Алгоритм поиска самой длинной подстроки-палиндрома
Время на прочтение
5 мин
Количество просмотров 14K
Один из самых прекрасных алгоритмов в информатике, который показывает, как можно получить большое ускорение от «вялого» O(n3) до молниеносного1 O(n), просто посмотрев на проблему с другой точки зрения.
Задача состоит в том, чтобы найти самую длинную подстроку, которая является палиндромом (читается одинаково слева направо и справа налево, например, «racecar»). Так, самый длинный палиндром в строке «Fractions are never odd or even» это «never odd or even» (регистр букв и пробелы игнорируются). Это также имеет практическое применение в биохимии (ГААТТЦ или ЦТТААГ являются палиндромными последовательностями2). К тому же, эту задачу3 часто дают на собеседовании.
Самый простой и прямой подход (при этом самый медленный) — перебирать с начала все подстроки всех длин и проверять, является ли текущая палиндромом:

Псевдокод такого решения
ЦИКЛ по символам всей строки:
ЦИКЛ по всем длинам, начиная с текущего символа:
ЦИКЛ по символам в этой подстроке:явно указывает, что метод со сложностью O(n3) (где n — это длина начальной строки) является быстровозрастающей функцией.
Если бы вместо перебора с самых начал подстрок, мы начинали перебор с середины, это позволило бы нам использовать результаты, которые мы получили на предыдущих шагах.

Например, если мы знаем, что «eve» — это палиндром, то нам потребуется всего одно сравнение, чтобы выяснить, что «level» тоже палиндром. В первом решении нам бы пришлось проверять все полностью с самого начала.
ЦИКЛ по символам строки до середины:
ЦИКЛ по всем длинам, начиная с текущего символа:В таком случае сложность составляет O(n2). Но существуют методы4, позволяющие сделать это еще быстрее.
Один из самых изящных — это алгоритм Манакера5. Он основан на методе, описанном выше, но его временная сложность сокращена до O(n).
Когда палиндромы в строке находятся далеко, оптимизировать нечего. Сложность и так O(n). Проблема появляется, когда они пересекаются, а худшим случаем является строка, состоящая из одной буквы.
Рассмотрим следующую ситуацию. Алгоритм нашел самый короткий зеленый палиндром, самый длинный голубой палиндром и остановился на букве «i»:

Внимательно посмотрев на картинку, можно заметить, что у нас нет необходимости обрабатывать правую часть голубого палиндрома. По определению, это зеркальное отражение левой части, так что полученную левую часть мы можем отразить на правую и получить ее, так сказать, «за бесплатно».

Однако, это не единственный случай перекрытия. На следующей картинке зеленый палиндром пересекает границу голубого, поэтому его длина должна быть уменьшена.

Опять-таки нет нужды дважды проверять длину отраженного палиндрома: буквы b и x обязаны быть различными, иначе голубой палиндром был бы длиннее.
Наконец, один палиндром может «касаться» другого изнутри. В этом случае нет гарантий, что отраженный палиндром не имеет бОльшую длину, так как мы получаем нижнюю границу его длины:

В идеале мы должны пропускать как нулевые, так и строго ненулевые значения (= все случаи, кроме последнего) в дальнейшей обработке (код 1 ниже). Но в практике (если вообще можно говорить о практике в такой абстрактной задаче) разница между ≥ и = довольно мала (всего одно дополнительное сравнение), поэтому имеет смысл рассматривать все ненулевые значения с помощью ≥ для краткости и читаемости кода (код 2 ниже).
Одна из возможных реализаций алгоритма на питоне:
#код 1
def odd(s):
n = len(s)
h = [0] * n
C = R = 0 # центр и радиус или крайний правый палиндром
besti, bestj = 0, 0 # центр и радиус самого длинного палиндрома
for i in range(n):
if i < C + R: # если есть пересечение
j = h[C-(i-C)] # отражение
if j < C + R - i: # случай A
h[i] = j
continue
elif j > C + R - i: # случай B
h[i] = C + R - i
continue
else: # case C
pass
else: # если нет пересечения
j = 0
while i-j > 0 and i+j<n-1 and s[i-j-1] == s[i+j+1]:
j += 1
h[i] = j
if j > bestj:
besti, bestj = i, j
if i + j > C + R:
C, R = i, j
return s[besti-bestj : besti+bestj+1]Сперва алгоритм пытается найти соответствующее отражение, как описано выше. Затем, если необходимо, последовательно ищет: как в алгоритме со сложностью O(n2), но принимая отраженное значения за начальную точку. В конце если новый палиндром перекрывает больше текста справа, чем предыдущий, то он становится новым крайним правым палиндромом.
