различие). Если ситуации отличаются между собой только конкретным параметром и ли обстоятельством, то скорее всего он и есть первопричина.
Например, явление С появляется при выполнении комбинаций действий АВС и ВСВ. При второй комбинации результат достигается быстрее, но действия разнятся. Скорее всего, ухудшает или тормозит процесс условие А.
Вариант №3. Метод сопутствующих изменений или факторный анализ. Здесь главное расчленить масштабное событие на составные и взаимосвязанные звенья, а затем поочередно меняя их оценивать характер изменений. Данный прием чаще всего используется в технических, экономических, естественнонаучных исследованиях, где результат можно рассчитать на основе конкретной формулы.
Вариант №4. Эксперимент. Здесь исследователь реализует один и тот же опыт несколько раз. Если он допускает изменения в действиях, схемах и формулах, то обязательно должен их зафиксировать и отметить полученный результат, а затем оценить его характер. При реализации одного и того же эксперимента (по принципу «1 в 1») он перепроверяет достоверность результатов. Чаще всего такой прием реализуется в психологических, социологических и маркетинговых, педагогических исследованиях.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Принципы и роли причинно-следственных связей в исследовании
Определение причинно-следственных связей в студенческих и научно-исследовательских работах предполагает соблюдение простейших правил, которые гарантируют верность дальнейших суждений и решений:
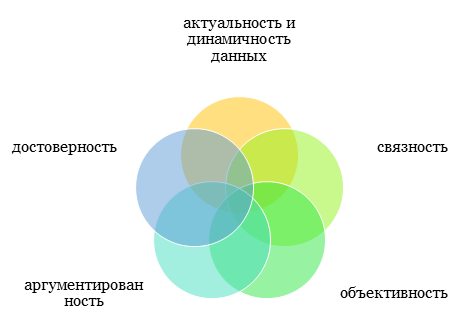
- Актуальность и динамичность данных. Данный момент предполагают, что автору предстоит основательно оценивать текущее положение дел, то есть полагаться на актуальные (свежие, текущие) данные, а также сопоставлять их в динамике (с показателями предшествующих периодов, базовыми или нормативными данными);
- Достоверность. При констатации причин, следствий и связей важно использовать только подлинные и проверенные данные, официальные ресурсы, научную литературу, отчетность и пр. В противном случае все полученные результаты будут банальными домыслами и не более того.
- Связность. Анализ причинно-следственных связей призван показать связь между явлениями и процессами и определить, какое именно з них оказало негативное воздействие на объект и результат. Без связи между событиями понять первопричину не удастся.
- Объективность. При оценке ситуации автор НИР не должен быть прямо заинтересован в исходе событий. Важно учитывать всевозможные факторы и события, оценивать их доступными способами.
- Аргументированность. Все выводы автора по результатам причинно-следственного и факторного анализа должны быть обоснованными и базироваться на конкретных фактах: расчеты, результаты сравнительного анализа и т.д.
Роль установления причинно-следственных связей в студенческих и научно-исследовательских работах велика, так как именно установление первопричины способствует выработке эффективного и оптимального (по срокам, действиям и пр.) мероприятиям по решению проблемы. Притом автору удастся устранить не симптом, а именно «корень зла», гарантировав оптимизацию, улучшение ситуации и минимизировав аналогичный рецидив (повторение).
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Оформление процесса установления причинно-следственных связей в НИР
Сам по себе алгоритм констатации провоцирующего фактора и первопричины, спровоцировавшей ухудшение ситуации, раскрывается на протяжении всей работы, начиная с теории – где описывается общая методика исследования, и заканчивая практикой – где она поэтапно реализуется с углублением в отдельные моменты.
Самый оптимальный вариант оформления данного исследовательского процесса – это использование графических и табличных данных с анализом материалов, отраженных в них.
