|
0 / 0 / 0 Регистрация: 08.09.2018 Сообщений: 9 |
|
|
1 |
|
Вывести символы строки с нечётными номерами, не используя условный оператор28.09.2018, 00:58. Показов 41607. Ответов 5
Здравствуйте! Подскажите, пожалуйста, как вывести символы строки с нечётными номерами, не используя условный оператор?
0 |

|
ioprst 1303 / 843 / 409 Регистрация: 12.03.2018 Сообщений: 2,305 |
||||
|
28.09.2018, 08:41 |
2 |
|||
|
S[i:j:step] — извлечение среза
0 |
|
0 / 0 / 0 Регистрация: 08.09.2018 Сообщений: 9 |
|
|
28.09.2018, 10:40 [ТС] |
3 |
|
ioprst, Ваш код находит элементы индексы, которых кратны двум, т. е. чётные, спасибо за Ваш ответ, но нужно найти нечётные индексы
0 |
|
Semen-Semenich 4467 / 3147 / 1112 Регистрация: 21.03.2016 Сообщений: 7,837 |
||||
|
28.09.2018, 10:48 |
4 |
|||
|
Решение
1 |
 Сообщение было отмечено Nasty99 как решение
Сообщение было отмечено Nasty99 как решение
|
0 / 0 / 0 Регистрация: 08.09.2018 Сообщений: 9 |
|
|
28.09.2018, 10:53 [ТС] |
5 |
|
Semen-Semenich, спасибо
0 |

|
ioprst 1303 / 843 / 409 Регистрация: 12.03.2018 Сообщений: 2,305 |
||||
|
28.09.2018, 11:00 |
6 |
|||
|
РешениеNasty99, да, перепутал.
2 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
28.09.2018, 11:00 |
|
6 |
I’m trying to figure out how to remove every second character (starting from the first one) from a string in Javascript.
For example, the string «This is a test!» should become «hsi etTi sats!»
I also want to save every deleted character into another array.
I have tried using replace method and splice method, but wasn’t able to get them to work properly. Mostly because replace only replaces the first character.
function encrypt(text, n) {
if (text === "NULL") return n;
if (n <= 0) return text;
var encArr = [];
var newString = text.split("");
var j = 0;
for (var i = 0; i < text.length; i += 2) {
encArr[j++] = text[i];
newString.splice(i, 1); // this line doesn't work properly
}
}
![]()
adiga
34.1k9 gold badges60 silver badges82 bronze badges
asked Mar 24, 2019 at 20:32
![]()
2
You could reduce the characters of the string and group them to separate arrays using the % operator. Use destructuring to get the 2D array returned to separate variables
let str = "This is a test!";
const [even, odd] = [...str].reduce((r,char,i) => (r[i%2].push(char), r), [[],[]])
console.log(odd.join(''))
console.log(even.join(''))Using a for loop:
let str = "This is a test!",
odd = [],
even = [];
for (var i = 0; i < str.length; i++) {
i % 2 === 0
? even.push(str[i])
: odd.push(str[i])
}
console.log(odd.join(''))
console.log(even.join(''))answered Mar 24, 2019 at 20:50
![]()
adigaadiga
34.1k9 gold badges60 silver badges82 bronze badges
It would probably be easier to use a regular expression and .replace: capture two characters in separate capturing groups, add the first character to a string, and replace with the second character. Then, you’ll have first half of the output you need in one string, and the second in another: just concatenate them together and return:
function encrypt(text) {
let removedText = '';
const replacedText1 = text.replace(/(.)(.)?/g, (_, firstChar, secondChar) => {
// in case the match was at the end of the string,
// and the string has an odd number of characters:
if (!secondChar) secondChar = '';
// remove the firstChar from the string, while adding it to removedText:
removedText += firstChar;
return secondChar;
});
return replacedText1 + removedText;
}
console.log(encrypt('This is a test!'));answered Mar 24, 2019 at 20:38
![]()
2
Pretty simple with .reduce() to create the two arrays you seem to want.
function encrypt(text) {
return text.split("")
.reduce(({odd, even}, c, i) =>
i % 2 ? {odd: [...odd, c], even} : {odd, even: [...even, c]}
, {odd: [], even: []})
}
console.log(encrypt("This is a test!"));They can be converted to strings by using .join("") if you desire.
answered Mar 24, 2019 at 20:41
![]()
ziggy wiggyziggy wiggy
1,0396 silver badges6 bronze badges
I think you were on the right track. What you missed is replace is using either a string or RegExp.
The replace() method returns a new string with some or all matches of a pattern replaced by a replacement. The pattern can be a string or a RegExp, and the replacement can be a string or a function to be called for each match. If pattern is a string, only the first occurrence will be replaced.