Эта функция ищет палиндромы только нечетного размера. Общий подход для работы с палиндромами четного размера таков:
-
вставлять произвольный символ между символами в оригинальной строке, к примеру
‘noon’ -> ‘|n|o|o|n|’, -
находить палиндром нечетного размера,
-
удалять произвольные символы из результата.
Символ «|» необязательно должен отсутствовать в строке. Можно использовать любой символ.
def odd_or_even(s):
return odd('|'+'|'.join(s)+'|').replace('|', '')
>>> odd_or_even('afternoon')
'noon'Немного запутанная версия (труднее для понимания, немного медленнее, но короче) выглядит так:
#код 2
import re
def odd(s):
n = len(s)
h = [0] * n
C = R = 0 # центр и радиус или крайний правый палиндром
besti, bestj = 0, 0 # центр и радиус самого длинного палиндрома
for i in range(n):
j = 0 if i > C+R else min(h[C-(i-C)], C+R-i)
while i-j > 0 and i+j<n-1 and s[i-j-1] == s[i+j+1]:
j += 1
h[i] = j
if j > bestj:
besti, bestj = i, j
if i + j > C + R:
C, R = i, j
return s[besti-bestj : besti+bestj+1]
def manacher(s):
clean = re.sub('W', '', s.lower())
return odd('|'+'|'.join(clean)+'|')[1::2]
>>> manacher('He said: "Madam, I'm Adam!"')
'madamimadam'Как видно, в коде есть два вложенных цикла. Тем не менее, интуитивно понятно, почему сложность O(n). На диаграмме показан массив h.

Внешний цикл соответствует горизонтальному перемещению, внутренний — вертикальному. Каждый шаг — это одно сравнение. Сплошные линии — расчет шагов, пунктирные — пропуск шагов.
Очевидно из диаграммы, что, когда палиндромы не пересекаются, число шагов «вверх» равно количеству горизонтальных «пропускающих» шагов. Для пересекающихся палиндромов чуть более заморочено, но если посчитать число шагов «вверх» и число горизонтальных «пропускающих шагов, то эти числа вновь совпадут. Так что общее число шагов ограничено 2n сравнениями. Не просто n , потому что, в отличие от вертикальных шагов, чтобы понять, пропускать ли горизонтальный шаг или нет, необходимо проделать некую работу (хотя можно изменить реализацию, чтобы пропускать их за постоянное время). Итого временная сложность — O(n).
Алгоритм Манакера позволяет найти самый длинный палиндром в строке (если быть точнее, не просто самый длинный палиндром, а самый длинный палиндром для всех возможных центров) за линейное время, используя очень интуитивный подход, лучше всего описываемый визуально.
Ссылки:
-
Сайт Big-O Cheat Sheet.
-
Статья на Википедии про палиндромные последовательности.
-
Задача на Leetcode про самый длинный палиндром в строке.
-
Статья на Википедии про самый длинный палиндром в строке.
-
Гленн Манакер (1975), «Новый линейный алгоритм для поиска самого длинного палиндрома строки», журнал ACM.
Классическая задача. Найдите в данной вам строке максимальную по длине подстроку, которая является палиндромом (то есть читается слева направо и справа налево одинаково). Предложите как можно более эффективный алгоритм.
Решение за О(n²) и О(1) памяти: перебор
Очевидное квадратичное решение приходит в голову практически сразу. У каждого палиндрома есть центр: символ (или пустое место между двумя соседними символами в случае палиндрома четной длины), строка от которого читается влево и вправо одинаково. Например, для палиндрома abacaba таким центром является буква c, а для палиндрома colloc — пространство между двумя буквами l. Очевидно, что центром нашей искомой длиннейшей палиндромной подстроки является один из символов строки (или пространство между двумя соседними символами), в которой мы производим поиск.
