Мода
и медиана –
особого рода средние, которые используются
для изучения структуры вариационного
ряда. Их иногда называют структурными
средними, в отличие от рассмотренных
ранее степенных средних.
Мода
– это величина признака (варианта),
которая чаще всего встречается в данной
совокупности, т.е. имеет наибольшую
частоту.
Мода
имеет большое практическое применение
и в ряде случаев только мода может дать
характеристику общественных явлений.
Медиана
– это варианта, которая находится в
середине упорядоченного вариационного
ряда.
Медиана
показывает количественную границу
значения варьирующего признака, которой
достигла половина единиц совокупности.
Применение медианы наряду со средней
или вместо нее целесообразно при наличии
в вариационном ряду открытых интервалов,
т.к. для вычисления медианы не требуется
условное установление границ отрытых
интервалов, и поэтому отсутствие сведений
о них не влияет на точность вычисления
медианы.
Медиану
применяют также тогда, когда показатели,
которые нужно использовать в качестве
весов, неизвестны. Медиану применяют
вместо средней арифметической при
статистических методах контроля качества
продукции. Сумма абсолютных отклонений
варианты от медианы меньше, чем от любого
другого числа.
Рассмотрим
расчет моды и медианы в дискретном
вариационном ряду:
|
Стаж, |
Число |
Накопленные |
|
1 |
2 |
2 |
|
3 |
4 |
6 |
|
4 |
5 |
(11) |
|
8 |
4 |
15 |
|
10 |
1 |
16 |
|
ИТОГО: |
16 |
— |
Определить моду и медиану.
Мода
Мо =
4 года, так как этому значению соответствует
наибольшая частота f
= 5.
Т.е.
наибольшее число рабочих имеют стаж 4
года.
Для
того, чтобы вычислить медиану, найдем
предварительно половину суммы частот.
Если сумма частот является числом
нечетным, то мы сначала прибавляем к
этой сумме единицу, а затем делим пополам:
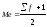
Ме=16/2=8
Медианой
будет восьмая по счету варианта.
Для
того, чтобы найти, какая варианта будет
восьмой по номеру, будем накапливать
частоты до тех пор, пока не получим сумму
частот, равную или превышающую половину
суммы всех частот. Соответствующая
варианта и будет медианой.
Ме
= 4 года.
Т.е.
половина рабочих имеет стаж меньше
четырех лет, половина больше.
Если
сумма накопленных частот против одной
варианты равна половине сумме частот,
то медиана определяется как средняя
арифметическая этой варианты и
последующей.
Вычисление
моды и медианы в интервальном вариационном
ряду
Мода
в интервальном вариационном ряду
вычисляется по формуле
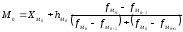
где ХМ0
— начальная
граница модального интервала,
hм0
– величина модального интервала,
fм0,
fм0-1,
fм0+1
– частота
соответственно модального интервала,
предшествующего модальному и последующего.
Модальным
называется такой интервал, которому
соответствует наибольшая частота.
Пример
1
|
Группы |
Число |
Накопленные |
|
1 |
2 |
3 |
|
До |
4 |
4 |
|
2-4 |
23 |
27 |
|
4-6 |
20 |
47 |
|
6-8 |
35 |
82 |
|
8-10 |
11 |
93 |
|
свыше |
7 |
100 |
|
ИТОГО: |
100 |
— |
Определить
моду и медиану.
Решение.
Модальный
интервал [6-8], т.к. ему соответствует
наибольшая частота f
= 35. Тогда:
Хм0=6,
fм0=35
hм0=2,
fм0-1=20
fм0+1=11

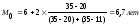
Вывод:
Наибольшее число рабочих имеет стаж
примерно 6,7 лет.
Для
интервального ряда Ме вычисляется по
следующей формуле:

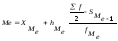
где Хме
–
нижняя граница медиального интервала,
hме
– величина медиального интервала,
![]() –
–
половина суммы частот,
fме
– частота медианного интервала,
Sме-1
–сумма
накопленных частот интервала,
предшествующего медианному.
Медианный
интервал – такой интервал, которому
соответствует кумулятивная частота,
равная или превышающая половину суммы
частот.
Определим
медиану для нашего примера.
Найдем:
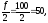
т.к
82>50, то медианный интервал [6-8].
Тогда:
Хме
=6, fме
=35,
hме
=2, Sме-1=47,
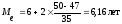
Вывод: Половина рабочих имеет стаж
меньше 6,16 лет, а половина имеет стаж
больше, чем 6,16 лет.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
8.4. МОДА и МЕДИАНА (структурные средние)
Мода и медиана наиболее часто используемые в экономической практике структурные средние.
Мода – это величина признака (варианта), который наиболее часто встречается в данной совокупности, т.e. это варианта, имеющая наибольшую частоту.
В дискретном ряду мода определяется в соответствии с определением, т.е. это одна из вариант признака, которая в ряду распределения имеет наибольшую частоту.
Для интервального ряда моду находим по формуле (8.16), сначала по наибольшей частоте определив модальный интервал:

(8.16 – формула Моды)
где хо – начальная (нижняя) граница модального интервала;
h – величина интервала;
fМо – частота модального интервала;
fМо-1 – частота интервала, предшествующая модальному;
fМо+1– частота интервала следующая за модальным.
Медианой называется такое значение признака, которое приходится на середину ранжированного ряда, т.е. в ранжированном ряду распределения одна половина ряда имеет значение признака больше медианы, другая – меньше медианы.
В дискретном ряду медиана находится непосредственно по накопленной частоте, соответствующей номеру медианы.
В случае интервального вариационного ряда медиану определяют по формуле:
 (8.17 – формула Медианы)
(8.17 – формула Медианы)
где хо – нижняя граница медианного интервала;
NМе– порядковый номер медианы (Σf/2);
S Me-1 – накопленная частота до медианного интервала;
fМе – частота медианного интервала.
Пример вычисления Моды.
Рассчитаем моду и медиану по данным табл. 8.4.
Таблица 8.4 – Распределение семей города N по размеру среднедушевого дохода в январе 2018 г. руб.(цифры условные)
| Группы семей по размеру дохода, руб. | Число
семей |
Накоп-
ленные частоты |
в % к итогу |
| До 5000 | 600 | 600 | 6 |
| 5000-6000 | 700 | 1300
(600+700) |
13 |
| 6000-7000 | 1700 (fМо-1) | 3000 (S Me-1 )
(1300+1700) |
30 |
| 7000-8000
(хо) |
2500
(fМо) (fМе) |
5500 (S Me) | 55 |
| 8000-9000 | 2200 (fМо+1) | 7700 | 77 |
| 9000-10000 | 1500 | 9200 | 92 |
| Свыше 10000 | 800 | 10000 | 100 |
| Итого | 10000 | – | – |
Пример вычисления Моды. Найдем моду по формуле (8.16) см. обозначения в таблице, а h = 8000-7000=1000, т.е. получаем:

Пример вычисления Моды
Пример вычисления Медианы интервального вариационного ряда. Рассчитаем медиану по формуле (8.17):
1) сначала находим порядковый номер медианы: NМе = Σfi/2= 5000.
2) по накопленным частотам в соответствии с номером медианы определяем, что 5000 находится в интервале (7000 – 8000), далее значение медианы определим по формуле (8.17):