Source: String.prototype.replace()
If you are replacing a value (and not a regular expression), only the first instance of the value will be replaced. To replace all occurrences of a specified value, use the global (g) modifier
Source: JavaScript String replace() Method
So my suggestion would be to continue still with replace and pass the right RegExp to the function, I guess you can figure out from this example — this removes every second occurrence for char ‘t’:
let count = 0;
let testString = 'test test test test';
console.log('original', testString);
// global modifier in RegExp
let result = testString.replace(/t/g, function (match) {
count++;
return (count % 2 === 0) ? '' : match;
});
console.log('removed', result);answered Mar 24, 2019 at 20:47
![]()
norbitrialnorbitrial
14.6k7 gold badges32 silver badges58 bronze badges
like this?
var text = "This is a test!"
var result = ""
var rest = ""
for(var i = 0; i < text.length; i++){
if( (i%2) != 0 ){
result += text[i]
} else{
rest += text[i]
}
}
console.log(result+rest)answered Mar 24, 2019 at 20:51
![]()
user3469811user3469811
6761 gold badge5 silver badges17 bronze badges
Maybe with split, filter and join:
const remaining = myString.split('').filter((char, i) => i % 2 !== 0).join('');
const deleted = myString.split('').filter((char, i) => i % 2 === 0).join('');
answered Mar 24, 2019 at 21:02
![]()
mbojkombojko
13.2k1 gold badge16 silver badges25 bronze badges
1
You could take an array and splice and push each second item to the end of the array.
function encrypt(string) {
var array = [...string],
i = 0,
l = array.length >> 1;
while (i <= l) array.push(array.splice(i++, 1)[0]);
return array.join('');
}
console.log(encrypt("This is a test!"));answered Mar 24, 2019 at 21:06
![]()
Nina ScholzNina Scholz
374k25 gold badges344 silver badges386 bronze badges
function encrypt(text) {
text = text.split("");
var removed = []
var encrypted = text.filter((letter, index) => {
if(index % 2 == 0){
removed.push(letter)
return false;
}
return true
}).join("")
return {
full: encrypted + removed.join(""),
encrypted: encrypted,
removed: removed
}
}
console.log(encrypt("This is a test!"))Splice does not work, because if you remove an element from an array in for loop indexes most probably will be wrong when removing another element.
answered Mar 24, 2019 at 20:38
![]()
matvsmatvs
1,72316 silver badges26 bronze badges
2
I don’t know how much you care about performance, but using regex is not very efficient.
Simple test for quite a long string shows that using filter function is on average about 3 times faster, which can make quite a difference when performed on very long strings or on many, many shorts ones.
function test(func, n){
var text = "";
for(var i = 0; i < n; ++i){
text += "a";
}
var start = new Date().getTime();
func(text);
var end = new Date().getTime();
var time = (end-start) / 1000.0;
console.log(func.name, " took ", time, " seconds")
return time;
}
function encryptREGEX(text) {
let removedText = '';
const replacedText1 = text.replace(/(.)(.)?/g, (_, firstChar, secondChar) => {
// in case the match was at the end of the string,
// and the string has an odd number of characters:
if (!secondChar) secondChar = '';
// remove the firstChar from the string, while adding it to removedText:
removedText += firstChar;
return secondChar;
});
return replacedText1 + removedText;
}
function encrypt(text) {
text = text.split("");
var removed = "";
var encrypted = text.filter((letter, index) => {
if(index % 2 == 0){
removed += letter;
return false;
}
return true
}).join("")
return encrypted + removed
}
var timeREGEX = test(encryptREGEX, 10000000);
var timeFilter = test(encrypt, 10000000);
console.log("Using filter is faster ", timeREGEX/timeFilter, " times")
Using actually an array for storing removed letters and then joining them is much more efficient, than using a string and concatenating letters to it.
I changed an array to string in filter solution to make it the same like in regex solution, so they are more comparable.
answered Mar 25, 2019 at 21:35
![]()
matvsmatvs
1,72316 silver badges26 bronze badges
Я должен сделать это для школы, но я не могу решить это. Я должен получить данные и вывести ТОЛЬКО нечетные символы. Пока что я поместил ввод в список, и у меня есть цикл while (который был подсказкой на листе задач), но я не могу разобраться с этим. Пожалуйста помоги:
inp = input('What is your name? ')
name = []
name.append(inp)
n=1
while n<len(name):
2015-11-20 18:37
2
ответа
Решение
print inp[1::2]
Я думаю, это все, что вам нужно
2015-11-20 18:39
Вам не нужно помещать строку в список, строка по сути уже является списком символов (более формально это «последовательность»).