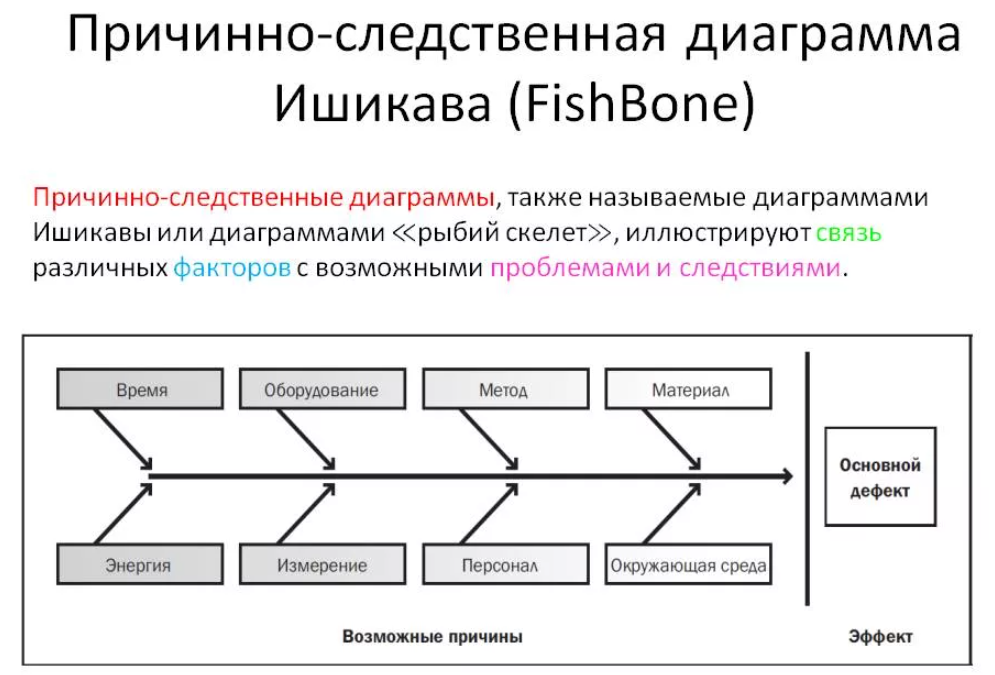
Также допускается для установления общей картины использовать диаграмму Ишикавы (Исикавы), которая отразит конечный результат (следствие), основные факторы и «подфакторы». Далее, их анализ позволит выявить доминант и определить стратегию и тактику по решению проблемы.
Аналитика и процесс выявления причинно-следственных связей строится на вышеописанных методах и приемах, аналитике и грамотной формулировке полученных результатов с учетом принципа научной аргументации: полученные результаты должны быть оценены с научной и практической точек зрения.
Конечное выделение причинно-следственной связи должно быть сформулировано в выводах по главе и заключении по схеме: первопричина – проблема (причина) – действия – следствие – план мероприятий по решению проблемы – оценка результатов.
Общее оформление процесса должно соответствовать типичными ГОСТам и параметрам при выполнении курсовых, дипломных, диссертационных работ и НИР, специфическим требованиям отрасли (чертежи, расчеты, программы, документация и пр.).
 ODS'21.")
Мы привыкли, что Machine Learning предоставляет нам большое количество предиктивных методов, которые с каждым годом предсказывают события лучше и лучше. Деревья, леса, бустинги, нейронные сети, обучение с подкреплением и другие алгоритмы машинного обучения позволяют предвидеть будущее все более отчетливо. Казалось бы, что нужно еще? Просто улучшать методы и тогда мы рано или поздно будем жить в будущем так же спокойно, как и в настоящем. Однако не все так просто.
Когда мы рассматриваем бизнес задачи, мы часто сталкиваемся с двумя моментами. Во-первых, мы хотим понять что к чему относится и что с чем связано. Нам важна интерпретация. Чем сложнее модели мы используем, тем более нелинейные они. Тем больше они похожи на черную коробку, в которой очень сложно выявить связи, понятные человеческому разуму. Все же мы привыкли мыслить довольно линейно или близко к тому. Во-вторых, мы хотим понять — если мы подергаем вот эту «ручку», изменится ли результат в будущем и насколько? То есть, мы хотим увидеть причинно-следственную связь между нашим целевым событием и некоторым фактором. Как сказал Рубин — без манипуляции нет причинно следственной связи. Мы часто ошибочно принимаем обыкновенную корреляцию за эту связь. В этой серии статей мы сконцентрируемся на причинах и следствиях.