Теперь мы можем реализовать такое решение: давайте переберем все символы строки, для каждого предполагая, что он является центром искомой самой длинной палиндромной подстроки. То есть предположим, что на данный момент мы стоим в i-ом символе строки. Теперь заведем две переменных left и right, изначально left = i - 1 и right = i + 1 для палиндромов нечетной длины и i - 1, i соответственно для палиндромов четной длины. Теперь будем проверять, равны ли символы в позициях строки left и right. Если это так, то уменьшим left на 1, а right увеличим на 1. Будем продолжать этот процесс до тех пор, пока символы в соответствующих позициях станут не равны, или же мы не выйдем за границы массива. Это будет означать, что мы нашли самый длинный палиндром в центре с i-ым символов в случае для палиндрома нечетной длины и в пространстве между i-ым и i - 1-ым символом в случае палиндрома четной длины. Выполним такой алгоритм для всех символов строки, попутно запоминая найденный максимум, и таким образом мы найдем самую длинную палиндромную подстроку всей строки.
Докажем, что это решение работает за O(n²). Рассмотрим строку ааааааааааааааа… Для каждого ее символа мы будем двигать left и right, пока не выйдем за границы массива. То есть для первого символа мы сделаем 0*2 (умножение на 2 происходит, потому что мы выполняем алгоритм два раза — для палиндромов нечетной и четной длины) итераций, для второго 1*2, для третьей 2*2, и т.д. до центра, потом кол-во итераций станет уменьшаться. Это арифметическая прогрессия с разностью 2. Рассмотрим сумму этой арифметической прогрессии до середины строки. Как известно, сумма арифметической прогрессии имеет формулу (A1+An)/2*n. В нашем случае A1 = 0, An = n/2*2 = n. (0+n)/2*n = n/2*n = O(n²). Для убывающей части все аналогично, там тоже получится O(n²). O(n²)+O(n²) = O(n²), ч.т.д.
Решение за О(n log n) по времени и О(n) памяти: полиномиальный хэш + бинпоиск
Это решение является ускоренной модификацией предыдущего. Можно посчитать для строки полиномиальный хеш, замечательным свойством которого является то, что мы можем за О(1) получить хеш любой подстроки, а значит, посчитав его для оригинальной и перевернутой строки мы можем за О(1) проверить, является подстрока [l..r] палиндромом (реализацию можно найти здесь). Следующее замечание состоит в том, что для каждого центра при переборе подстрока на некотором количестве итераций сначала будет являться палиндромом, а затем всегда нет. А это значит, что мы можем воспользоваться бинпоиском: переберем все символы, для каждого бинпоиском найдем максимальную палиндромную подстроку с центром в нем, по ходу дела будем запоминать найденный максимум.
Очевидно, что это решение работает за О(n log n) по времени. Мы перебираем все n символов, для каждого совершаем O(log n) итераций бинпоиска, на каждой из который проверяем, является ли подстрока палиндромом. В итоге: O(n log n) по времени и О(n) по памяти (потому что нам наобходимо хранить посчитанные хеши).
Решение за О(n) времени и O(n) памяти: алгоритм Манакера
Несправедлимым будет не упомянуть в этой статье алгоритм Манакера, решающий поставленную задачу за линейное время и линейную память.
| Задача: |
| Пусть дана строка . Требуется найти количество подстрок , являющиеся палиндромами. Более формально, все такие пары , что — палиндром. |
Содержание
- 1 Уточнение постановки
- 2 Наивный алгоритм
- 2.1 Идея
- 2.2 Псевдокод
- 2.3 Время работы
- 2.4 Избавление от коллизий
- 3 Алгоритм Манакера
- 3.1 Идея
- 3.2 Псевдокод
- 3.3 Оценка сложности
- 4 См. также
- 5 Источники информации
Уточнение постановки
Легко увидеть, что таких подстрок в худшем случае будет . Значит, нужно найти компактный способ хранения информации о них. Пусть — количество палиндромов нечётной длины с центром в позиции , а — аналогичная величина для палиндромов чётной длины. Далее научимся вычислять значения этих массивов.