Вы можете использовать индексирование и оператор модуля (%) за это
inp = input('What is your name? ')
n = 0 # index variable
while n < len(inp):
if n % 2 == 1: # check if it is an odd letter
print(inp[n]) # print out that letter
n += 1
2015-11-20 18:40
Другие вопросы по тегам
python
АТАТА: распутываем задачу про палиндром
Время на прочтение
4 мин
Количество просмотров 11K
Очень часто авторы алгоритмических задач делают ход конём: они берут задачу с простыми формулировками, заменяют их сложными и непонятными эквивалентами и выдают вам «сложную» задачу. В этом посте мы разберём пример одной такой задачи и обсудим пару полезных для её решения приёмов. Задача будет про палиндром.

Продолжение под катом.
Что такое палиндром
Палиндромом называется строка, которая одинаково читается как слева направо, так и справа налево. Например, слово «АТАТА» — это палиндром, а вот слово «АЙАЙАЙ» — нет.

Пример палиндрома из латинских слов: он составлен таким образом, что в каком бы направлении вы ни начали читать текст, получится одно и то же
Известный кинематографический палиндром — название вышедшего в 2020 году фильма «Довод» (англ. «Tenet»). Русская адаптация в каком-то плане уникальна, потому что у нас нашлась подходящая альтернатива слову «tenet», которая тоже является палиндромом. На многих других языках (в том числе славянских) название фильма оставили как есть. Например, на украинском это «ТЕНЕТ» (Википедия).
Постановка задачи
Итак, задача. Подготовьтесь морально.
Нечётным палиндромом будем называть такую строку, у которой все подстроки нечётной длины являются палиндромами. Суть задачи в том, чтобы в данной строке заменить не более K символов так, чтобы максимизировать длину самой длинной подстроки, которая является нечётным палиндромом.
Всё, клубок запутался. Начнём распутывать.
Вот несколько примеров нечётных палиндромов: «ATATA», «KKKKKKKK», «ABA», «ZO».
Рассмотрим подробнее первую строку — АТАТА. Выпишем все её подстроки нечётной длины:
- A, T, A, T, A — однобуквенное слово всегда палиндром
- ATA, TAT, ATA — очевидно, палиндромы
- ATATA — тоже
В слове ZO нет подстрок нечётной длины больше чем в одну букву. И «Z», и «O» — палиндромы, поэтому «ZO» — нечётный палиндром.
Пусть нам дана строка ABCDEF, и мы можем заменить не более одного символа (K=1), чтобы сделать из неё нечётный палиндром. Оптимальным решением было бы, например, заменить первую букву на C, тогда мы получили бы CBCDEF, где длина наибольшей подстроки, являющейся нечётным палиндромом, была бы равна трём (это CBC).
С тем же успехом мы могли бы прийти к варианту ABCFEF.
А вот если изначально у нас была строка ZXXXZ, и опять можно изменить не более одного символа, то надо заменить средний, так как ZXX и XXZ не являются палиндромами. В итоге мы получим ZXZXZ.
Структура нечётного палиндрома
Теперь заметим кое-что в рассмотренных примерах. Все нечётные палиндромы имеют схожую структуру: в них чередуются буквы (или все буквы одинаковые). И это действительно единственная форма, которую имеет нечётный палиндром. Почему это так?
Посмотрим ещё раз на определение: нечётным палиндромом будем называть такую строку, у которой все подстроки нечётной длины являются палиндромами. Если все подстроки нечётной длины являются палиндромами, то и все подстроки длины 3 являются палиндромами. Отсюда сразу же следует, что на чётных позициях не может быть двух различных букв, то же самое верно для нечётных.