Пример вычисления Медианы
Вывод: по моде – наиболее часто встречается среднедушевой доход в размере 7730 руб., по медиане – что половина семей города имеет среднедушевой доход ниже 7800 руб., остальные семьи – более 7800 руб.
Пример .СРЕДНИЙ, МЕДИАННЫЙ И МОДАЛЬНЫЙ УРОВЕНЬ ДЕНЕЖНЫХ ДОХОДОВ НАСЕЛЕНИЯ ЦЕЛОМ ПО РОССИИ И ПО СУБЪЕКТАМ РОССИЙСКОЙ ФЕДЕРАЦИИ ЗА 2013 год см. по ссылке. Источник: оценка на основании данных выборочного обследования бюджетов домашних хозяйств и макроэкономического показателя денежных доходов населения
Соотношение моды, медианы и средней арифметической указывает на характер распределения признака в совокупности, позволяет оценить его асимметрию.
Если Мо<Ме<Х – имеет место правосторонняя асимметрия.
При Х<Ме<Мо следует сделать вывод о левосторонней асимметрии ряда.
Средние величины (арифметическая, гармоническая, геометрическая, квадратическая) см. по ссылке
Оценка статьи:
![]() Загрузка…
Загрузка…
8.2. Медиана, квартили, децили
Медиана — это значение признака, которое делит статистическую совокупность на две равные части: половина единиц совокупности имеет значения признака не меньше медианы, другая половина — значения признака не больше медианы.
Значения изучаемого признака всех единиц статистической совокупности можно расположить в порядке возрастания (или убывания). В этом случае мы получим ранжированный ряд. Если число единиц совокупности нечетное, то значение признака, находящееся в середине ранжированного ряда, будет являться медианой. Если число единиц совокупности четное, то медианой будет средняя величина из двух значений признака, находящихся в середине ряда.
Пример 8.5. Имеются следующие данные о результатах сдачи экзамена по статистике в студенческой группе:
| Номер студента | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Оценка по статистике | 3 | 4 | 2 | 3 | 4 | 4 | 4 | 3 | 4 | 5 | 5 |
Представим их в виде ранжированного ряда:
| Номер студента | 3 | 1 | 4 | 8 | 2 | 5 | 6 | 7 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Оценка по статистике | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 5 |
Как видим, в ранжированном ряду оценки расположились следующим образом: сначала записана одна неудовлетворительная оценка (ее получил студент, имеющий в ведомости номер 3), затем три оценки «удовлетворительно», пять оценок «хорошо» и две оценки «отлично». В середине ранжированного ряда, имеющего нечетное число членов, стоит оценка «4», которую получил студент, записанный в ведомости под номером 5. Следовательно, оценка «4 (хорошо)» является медианой для данного ряда распределения. Пять студентов получили оценки 4 и ниже (2, 3, 3, 3, 4), другие пять студентов — 4 и выше (4, 4, 4, 5, 5).
Пример 8.6. Имеются данные о цене антоновских яблок в шести магазинах города. Представим их сразу в виде ранжированного ряда:
| Название магазина | «Огонек» | «Маяк» | «Заря» | «Татьяна» | «Ночной» | «Любимый» |
|---|---|---|---|---|---|---|
| Цена яблок, руб. за кг | 40 | 41 | 42 | 44 | 44 | 45 |
В середине ранжированного ряда находятся цены двух магазинов, причем они разные. Медиана определяется как средняя величина из этих значений признака. Она равна 43 руб. [(42 + 44) : 2 = 43].
Таким образом, в 50% магазинов города яблоки продаются по цене не выше 43 руб. за килограмм, а в других 50% магазинов — по цене не ниже 43 руб.
Квартили (Q) делят ранжированный ряд на четыре равные части: первый квартиль (Q1) включает значения признака, не превышающие 25% единиц совокупности, второй квартиль (Q2) — совпадает с медианой (Ме), третий квартиль (Q3) — значения признака, не превышающие 75% единиц совокупности (рис. 8.3).
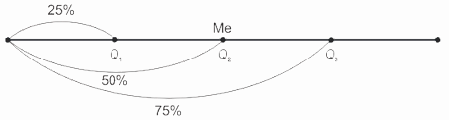
Рис.
8.3.
Деление ранжированного ряда на четыре равные части
Децили (D) делят ранжированный ряд на десять равных частей: первым децилем (D1) является значение признака, которое не превышает 10% единиц совокупности, вторым (D2) — 20%, третьим (D3) — 30% и т.д. При этом пятый дециль (D5) совпадает с медианой и вторым квартилем (Q2) (рис. 8.4).

Рис.
8.4.
Деление ранжированного ряда на десять равных частей
Медиана, квартили и децили относятся к группе квантилей. Квантили — это показатели, которые делят вариационные ряды на определенное количество равных частей. Среди них, помимо названных, также имеются квантили, которые делят ряд на пять равных частей, перцентили — на сто и т.д.
Структурные показатели не зависят от того, имеются ли в статистической совокупности аномальные (резко выделяющиеся) наблюдения. И если средняя величина при их наличии теряет свою практическую значимость, то информативность медианы наоборот усиливается — она начинает выполнять функции средней, т.д. характеризовать центр совокупности.
Способы расчета рассматриваемых структурных показателей зависят от вида вариационного ряда. Рассмотрим их подробнее.
8.2.1. Определение структурных средних в дискретных вариационных рядах
Для определения медианы в дискретных вариационных рядах:
- находят ее порядковый номер по формуле