Наивный алгоритм
Идея
Рассмотрим сначала задачу поиска палиндромов нечётной длины. Центром строки нечётной длины назовём символ под индексом . Для каждой позиции в строке найдем длину наибольшего палиндрома с центром в этой позиции. Очевидно, что если строка является палиндромом, то строка полученная вычеркиванием первого и последнего символа из также является палиндромом, поэтому длину палиндрома можно искать бинарным поиском. Проверить совпадение левой и правой половины можно выполнить за , используя метод хеширования.
Для палиндромов чётной длины алгоритм такой же. Центр строки чётной длины — некий мнимый элемент между и . Только требуется проверять вторую строку со сдвигом на единицу. Следует заметить, что мы не посчитаем никакой палиндром дважды из-за четности-нечетности длин палиндромов.
Псевдокод
int binarySearch(s : string, center, shift : int):
//shift = 0 при поиске палиндрома нечётной длины, иначе shift = 1
int l = -1, r = min(center, s.length - center + shift), m = 0
while r - l != 1
m = l + (r - l) / 2
//reversed_hash возвращает хэш развернутой строки s
if hash(s[center - m..center]) == reversed_hash(s[center + shift..center + shift + m])
l = m
else
r = m
return r
int palindromesCount(s : string):
int ans = 0
for i = 0 to s.length
ans += binarySearch(s, i, 0) + binarySearch(s, i, 1)
return ans
Время работы
Изначальный подсчет хешей производится за . Каждая итерация будет выполняться за , всего итераций — . Итоговое время работы алгоритма .
Избавление от коллизий
У хешей есть один недостаток — коллизии: можно подобрать входные данные так, что хеши разных строк будут совпадать. Абсолютно точно проверить две подстроки на совпадение можно с помощью суффиксного массива, но с дополнительной памятью . Для этого построим суффиксный массив для строки , при этом сохраним промежуточные результаты классов эквивалентности . Пусть нам требуется проверить на совпадение подстроки и . Разобьем каждую нашу строку на две пересекающиеся подстроки длиной , где . Тогда наши строки совпадают, если и .
Итоговая асимптотика алгоритма: предподсчет за построение суффиксного массива и на запрос, если предподсчитать все , то .
Алгоритм Манакера
Идея
Алгоритм, который будет описан далее, отличается от наивного тем, что использует значения, посчитанные ранее.
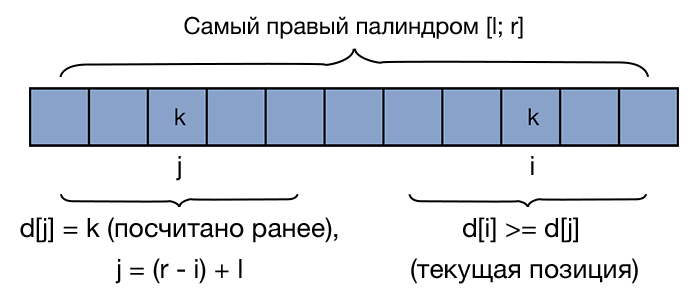
Будем поддерживать границы самого правого из найденных палиндромов — . Итак, пусть мы хотим вычислить — т.е. длину наибольшего палиндрома с центром в позиции . При этом все предыдущие значения в массиве уже посчитаны. Возможны два случая:
- , т.е. текущая позиция не попадает в границы самого правого из найденных палиндромов. Тогда просто запустим наивный алгоритм для позиции .
- . Тогда попробуем воспользоваться значениями, посчитанным ранее. Отразим нашу текущую позицию внутри палиндрома . Поскольку и — симметричные позиции, то если , мы можем утверждать, что и . Это объясняется тем, что палиндром симметричен относительно своей центральной позиции. Т.е. если имеем некоторый палиндром длины с центром в позиции , то в позиции , симметричной относительно отрезка тоже может находиться палиндром длины . Это можно лучше понять, посмотрев на рисунок. Снизу фигурными скобками обозначены равные подстроки. Однако стоит не забыть про один граничный случай: что если выходит за границы самого правого палиндрома? Так как информации о том, что происходит за границами этого палиндрома у нас нет (а значит мы не можем утверждать, что симметрия сохраняется), то необходимо ограничить значение следующим образом: . После этого запустим наивный алгоритм, который будет увеличивать значение , пока это возможно.