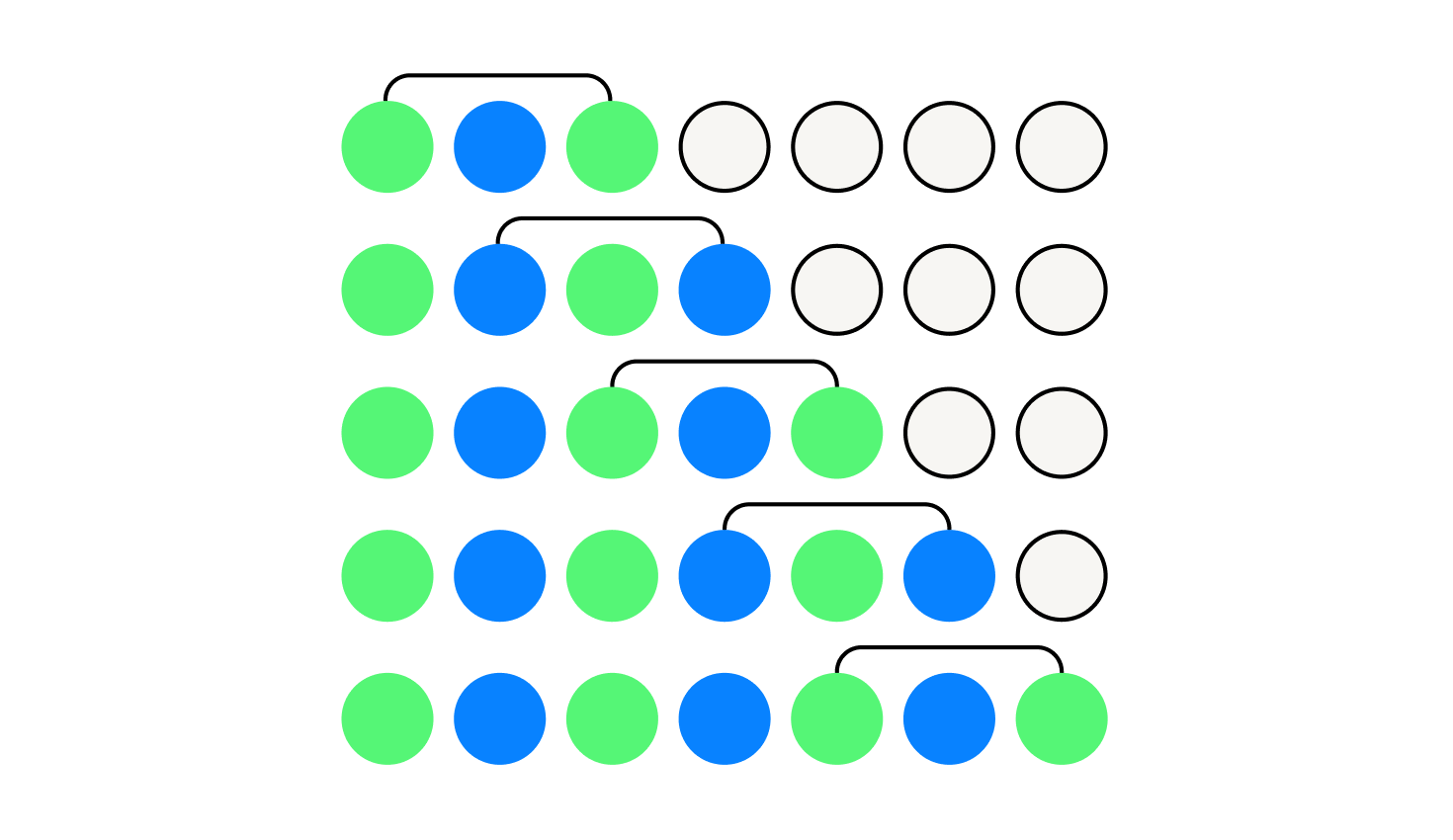
На рисунке выше показано, как получается чередующаяся структура строки. Одинаковым цветом выделены одинаковые символы. Сначала посмотрим на палиндром длины 3, который начинается в самом первом символе исходной строки. Тогда 1 и 3 символ можно пометить зеленым. Про 2-й символ пока ничего непонятно. Сдвинем палиндром на единицу вправо, получим, что 2 и 4 символы можно покрасить в один цвет. Так, сдвигаясь каждый раз на единицу, мы получим, что все символы на нечётных позициях зелёные, а на чётных — синие. Более строго можно доказать этот факт с помощью метода математической индукции, например.
Теперь, когда мы поняли, что надо искать, вернёмся непосредственно к задаче. Для краткости будем называть подстроки, которые являются нечётными палиндромами, хорошими. Надо изменить не более K символов так, чтобы максимизировать длину хорошей подстроки в последовательности.
Сперва разберёмся, как сделать из произвольной подстроки хорошую. Надо заменить на один и тот же символ все элементы на чётных позициях и отдельно заменить на нечётных.
Чтобы сделать как можно меньше замен, стоит выбрать в качестве единого символа самый частый среди тех, что стоят на чётных или нечётных позициях. Найти самый частый символ можно с помощью словаря (хеш-мапа, хеш-таблицы) отдельно для чётных и нечётных позиций. Алфавит в текущей задаче ограничен 26 символами, поэтому счётчик будет занимать константное количество дополнительной памяти.
Пройдёмся один раз по строке и добавим единицу в ячейку нужного словаря по текущему символу. Далее найдём в каждом словаре самый частый символ (если символов с максимальным числом вхождений несколько, то можно выбрать любой). Именно на этот символ надо заменить все элементы на чётных или нечётных позициях.