- строят ряд накопленных частот;
- находят накопленную частоту, которая равна порядковому номеру медианы или его превышает;
- варианта, соответствующая данной накопленной частоте, является медианой.
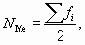
Пример 8.7. Определим медианный стаж сотрудников страховой компании на основе следующих данных:
| Время работы, лет, xi | Число сотрудников, чел., fi | Накопленная частота, Si |
|---|---|---|
| 1 | 5 | 5 |
| 2 | 7 | 12 |
| 3 | 4 | 16 |
| 4 | 9 | 25 |
| 5 | 13 | 38 |
| 6 | 10 | 48 |
| 7 | 16 | 64 |
| 8 | 13 | 77 |
| Итого | 77 | — |
Номер медианы равен
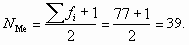
Для того чтобы найти значение варианты, стоящей на 39 месте, рассчитаем накопленные частоты. Для пятой группы накопленная частота равна 38. Это означает, что 38 работников имеют стаж работы 5 лет и меньше. Для шестой группы накопленная частота — 48 (она первая превышает порядковый номер медианы), следовательно, в эту группу входят сотрудники с порядковыми номерами от 39 до 48, в том числе и искомый 39-й сотрудник. Стаж работы сотрудников в шестой группе — 6 лет. Значит, Ме = 6. Итак, 50% сотрудников работают в данной страховой компании не более шести лет.
Квартили и децили определяют аналогично медиане: сначала находят их номер, затем среди накопленных частот ищут такую, которая первая равна или превышает порядковый номер показателя, ей соответствует варианта, которая является искомым показателем. Номера квартилей рассчитываются по формулам:
Порядковые номера децилей исчисляются следующим образом:
Определим квартили по данным примера 8.7. Их номера равны:
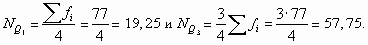
Первая накопленная частота, превышающая 19,25, равна 25. Ей соответствует варианта 4, являющаяся первым квартилем. Первая накопленная частота, которая превышает 57,75 — это 64; ей соответствует варианта, равная 7. Это третий квартиль. Итак, 25% сотрудников работают в данной компании не более четырех лет, а 75% — не более семи лет.
Аналогично определяются децили. Например, восьмой дециль вычисляется следующим образом:

Накопленная частота 64 — первая, превышающая ND8, ей соответствует значение признака — 7 лет, т.д. у 80% сотрудников стаж работы в данной компании не превышает семи лет.
8.2.2. Определение структурных средних в интервальном вариационном ряду
В интервальных рядах сначала определяют медианный интервал. Для этого так же, как и в дискретных рядах, рассчитывают порядковый номер медианы

Накопленной частоте, которая равна номеру медианы или первая его превышает, в интервальном вариационном ряду соответствует медианный интервал. Обозначим эту накопленную частоту SМе. Непосредственно расчет медианы проводят по формуле:

где хМе — нижняя граница медианного интервала;
dMe — величина медианного интервала;
SMe — 1 — накопленная частота интервала, предшествующего медианному;
fMe — частота медианного интервала.
Пример 8.8. По следующим данным определим медианное значение суммы выданных банками кредитов:
| Сумма выданных кредитов, млн ден. ед. | Количество банков, fi | Накопленная частота, Si. |
|---|---|---|
| 20-40 | 8 | 8 |
| 40-60 | 15 | 23 |
| 60-80 | 21 | 44 |
| 80-100 | 12 | 56 |
| 100-120 | 9 | 65 |
| 120-140 | 7 | 72 |
| 140-160 | 4 | 76 |
| Итого | 76 | — |
Проведем расчет:
- определим порядковый номер медианы
- определим накопленную частоту медианного интервала: SМе > NМе; SМе = 44;
- определим соответствующий ей медианный интервал «60-80»;
- рассчитаем значение медианы по формуле
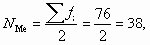

т.е. у 50% банков сумма выданных кредитов не превышает 74,286 млн ден. ед.
Далее произведем расчет квартилей и децилей в интервальном вариационном ряду.
Для приведенного интервального ряда необходимо определить:
- номер первого (нижнего) квартиля:
тогда ей соответствует интервал «40-60», в котором находится первый квартиль;
- номер третьего (верхнего) квартиля:
тогда ей соответствует интервал «100-120», в котором находится третий квартиль;
- первый (нижний) квартиль рассчитаем по формуле:
т.е. у 25% банков сумма выданных кредитов не превышает 54,7 млн ден. ед.;
- третий (верхний) квартиль рассчитаем по формуле:
т.е. у 75% банков сумма выданных кредитов не превышает 102,2 млн ден. ед.