После каждого шага важно не забывать обновлять значения .
Заметим, что массив считается аналогичным образом, нужно лишь немного изменить индексы.
Псевдокод
Приведем код, который вычисляет значения массива :
// — исходная строка
int[] calculate1(string s):
int l = 0
int r = -1
for i = 1 to n
int k = 0
if i <= r
k = min(r - i, [r - i + l])
while i + k + 1 <= n and i - k - 1 > 0 and s[i + k + 1] == s[i - k - 1]
k++
[i] = k
if i + k > r
l = i - k
r = i + k
return
Вычисление значений массива :
// — исходная строка
int[] calculate2(string s):
int l = 0
int r = -1
for i = 1 to n
int k = 0
if i <= r
k = min(r - i + 1, [r - i + l + 1])
while i + k <= n and i - k - 1 > 0 and s[i + k] == s[i - k - 1]
k++
[i] = k
if i + k - 1 > r
l = i - k
r = i + k - 1
return
Оценка сложности
Внешний цикл в приведенном алгоритме выполняется ровно раз, где — длина строки. Попытаемся понять, сколько раз будет выполнен внутренний цикл, ответственный за наивный подсчет значений. Заметим, что каждая итерация вложенного цикла приводит к увеличению на . Действительно, возможны следующие случаи:
- , т.е. сразу будет запущен наивный алгоритм и каждая его итерация будет увеличивать значение хотя бы на .
- . Здесь опять два случая:
- , но тогда, очевидно, ни одной итерации вложенного цикла выполнено не будет.
- , тогда каждая итерация вложенного цикла приведет к увеличению хотя бы на .
Т.к. значение не может увеличиваться более раз, то описанный выше алгоритм работает за время .
См. также
- Префикс-функция
- Z-функция
- Суффиксный массив
- Поиск наибольшей общей подстроки двух строк с использованием хеширования
Источники информации
- MAXimal :: algo :: Нахождение всех подпалиндромов
- Википедия — Поиск длиннейшей подстроки-палиндрома
- Алгоритмы для поиска палиндромов — Хабр
- MAXimal :: algo :: Суффиксный массив
Напишите эффективный алгоритм построения самого длинного палиндрома путем перетасовки или удаления символов из заданной строки.
Например,
Input: ABBDAB
Output: The longest palindrome is BABAB (or BADAB or ABBBA or ABDBA)
Input: ABCDD
Output: The longest palindrome is DAD (or DBD or DCD)
Потренируйтесь в этой проблеме
Мы знаем, что левая и правая половины палиндрома содержат одинаковый набор символов в обратном порядке и, возможно, средний символ, который может быть любым. Идея состоит в том, чтобы найти все четные символы и построить левую половину палиндрома, используя половину их количества. Их порядок не имеет значения, так как допускается перетасовка. Тогда мы можем легко построить правую половину из левой половины, перевернув ее. Все нечетные встречающиеся символы игнорируются, кроме одного, который образует средний символ результирующей строки-палиндрома.