Наивное решение
Теперь попробуем сделать как можно более длинную хорошую подстроку, которая начинается строго в символе с номером L. Указатель R будет отмечать ту позицию, до которой мы сумели расширить хорошую подстроку. Будем шагать указателем R вправо, начиная от позиции L. На каждом шаге будем учитывать в счётчике символов для чётных и нечётных позиций очередной символ. Прежде чем передвинуть R на шаг вправо, проверим по счётчикам, что сделать подстроку с L до R хорошей можно не более чем за K операций.
Если применить описанные действия независимо для всех L от 0 до n – 1, где n — длина исходной строки, а затем найти наиболее длинную найденную хорошую подстроку, то мы решим задачу. Однако временная сложность данного решения составит O(n^2), так как для каждой позиции L мы сделаем в худшем случае примерно n – L шагов при передвижении R.
Улучшаем асимптотику решения
Мы можем ускорить это решение с помощью техники двух указателей. Не будем обнулять счётчики и сбрасывать позицию R после того, как максимально отошли вправо от L. Переиспользуем текущую информацию при переходе от L к L+1. Для этого надо убрать из счётчиков элемент на позиции L — и всё. Затем можно продолжать делать проверки и отодвигать R вправо до тех пор, пока не исчерпаются K операций изменения элементов.
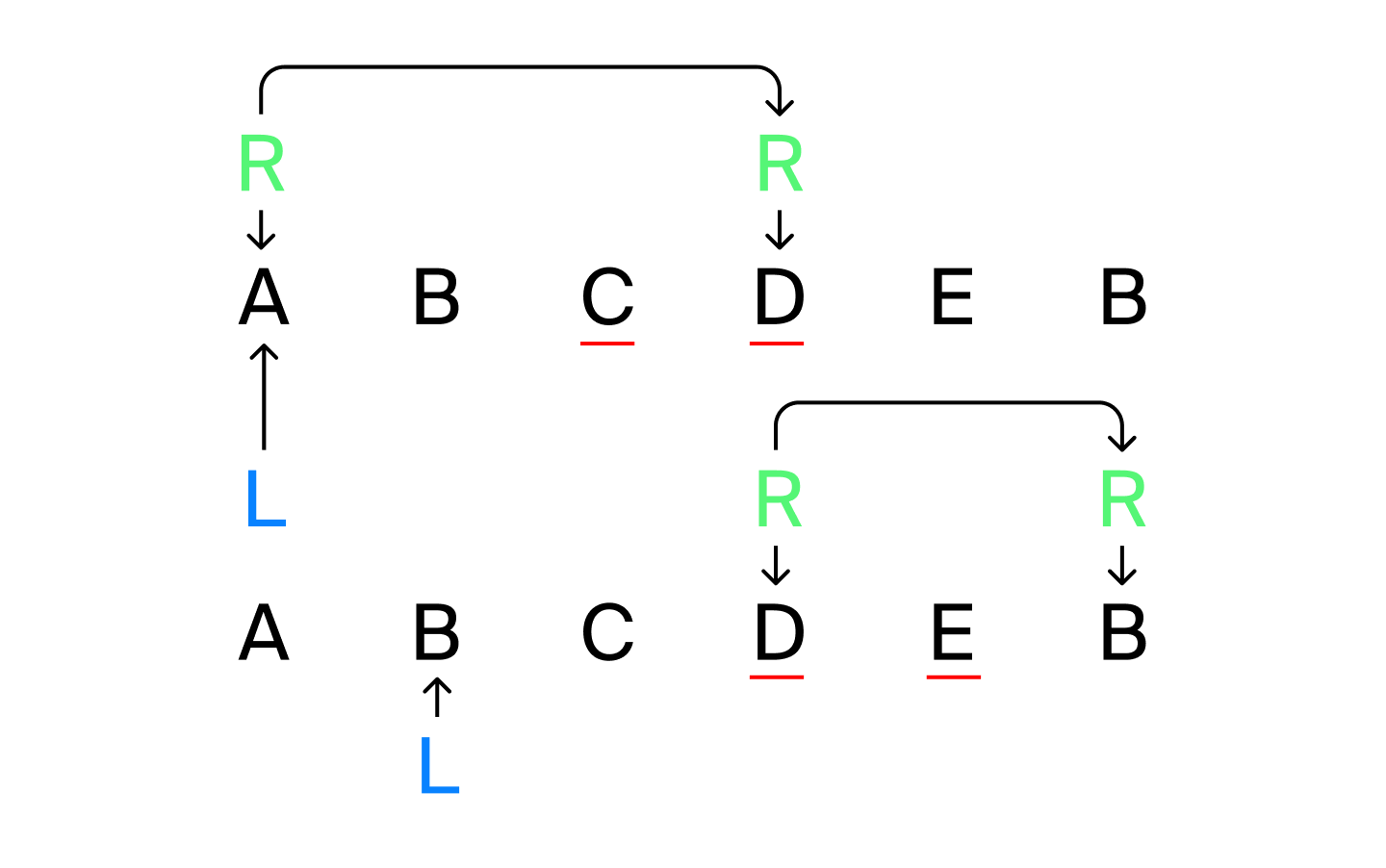
На рисунке выше показан ход указателей L и R, K=2. Подчёркнутые символы будут изменены при соответствующих L и R
Оценим сложность новой версии алгоритма. Указатель R суммарно сделает не более n шагов вправо, указатель L — тоже. Передвижение указателя сопровождается обновлением счётчиков и проверкой числа изменений для получения хорошей подстроки — эти действия выполняются за константное время, O(1). Таким образом мы получаем сложность O(n).