Но что не так с привычными нам методами ML? Мы строим модель, а значит, предсказывая значение целевого события мы можем менять значение одного из факторов — одной из фич и тогда мы получим соответствующее изменение таргета. Вот нам и предсказание. Все не так просто. По конструкции, большинство ML методов отлично выявляют корреляцию между признаком и таргетом, но ничего не говорят о том, произошло ли изменение целевого события именно из-за изменения значения фичи. То есть, ничего не говорят нам о том — что здесь было причиной, а что следствием.
Чтобы прояснить о чем я, давайте посмотрим на задачу с другой стороны — чуть более формальной. Часто можно встретить следующую запись для модели машинного обучения:
![]()
Здесь y — наше целевое событие, a(X) — некоторый ML алгоритм,  — неустранимая ошибка. На самом деле a(X) в уравнении выше мы не знаем и часть просто предполагаем, что он именно такой, исходя из известных нам свойств целевого события и признакового пространства.
— неустранимая ошибка. На самом деле a(X) в уравнении выше мы не знаем и часть просто предполагаем, что он именно такой, исходя из известных нам свойств целевого события и признакового пространства.
После «обучения» модели, мы получаем оценку алгоритма  , с помощью которого получаем предсказания:
, с помощью которого получаем предсказания:
![]()
При этом, существует некоторая ошибка нашей оценки  , которую мы можем найти. Наш алгоритм строится с целью минимизации различных функций потерь от предсказания и фактического значения целевой переменной.
, которую мы можем найти. Наш алгоритм строится с целью минимизации различных функций потерь от предсказания и фактического значения целевой переменной.
Вернемся к основному вопросу. Предположим, среди наших X присутствует некоторый признак, через который мы можем влиять на таргет, что мы очень хотим делать. Назовем его T. Оставшееся множество признаков обозначим
![]()
Для того, чтобы это вписать в нашу формулу, предлагаю записать множество признаков следующим образом:  . Тогда наше предсказание выглядит:
. Тогда наше предсказание выглядит:
![]()
Под «воздействием» мы понимаем следующее: действительно ли, меняя T в реальности, я изменю y? Обозначим
![]()
Записывая строго (и предпологая определенный вид распределения ошибки и данных), мы хотим, чтобы следующее утверждение было верно:
![]()
То есть, мы хотим, чтобы изменив T мы получили результат и были уверены в нем также, как если бы он был изменен естественным образом. Однако, оказывается, что модели машинного обучения часто так не работают. Они находят корреляции, но это не значит, что изменив наше воздействие мы изменим результат.
Иллюстрацию этого удобно привести с помощью графа причинно-следственных связей. Подробности этого мы оставим за пределами этой статьи, но то, что я покажу будет понятно на интуитивном уровне. Предположим, наши данные описываются следующим образом:
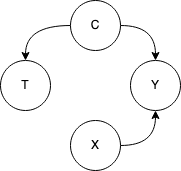
Здесь стандартно: Y — таргет, X — признаки объекта, T — наше воздействие. За C мы принимаем здесь так называемый Confounder — переменную, воздействующую на T и на Y. Если переменная C является не наблюдаемой для нас, то стандартная модель машинного обучения, глядя на корреляцию между изменениями T и Y сможет заметить эту связь. Однако, очевидно что изменяя T мы не изменим Y — для этого должна измениться C! Здесь мы увидели частный случай проблемы эндогенности — проблема упущенной переменной. Видно, что когда мы пытаемся не просто найти корреляции между переменными и прогнозировать изменения в таргете, исходя из наблюдений, а пытаемся влиять на таргет — все становится немного сложнее.
Давайте попробуем также посмотреть на проблемы причинно-следственной связи с точки зрения их отличий от проблем Machine Learning и Statistical Learning. Отличная иллюстрация приводится в книге Elements of Causal Inference: Foundations and Learning Algorithms (Peters et al., 2017):
 с учетом этих связей.")
Ещё одна иллюстрация, которая помогает понять эволюцию мысли от корреляции к причинно-следственной связи (из книги The Book of Why: The New Science of Cause and Effect (Judea Pearl, Dana Mackenzie)):

Но давайте вернемся к эндогенности. Следующий раздел для того, чтобы узнать или вспомнить что же это такое.
Эндогенность
Строго говоря, эндогенность — это корреляция объясняющей переменной (признака) с ошибкой. В математической записи это выглядит следующим образом:

Если говорить о предыдущем примере, то в нем как раз это и происходит, за счет того, что  . Давайте посмотрим — какие еще бывают варианты эндогенности.