Ниже приведена реализация на C++, Java и Python, основанная на приведенной выше идее:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
#include <iostream> #include <unordered_map> using namespace std; // Построим самый длинный палиндром, перетасовав или удалив // символы из заданной строки string longestPalindrome(string str) { // создаем карту частот для символов заданной строки unordered_map<char, int> freq; for (char ch: str) { freq[ch]++; } string mid_char; // сохраняет нечетный символ string left; // сохраняет левую подстроку // итерация по частотной карте for (auto &p: freq) { char ch = p.first; // получить текущий символ int count = p.second; // получаем частоту символов // если частота текущего символа нечетная, // обновить mid до текущего char (и отбросить старый) if (count & 1) { mid_char = ch; } // добавляем половину символов в левую подстроку // (другая половина идет к правой подстроке в обратном порядке) left.append(count/2, ch); } // правая подстрока будет обратной левой подстроке string right(left.rbegin(), left.rend()); // возвращает строку, состоящую из левой подстроки, среднего символа (если есть), // и правая подстрока return (left + mid_char + right); } int main() { string str = «ABBDAB»; cout << «The longest palindrome is « << longestPalindrome(str); return 0; } |
Скачать Выполнить код
результат:
The longest palindrome is BABAB
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import java.util.HashMap; import java.util.Map; class Main { // Построим самый длинный палиндром, перетасовав или удалив // символы из заданной строки public static String longestPalindrome(String str) { // базовый вариант if (str == null || str.length() == 0) { return str; } // создаем карту частот для символов заданной строки Map<Character, Integer> freq = new HashMap<>(); for (char ch: str.toCharArray()) { freq.put(ch, freq.getOrDefault(ch, 0) + 1); } String mid_char = «»; // сохраняет нечетный символ StringBuilder left = new StringBuilder(); // сохраняет левую подстроку // итерация по частотной карте for (var entry: freq.entrySet()) { char ch = entry.getKey(); // получить текущий символ int count = entry.getValue(); // получаем частоту символов // если частота текущего символа нечетная, // обновить mid до текущего char (и отбросить старый) if (count % 2 == 1) { mid_char = String.valueOf(ch); } // добавляем половину символов в левую подстроку // (другая половина идет к правой подстроке в обратном порядке) left.append(String.valueOf(ch).repeat(count / 2)); } // правая подстрока будет обратной левой подстроке StringBuilder right = new StringBuilder(left).reverse(); // возвращает строку, состоящую из левой подстроки, среднего символа (если есть), // и правая подстрока return («» + left + mid_char + right); } public static void main(String[] args) { String str = «ABBDAB»; System.out.print(«The longest palindrome is « + longestPalindrome(str)); } } |
Скачать Выполнить код
результат:
The longest palindrome is ABDBA
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Построить самый длинный палиндром, перетасовав или удалив # символов из заданной строки def longestPalindrome(s): # Базовый вариант if not s: return » # создать словарь для символов заданной строки freq = {} for ch in s: freq[ch] = freq.get(ch, 0) + 1 left = » # сохраняет левую подстроку mid = » # перебирает словарь частот for ch, count in freq.items(): #, если частота текущего символа нечетная, # обновить средний до текущего (и отказаться от старого) if count % 2 == 1: mid = ch # хранит нечетный символ # добавляет половину символов в левую подстроку # (другая половина идет к правой подстроке в обратном порядке) for i in range(count // 2): left += ch # правая подстрока будет обратной левой подстроке right = left[::—1] # Возврат #, образованный левой подстрокой, средним символом (если есть), # и правая подстрока return left + mid + right if __name__ == ‘__main__’: s = ‘ABBDAB’ print(‘The longest palindrome is’, longestPalindrome(s)) |
Скачать Выполнить код
результат:
The longest palindrome is ABDBA
Временная сложность приведенного выше решения равна O(n) и требует O(n) дополнительное пространство, где n длина входной строки.
Спасибо за чтение.
Пожалуйста, используйте наш онлайн-компилятор размещать код в комментариях, используя C, C++, Java, Python, JavaScript, C#, PHP и многие другие популярные языки программирования.
Как мы? Порекомендуйте нас своим друзьям и помогите нам расти. Удачного кодирования 
This can be solved in O(n^2) using dynamic programming. Basically, the problem is about building the longest palindromic subsequence in x[i...j] using the longest subsequence for x[i+1...j], x[i,...j-1] and x[i+1,...,j-1] (if first and last letters are the same).
Firstly, the empty string and a single character string is trivially a palindrome.
Notice that for a substring x[i,...,j], if x[i]==x[j], we can say that the length of the longest palindrome is the longest palindrome over x[i+1,...,j-1]+2. If they don’t match, the longest palindrome is the maximum of that of x[i+1,...,j] and y[i,...,j-1].
This gives us the function:
longest(i,j)= j-i+1 if j-i<=0,
2+longest(i+1,j-1) if x[i]==x[j]
max(longest(i+1,j),longest(i,j-1)) otherwise
You can simply implement a memoized version of that function, or code a table of longest[i][j] bottom up.
This gives you only the length of the longest subsequence, not the actual subsequence itself. But it can easily be extended to do that as well.