Мы выпутались из этой задачи, теперь можно запутываться в какую-нибудь другую.
Подробнее про метод двух указателей и про другие интересные приёмы мы рассказываем на курсе «Алгоритмы и структуры данных». Если вам интересна эта тема, приглашаю на наш курс.
Нечетное: буквы
Задача
Напишите программу или функцию (или эквивалент), которая сортирует и возвращает нечетную букву в матрице случайного размера.
подробности
Вам будет передана матрица (в виде строки) в качестве ввода случайных размеров, таких как эта.
bbbbbbbbbb bbbbbdbbbb bbbbbbbbbb bbbbbbbbbb bbbbbbbbbb
Ваша задача — найти букву, которая не соответствует остальным (в данном случае она находится dв строке 2, столбец 6), и вернуть эту букву в качестве вывода. Матрица будет состоять из букв A-Z, a-zновых строк ( nтолько на концах строк) и иметь размеры от 5×5 до 10×10 (25-100 букв).
Применяются стандартные лазейки. Это кодовое соревнование по гольфу; запись с кодом младшего байта выигрывает.
вход
Ввод будет передан через стандартный ввод в виде строки, если это программа, или в качестве аргумента, если функция (или аналогичная).
Выход
Единственный символ , который является «нечетным» в матрице или None , nil, NULили строка , "None"если нет «нечетного» характера.
Больше примеров
AAAAAAA AAAAAAA AAAAAAA AAAIAAA AAAAAAA
Ответ: I
vvqvvvvvvv vvvvvvvvvv vvvvvvvvvv vvvvvvvvvv vvvvvvvvvv
Ответ: q
puuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu uuuuuuuuu
Ответ: p
Генератор
Вот генератор случайных матриц, написанный на Python, который вы можете использовать для тестирования своей программы. Примечание: есть небольшая вероятность того, что он мог ошибиться и не вставить нечетную букву.
Ответы:
J , 12 10 7 байт
-.}./.~
Попробуйте онлайн!
/.~ Group identical items together
}. Remove one item from each group
-. Remove the rest from the input
10-байтовая версия
-._1 1{:~
Hisss …
:~ Sort down
_1 1{ Take the last character (which is a newline) and the second one.
-. Remove those from the input
Брахилог , 8 4 байта
oḅ∋≠
Попробуйте онлайн!
объяснение
Я не использовал Brachylog раньше, так что это не может быть оптимальным.
oḅ∋≠ Input is a string.
o Sort the input.
ḅ Split it into blocks of equal elements.
∋ There is a block
≠ whose elements are all different.
That block is the output.
K (ок) , 7 6 байтов
Решение
*<#:'=
Попробуйте онлайн!
Пример:
*<#:'="vvqvvvvvvvnvvvvvvvvvvnvvvvvvvvvvnvvvvvvvvvvnvvvvvvvvvv"
"q"
Объяснение:
Найден несколько более короткий подход: оценивается справа налево:
*<#:'= / the solution
= / group matching items together
#:' / count (#:) each (')
< / sort ascending
* / take the first one
Заметки:
Хотя я ожидаю, что бонусный аспект этого испытания будет отброшен, это решение вернет символ новой строки, nесли не будет нечетного символа:
*<#:'="vvvvvvvvvvnvvvvvvvvvvnvvvvvvvvvvnvvvvvvvvvvnvvvvvvvvvv"
"n"
Пролог (SWI) , 46 байт
p(L):-select(X,L,Y),+member(X,Y),writef([X]).
Попробуйте онлайн!
Или если стандарт правда вывод от запросов пролога не в порядке:
Пролог (SWI) , 48 байт
Z*L:-select(X,L,Y),+member(X,Y),char_code(Z,X).
Попробуйте онлайн!