. Давайте посмотрим — какие еще бывают варианты эндогенности.
Принято выделять следующие проблемы:
-
Проблема упущенной переменной (omitted variable)
-
Обратная причинно-следственная связь (reverse causality)
-
Ошибка в измерениях (measurement error)
Все эти типы эндогенности отличаются присутствием корреляции ошибки и одного из признаков.
Выглядит очень теоретически. К чему это приводит на практике? Сейчас приготовьтесь испытать дежавю (особенно, если вы смотрели телевизор в последние несколько лет):

.")
Поставим себя на место парламентария — законотворца, который к нашему всеобщему сожалению не освоил отличие корреляций от причинно-следственных связей. Дабы укрепить семейные связи в первом случае наш герой может принять решение запретить маргарин к примеру. Это будет логично. Во втором случае, для спасения жизней своих сограждан он, пожалуй, предложит наложить эмбарго на продажу японских автомобилей, что вызовет политическую напряженность, но главное, что благое дело сделано. И, наконец, он избавит граждан США от заразы науки и технологий, тем самым пытаясь значительно снизить смертность. Что ж, может быть и не стоит изучать причинно-следственные связи, в конце концов срок депутата ограничен.
Задача
Что ж, надеюсь, что вы как минимум порадовались, посмотрев на красивые картинки, теперь перейдем к задаче, которую мы излагали в докладе. Перед нами стояла проблема улучшения системы ценообразования для товаров (мобильной техники и аксессуаров) с целью повышения прибыли бизнеса с партии этих товаров. Давайте разберем эту формулировку по словам, чтобы понять — что же от нас хотят. Начнем с конца:
-
Партия товаров
Я предлагаю рассматривать некоторый аксессуар. Например, некоторое универсальное зарядное устройство для смартфонов. Для простоты, пусть его технология не будет подвержена старению, хотя бы на горизонте года. Пусть его продажи несильно зависят от выхода новых моделей смартфонов. Партия (stock) это заранее известный объем закупки. Мы можем воспринимать её как набор зарядных устройств, который мы купили, скажем, в январе и следующая поставка будет через год.
-
Повышение прибыли
Прибыль давайте также понимать довольно просто. Это наша выручка (цена, умноженная на количество проданного товара) минус наши издержки (стоимость закупки). Цену хранения единицы товара будем считать пренебрежимо малой. В конце концов, для зарядных устройств это очень близко к правде. Записывая формально:

Здесь
 — прибыль, — розничная цена, — количество проданного товара, -оптовая цена закупки товара.
— прибыль, — розничная цена, — количество проданного товара, -оптовая цена закупки товара.
 — прибыль,
— прибыль,  — розничная цена,
— розничная цена,  — количество проданного товара,
— количество проданного товара,  -оптовая цена закупки товара.
-оптовая цена закупки товара.-
Улучшение системы ценообразования Из предыдущего упрощенного уравнения не понятно — причем здесь цена? Максимум для
здесь достигается за счет увеличения цены до бесконечности. Но на то она и упрощенная. Давайте сделаем её чуть реалистичней:Здесь мы отразили немного больше зависимостей. Очевидно, объем проданного товара зависит от цены. При этом, чем выше цена, тем меньше объем продаж. При этом, закупка у нас фиксирована и мы имеем закупленную партию как факт, так что цена закупки — константа.
 здесь достигается за счет увеличения цены до бесконечности. Но на то она и упрощенная. Давайте сделаем её чуть реалистичней:
здесь достигается за счет увеличения цены до бесконечности. Но на то она и упрощенная. Давайте сделаем её чуть реалистичней:
Казалось бы, давайте просто решим простейшую задачу оптимизации и выставим оптимальную цену. Но, все не так просто. Во-первых у нас целый год. Все, что не будет продано за год будет продаваться с большим дисконтом и приносить убыток, хранить это станет также дорого. Мы можем считать, что все, что не продано за год — выброшено.
Во-вторых, есть конкуренты и, повышая цену, мы теряем в продажах гораздо больше, чем было бы, будь мы монополистами. В-третьих, у нас может быть очень мало истории колебания цен, чтобы выявить зависимость q(p) при больших изменениях цены.

Начнем с казалось бы более простых задач и попробуем решить все проблемы, которые описали выше и некоторые другие.