Аналогично квартилям определяем децили. Формулы, используемые в ходе расчетов, поместим в таблицу.
|
|
|
Здесь хD — нижняя граница децильного интервала; dD — величина децильного интервала; SD — 1 — сумма накопленных частот интервала, предшествующего децильному; fD — частота децильного интервала. |
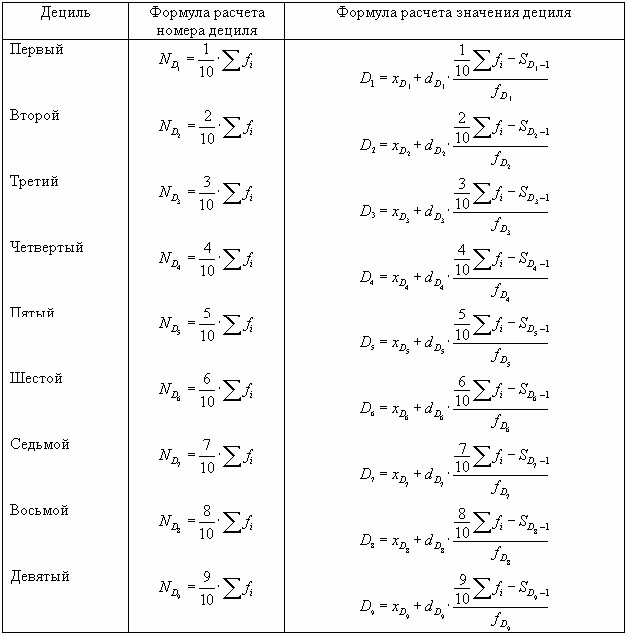
Номер шестого дециля равен: следовательно SQ6 = 56, этой накопленной частоте соответствует интервал «80-100», в котором находится шестой дециль. Величина децильного значения равна:
следовательно SQ6 = 56, этой накопленной частоте соответствует интервал «80-100», в котором находится шестой дециль. Величина децильного значения равна:  (млн ден. ед.), т.д. у 60% банков сумма выданных кредитов не превышает 82,7 млн ден. ед.
(млн ден. ед.), т.д. у 60% банков сумма выданных кредитов не превышает 82,7 млн ден. ед.
В статистике для характеристики степени неоднородности совокупности часто используют коэффициенты дифференциации (квартильные и децильные). Децильный коэффициент дифференциации представляет собой отношение девятого дециля к первому:

Данный коэффициент показывает, во сколько раз варианта, выше которой находятся 10% единиц совокупности, имеющих самые большие значения признака, больше варианты, ниже которой находятся 10% единиц совокупности с самыми маленькими значениями признака. Аналогично квартильный коэффициент дифференциации определяется как отношение третьего квартиля к первому.
В заключение отметим, что приблизительное равенство средней арифметической, моды и медианы, рассчитанных по отношению к одному и тому же ряду, говорит о том, что значения признака в изучаемой совокупности имеют нормальный закон распределения (или приближаются к нему).
Медиана может быть определена графически по кумуляте. Для этих целей на оси ординат, где отмечаются накопленные частоты, находится точка, соответствующая полусумме всех частот (т.е. порядковому номеру медианы). Из нее проводится прямая параллельно оси абсцисс до пересечения с графиком (кумулятой распределения). Абсцисса точки пересечения соответствует медиане данного ряда распределения.
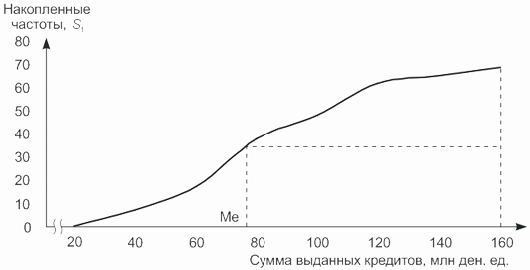
Рис.
8.5.
Определение медианы по кумуляте
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) — середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) — соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) — результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | — |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).