объяснение
Find the first element X in the input
that when removed, results in output
that does not contain X
then depending on the version above either:
print X as a character
or
return X as an atom
C (gcc) , 93 92 90 66 62 байта
Намного короче как функция
t;f(char*p){for(t=*p;*p;)t^*p++?putchar(*p^*--p?*p:t),*p=0:0;}Попробуйте онлайн!
тестовый код
main()
{
char s[99];
for(;gets(s);)f(s);
}старая версия это программа
C 86 байт
char*p;s[9];main(t){for(;p=gets(s);)for(t=*p;*p;)t^*p++?putchar(*p^*--p?*p:t),*p=0:0;}Выводит нечетный символ или ничего. беги так;
C:enggolf>python matrix_gen.py | a.exe
X
C:enggolf>python matrix_gen.py | a.exe
G
C:enggolf>python matrix_gen.py | a.exe
x
C:enggolf>python matrix_gen.py | a.exe
C:enggolf>python matrix_gen.py | a.exe
J05AB1E , 4 2 байта
Сохранено 2 байта благодаря Аднану
.m
Попробуйте онлайн!
объяснение
.m # push a list of the least frequent character(s) in input
Сетчатка , 13 байт
s(O`.
(.)1+
Попробуйте онлайн!
объяснение
s(O`.
Сортировать все символы.
(.)1+
Удалите все символы, которые появляются как минимум дважды.
Шелуха , 2 байта
◄=
Попробуйте онлайн!
Это функция, принимающая строку в качестве входных данных и возвращающая символ. Он берет минимум входной строки при сравнении символов на равенство (то есть возвращает символ, равный наименьшему числу других символов).
C 94 байта
Вернуться по указателю. Если нет, верните .
Это приведет к утечке памяти. Предполагается, intчто 4 байта.
*t;f(c,p,i)char*c,*p;{t=calloc(64,8);for(*p=-1;*c;c++)t[*c]--;for(i=0;++i<128;)!~t[i]?*p=i:0;}Попробуйте онлайн!
Mathematica, 27 байт
Last@*Keys@*CharacterCounts
Попробуйте онлайн!
-1 байт от Мартина Эндера
Баш , 15 20 байт
fold -1|sort|uniq -uПопробуйте онлайн!
Объяснение: fold s вводит 1символ в каждой строке, sortразбивает его на группы совпадающих букв, затем печатает только те строки, которые совпадают uniq.
Спасибо @Nahuel Fouilleul за то, что он поймал и помог решить проблему с этим подходом.
Matlab, 25 байт
a=input('');a(a~=mode(a))
Вход «а», где «а» не является режимом «а». Выводит пустой массив для отсутствия чудака.
Haskell, 33 * 0,75 = 24,75 байт
f s=[c|[c]<-(`filter`s).(==)<$>s]
Возвращает пустой список, если нет нечетного символа.
Попробуйте онлайн!
Для каждого символа cв матрице (заданной в виде строки s) создайте строку всех символов в ней s, равную cдлине 1.
JavaScript (ES6), 37 байт
Возвращает, nullесли нет нечетной буквы.
s=>s.match(`[^
${s.match(/(.)1/)}]`)Контрольные примеры
Japt , 6 байт
Принимает ввод как многострочную строку и выводит односимвольную строку или пустую строку, если нет решения.
k@èX É
Попробуй
объяснение
Удалите символы, которые возвращают truey ( k) при прохождении через функцию ( @), которая считает ( è) вхождения текущего элемента ( X) во входных данных и вычитает 1 ( É).
Common Lisp, 47 байт
(lambda(s)(find-if(lambda(x)(=(count x s)1))s))
Попробуйте онлайн!
Возвращает нечетную букву или NIL, если она не существует.
Желе , 4 байта
ċ@ÐṂ
Попробуйте онлайн!
Возврат n(одна новая строка), если нет нечетного символа. очевидноn это не печатный символ.
По совпадению это тот же алгоритм, что и в ответе Mr.Xcoder Python. (Я придумал это самостоятельно)
Объяснение:
ÐṂ Ṃinimum value by...
ċ@ ċount. (the `@` switch the left and right arguments of `ċ`)
Это работает, потому что в m×nматрице:
- Если существует нечетный символ: есть
m-1новые строки, 1 нечетные символы иm×n-1нормальный символ, и1 < m-1 < m×n-1потому5 ≤ m, n ≤ 10. - Если не существует нечетного символа: есть
m-1новые строки иm×nнормальный символ, иm-1 < m×n.
C (gcc) , 91 86 82 79 71 байт
f(char*s){for(;*++s==10?s+=2:0,*s;)if(*s^s[-1])return*s^s[1]?*s:s[-1];}Попробуйте онлайн!
- Спасибо Гастропнеру за XOR и? трюки (-3 байта)
- Переработана версия сравнения для исправления ошибок и использование магии Gastropner из комментариев.