Оптимальная цена
Начнем с выставления оптимальной в моменте цены. Как выставить эту цену?

На помощь здесь конечно придет простейшая теория оптимизации и основы микроэкономики. Решим задачу оптимизации, дабы найти оптимальную цену. Из FOC:
![]()
$$ $$
И что мы видим? Нам позарез нужно понять зависимость q(p) для решения уравнения. Для начала мы решили оценить её с помощью простой модели линейной регрессии:
![]()
Здесь X — набор признаков, и, соответственно, коэффициентов при нем тоже несколько, надеюсь, никого не запутает такая нотация.  предполагаем i.i.d (это очень сильное предположение, особенно учитывая автокорреляцию ошибок, если мы смотрим во времени, но, чтобы не размывать целей примера, здесь я не буду углубляться в решение этой задачи).
предполагаем i.i.d (это очень сильное предположение, особенно учитывая автокорреляцию ошибок, если мы смотрим во времени, но, чтобы не размывать целей примера, здесь я не буду углубляться в решение этой задачи).
В результате решения этой задачи мы можем получить некую оценку  , которая показывает нам каким образом количество продаж товара зависит от цены. Звучит это просто, но на деле конечно нас ждут не дождутся проблемы:
, которая показывает нам каким образом количество продаж товара зависит от цены. Звучит это просто, но на деле конечно нас ждут не дождутся проблемы:
-
На каждый товар не так много наблюдений, потому есть большой риск не увидеть статистической значимости в нашем коэффициенте
-
Есть товары, цена которых исторически не менялась, а значит наша модель не сработает для них в целом (нарушены базовые предположения OLS)
-
Есть товары, для которых мы видим положительную оценку
(как бы вы интерпретировали её?)
 (как бы вы интерпретировали её?)
(как бы вы интерпретировали её?)Так как мы являемся последователями стоической философии, то мы представляли даже худшие варианты развития событий — такие как столкновение с метеоритом или чума, так что то, что мы увидели нас даже обрадовало. Какие идеи у нас возникли для решения этих задач?
Число наблюдений
Очевидным способом борьбы с этой бедой кажется объединение товаров в одну выборку. Но каким образом различать их? Предположим, что зависимости не универсальны и не отличаются от товара к товару. Первой попыткой может быть добавить dummy переменные (или fixed effects) на различные товары. Но тогда мы добавим огромное число переменных и выигрыш от объединения будет крайне невелик.
Есть другой вариант — в рамках одного класса товаров, давайте опишем их некоторыми признаками, присутствие которых обусловленно классом товара, а их значения могут отличаться от одного товара к другому. Например, если это зарядные устройства, то они могут различаться типом, производителем, мощностью. Таким образом мы, вводя некоторые вполне валидные предположения, выиграем от роста количества наблюдений.
Отсутствие изменения цены
Здесь мы можем пойти двумя путями. Первый уже произошел автоматически. В результате перехода от индивидуальных товаров к их группе, мы уже добавили вариацию в цену (предполагая единую зависимость от цены для всей группы). Второй путь — рандомизация. Для тех товаров, которые не имели исторических изменений в цене, мы можем волевым усилием устроить случайные изменения цены в разумных пределах.
Положительная корреляция цены и продаж
Эта проблема интересна, особенно в контексте нашей прошлой дискуссии о причинно-следственной связи и проблеме эндогенности. Давайте подумаем — может ли быть такое, что повышая цену мы начинаем продавать больше товара? Вполне возможно, но рост продаж вряд ли будет объясняться ростом цены, особенно в контексте наших товаров. Переводя на графический язык, положительный коэффициент говорит нам о следующей зависимости между ценой и продажами:
Думаю этот график довольно наглядно показывает, что как бы нам ни хотелось ничего не делать с этим коэффициентом — не выйдет. Маловероятно, что повышая цену мы добьемся этим увеличения продаж. В противном случае, нам стоило бы поставить цену на данное зарядное устройство равной бесконечности и перепрофилировать бизнес.
И снова эндогенность
Мы задумались. То ли половина наших товаров “неправильные”, то ли здесь где-то зарыта какая-то другая собака 🐕 . Тут мы вспоминаем про проблемы эндогенности, которые мы недавно разбирали в теории и думаем — возможно ли что где-то здесь мы столкнулись с одной из них? Вполне. Давайте посмотрим что это могло быть. Огласим весь список снова:
-
Упущенная переменная
-
Обратно причинно-следственная связь
-
Ошибка измерений
Предположим, что третье мы можем исключить. Мы верим нашим данным — там все хорошо и нет систематически искажающей результаты ошибки. Что насчет остальных?
Упущенная переменная. Вполне может быть. Что если мы в рамках года взяли только осень и забыли включить сезонную компоненту в анализ? Мы увидим повышение цен на товары (которое мы проводили) и повышение спроса. Более того, здесь мы чувствуем сразу присутствие и второй проблемы — мы повысили цену зная, что будет повышение спроса, а значит, повысятся продажи, а значит мы можем безболезненно поднять цену, чтобы подогнать оптимальную под возросший спрос. Вот вам и обратная причинно-следственная связь.
Еще? Давайте подумаем. Конкуренты. Что если в момент повышения наших цен — конкуренты подняли цены ещё больше. Все покупатели конечно расстроились, что такое вот происходит, но пришли к нам, так как у нас стало дешевле. Тогда можно сказать, что цены конкурентов являются упущенной переменной. Включив её, мы скорректируем нашу ошибку, наш bias.
Можно продолжить. Но зачем? Эти упражнения полезны и интересны для кого-то, но помогают ли они нам решить проблему на практике? Как получить адекватную и близкую к реальной зависимость спроса от предложения? Очень просто. Omitted variable, которую мы можем таки отыскать, мы можем просто включить в регрессионную модель, тем самым скорректировав отклонение. Однако кто гарантирует, что мы не забыли что-нибудь? Кто гарантирует, что мы включили все упущенные переменные, а тем более — кто гарантирует, что мы не забыли где-нибудь обратную причинно следственную связь? Что с ней делать?
Здесь нам на помощь приходят инструментальные переменные.

Стандартно инструментальные переменные обозначаются как Z. На картинке выше видно, что инструментальная переменная должна быть подобрана так, чтобы воздействовать на итоговую зависимую переменную только через treatment переменную, которую мы хотим избавить от эндогенности (в случае на картинке — от unobserved confounder).
Давайте посмотрим как выглядит наша проблема в более строгой формулировке.
![E[hat{beta}] = E[(X^TX)^{-1}(X^TY)] = E[(X^TX)^{-1}(X^T(Xbeta+epsilon))]\ = E[beta+X^Tepsilon] = beta + E[X^Tepsilon]](https://habrastorage.org/getpro/habr/upload_files/936/5d6/d52/9365d6d52d3fd8e304892f30b8be74f1.svg)
Второе слагаемое и есть bias, который мы получаем за счет эндогенности. Если существует переменная, коррелирующая с Y и X, соответственно
![]()
Классический пример использования инструментальной переменной — 2-stage least squares (2SLS) оценка. Название может подсказать нам, что этот метод имеет нечто общее с OLS (ordinary least squares) или МНК оценкой.
Шаги здесь следующие и довольно простые. Пусть у нас есть парочка инструментальных переменных  . Также есть наша переменная
. Также есть наша переменная  являющаяся эндогенной (в нашем примере — это цена). Тогда два этапа выглядят так:
являющаяся эндогенной (в нашем примере — это цена). Тогда два этапа выглядят так:
-
Оценить OLS:
где
— экзогенные иксы , а — инструментальные переменные для . В итоге получим некоторую . -
Наша оценка получается из подстановки результата предыдущего этапа вместо
Так как экзогенная по определению, то при выполнении некоторых предположений несмещенной оценкой является :

 — экзогенные иксы
— экзогенные иксы  , а
, а  — инструментальные переменные для
— инструментальные переменные для  . В итоге получим некоторую
. В итоге получим некоторую  .
. Так как
Так как  экзогенная по определению, то при выполнении некоторых предположений несмещенной оценкой
экзогенная по определению, то при выполнении некоторых предположений несмещенной оценкой  является
является  :
:
Мы здесь опустили некоторые предположения касательно инструментов, но это все же статья не только об инструментальных переменных и не такая техническая, как это возможно, поэтому интересующихся отсылаю к наилучшему источнику по теме: J.M. Wooldridge, Econometric Analysis of Cross Section and Panel Data, Chapter 5.