Объяснение:
Сравните текущий и предыдущий символ, пропуская новые строки. Если отличается, сравните со следующим символом. Это говорит нам, если мы вернемся текущий или предыдущий символ. Функция возвращает «нечетное» значение char, если оно существует, или 0, если массив не является нечетным. Мы получаем «следующую» проверку символов, потому что перед символом всегда стоит новая строка. Если нет нечетного символа, мы возвращаем 0 из цикла for.
Более старый, более сексуальный код xor Объяснение:
Создайте бегущую маску xor из следующих 3 строковых значений. Если они все одинаковы, то значение будет равно любому из трех. Если они различаются, то 2 идентичных будут взаимно уничтожать друг друга, оставляя уникальное.
Должен множитель / n перед xor, иначе он станет грязным. Также нужно проверить 2 символа на неравенство в случае, если s [0] нечетное значение. Это стоит дополнительных || чек об оплате.
v;f(char*s){while(s[3]){s[2]==10?s+=3:0;v=*s^s[1]^s[2];if(v^*s++||v^*s)break;}}Октава , 26 25 байт
1 байт сохранен благодаря @Giuseppe
@(x)x(sum(x(:)==x(:)')<2)Анонимная функция, которая принимает двумерный массив символов в качестве входных данных и выводит либо нечетную букву, либо пустую строку, если она не существует.
Попробуйте онлайн!
Алиса , 16 * 75% = 12 байт
/-.nDo&
i..*N@/
Попробуйте онлайн!
Выводится, Jabberwockyесли нет повторяющегося символа.
объяснение
/...@
.../
Это основа для линейных программ, которые работают полностью в Ordinal (режим обработки строк). Фактический код выполняется зигзагообразно и раскрывается в:
i..DN&-o
i Read all input.
.. Make two copies.
D Deduplicate one copy, giving only the two letters and a linefeed.
N Multiset difference. Removes one copy of each letter and one linefeed.
Therefore it drops the unique letter.
&- Fold substring removal over this new string. This essentially removes
all copies of the repeated letter and all linefeeds from the input,
leaving only the unique letter.
. Duplicate.
n Logical NOT. Turns empty strings into "Jabberwocky" and everything else
into an empty string.
* Concatenate to the previous result.
o Print the unique letter or "Jabberwocky".
Вместо этого &-мы могли бы также использовать ey(транслитерацию в пустую строку). В качестве альтернативы, потратив еще один символ на манипуляции со стеком, мы также можем дедуплицировать ввод, который позволяет нам удалять ненужные символы N, но это все равно с тем же количеством байтов:
i.D.QXN.n*o@
Алиса , 13 байт
/N.-D@
i&.o/
Попробуйте онлайн!
Это решение без бонуса, просто отсутствует .n*.
APL + WIN, 16 байт
(1=+/a∘.=a)/a←,⎕
Запрашивает ввод с экрана и либо выводит нечетную букву, либо ничего, если нет нечетной буквы
PowerShell , 39 байт
([char[]]"$args"|group|sort c*)[0].NameПопробуйте онлайн!
Принимает ввод в виде строки с символами новой строки (как указано в вызове), преобразует его в char-array. Затем мы Group-Objectиспользуем символы, так что символы группируются по их именам, а затем sortна основе cколичества. Это гарантирует, что одинокий символ будет первым, поэтому мы берем [0]индекс и выводим его .Name.
Если новая строка приемлема для «ничего», то это соответствует бонусу.
Perl 6 , 27 24 -25% = 18 байт
*.comb.Bag.min(*.value).keyПопробуй это
{%(.comb.Bag.invert){1}}Попробуй это
Это будет вернет неопределенное значение если дан ввод, у которого нет нечетного символа.
Expanded:
{ # bare block lambda with implicit parameter 「$_」
%( # coerce into a Hash
.comb # split the input into graphemes (implicit method call on 「$_」)
.Bag # turn into a weighted Set
.invert # invert that (swap keys for values) returns a sequence
){ 1 } # get the character that only occurs once
}Brainfuck, 125 байт
,[----------[>],]<[->+<]<<[[->->+<<]>[>[->-<<<+>>]>[,<<,>>]<<<[->+<]>[->+<]<]>[-<<+>>]>[-<+>]<<<<]>>>>[<]<++++++++++.
Попробуйте онлайн
Печатает букву матрицы, если нет нечетного
Java 8, 85 байт
Это лямбда от Stringдо String(например Function<String, String>). По сути, это копия решения Луки , но я немного сократил сортировку строк.
s->new String(s.chars().sorted().toArray(),0,s.length()).replaceAll("(.)\1+|\n","")Попробуйте онлайн