А не слабовато?
Вкратце — все конечно зависит от инструментов, но в целом, часто мы получаем достаточно маломощные оценки интересующего нас эффекта. В случае нашей задачи — оценки эластичности цены. Чем мощнее эта оценка, тем точнее мы можем оптимизировать цену и тем меньше изначальная выборка нам требуется для этой оптимизации.
Method of Direct Estimation
Данный метод был представлен в статье M. Ratkovic, D. Tingley, Causal Inference Through the Method of Direct Estimation. Он позволяет проводить оценку причинно-следственных связей, фокусируясь на мгновенном причинно-следственном эффекте (instantaneous causal effect), который иначе можно рассматривать как причинно-следственный эффект на уровне одного наблюдения. В своей статье Ratkovic and Tingley строят регрессию с высокой степенью нелинейности между ковариатами и treatment переменной (это например наша цена), которую затем используют для предсказания альтернативных исходов (counterfactuals). Другими словами, они строят регрессию, а затем, подставляя другие значения treatment переменной пытаются понять что с этим наблюдением было б если бы все было иначе.
Пока это выглядит немного смазанно. Давайте посмотрим подробнее на алгоритм, думаю станет понятней.
Пусть наша цена — treatment и обозначим её за T. Также, спрос (который у нас является таргетом) обозначим за Y(T). Причинно-следственный эффект изменения цены на спрос можно тогда обозначить за
![]()
здесь  , a
, a  , где дельта — небольшое изменение нашей цены. В пределе мы хотим оценить частную производную:
, где дельта — небольшое изменение нашей цены. В пределе мы хотим оценить частную производную:
![]()
Здесь видно, что если мы оценим  линейной моделью, то получим просто коэффициент при эффекте воздействия. Однако мы не хотим делать предположения о линейной зависимости и добавляем нелинейные взаимодействия тритмента и переменных. В статье предлагается вид:
линейной моделью, то получим просто коэффициент при эффекте воздействия. Однако мы не хотим делать предположения о линейной зависимости и добавляем нелинейные взаимодействия тритмента и переменных. В статье предлагается вид:
![]()
 — параметры модели,
— параметры модели,  — B-spline базис. Далее предлагается отфильтровать нелинейные компоненты при помощи L1 регуляризатора. Полученное подмножество называем
— B-spline базис. Далее предлагается отфильтровать нелинейные компоненты при помощи L1 регуляризатора. Полученное подмножество называем  . В дальнейшем после оценки параметров регрессии мы получаем искомый предел как:
. В дальнейшем после оценки параметров регрессии мы получаем искомый предел как:
![]()
Казалось бы, все просто. Однако здесь нигде не учитывается эндогенность. Как мы оценим то же самое, если включим инструментальные переменные?
В статье предлагается аналог 2SLS оценки, называемый LICE (Local Instantaneous Causal Effect). Во-первых, оценивается так называемый instantaneous encouragement — эффект от небольшого изменения инструмента на одном наблюдении. Он показывает эффект от изменения инструмента на тритмент (переменную воздействия):
![]()
Вторая часть оценки LICE — instantaneous intent to treat on the treated — показывает эффект от изменения инструмента на целевую переменную:
![]()
Итак, в итоге:

Можно показать, что:

Отсюда видно, что для фиксированных параметров наблюдения мы можем предсказать эффект от воздействия на него, имея наше воздействие T и инструментальную переменную Z.
ML модификация MDE
Мы не удовлетворились имеющимися моделями линейной регрессии и решили обобщить метод на работу с произвольным алгоритмом следующим образом. Давайте для начала посмотрим как выглядят модели линейной регрессии в статье:

Заменим линейную регрессию на произвольный алгоритм:

В качестве алгоритмов мы выбрали модели случайного леса. И конечно это лишь звучит просто, в дальнейшем возникло много особенностей ввиду того, что в общем случае решение, выдаваемое лесом не является гладким, так что нам пришлось аппроксимировать его гладкой функцией. Но об этом в другой раз.
Во второй части этой статьи вы узнаете как мы в итоге решили проблему негладкости решения, а также как реализовали систему динамической оптимизации цены. Надеюсь эта статья была вам полезна, ну или хотя бы расширила ваш кругозор. Спасибо!