Для оценки статистической связи введено
понятие интервала корреляции. Суть
понятия в том, что значение случайного
процесса
и
![]()
можно считать статистически независимыми
при условии
![]()
.
Интервал корреляции
![]()
— числовая характеристика, которая
служит для оценки “скорости изменения”
реализации случайного процесса.
И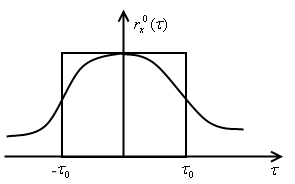
нтервал
корреляции определяется как половина
ширины прямоугольника единичной высоты,
площадь которого равна площади под
графиком коэффициента корреляции.
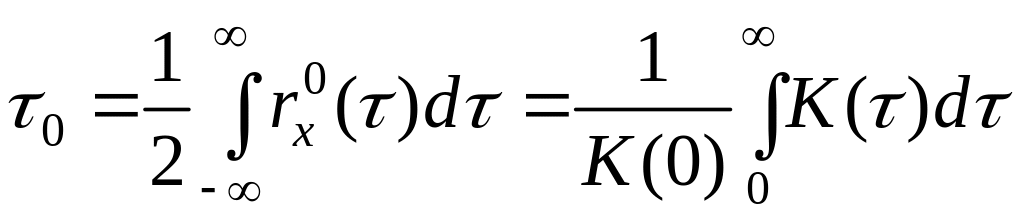
,
де
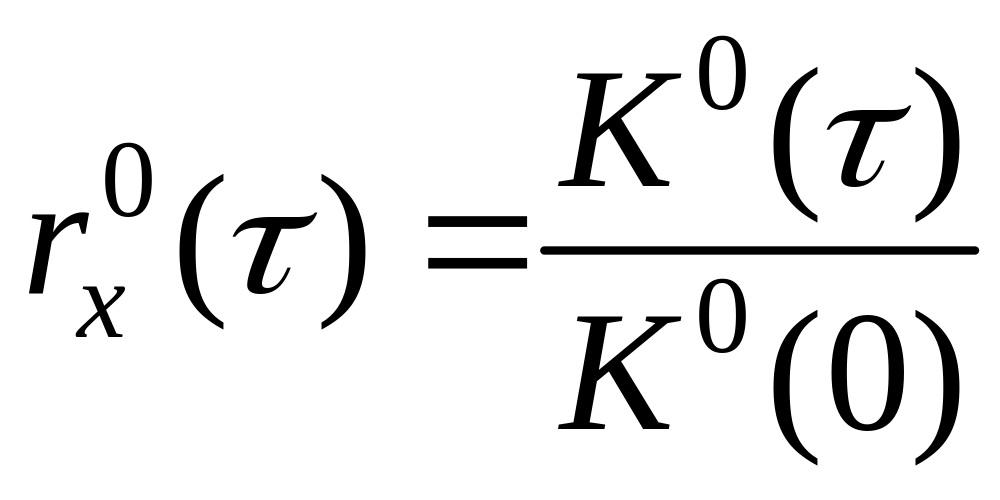
– нормированная корреляционная функция.
Интервал
корреляции также связан с эффективной
шириной спектра случайного процесса:
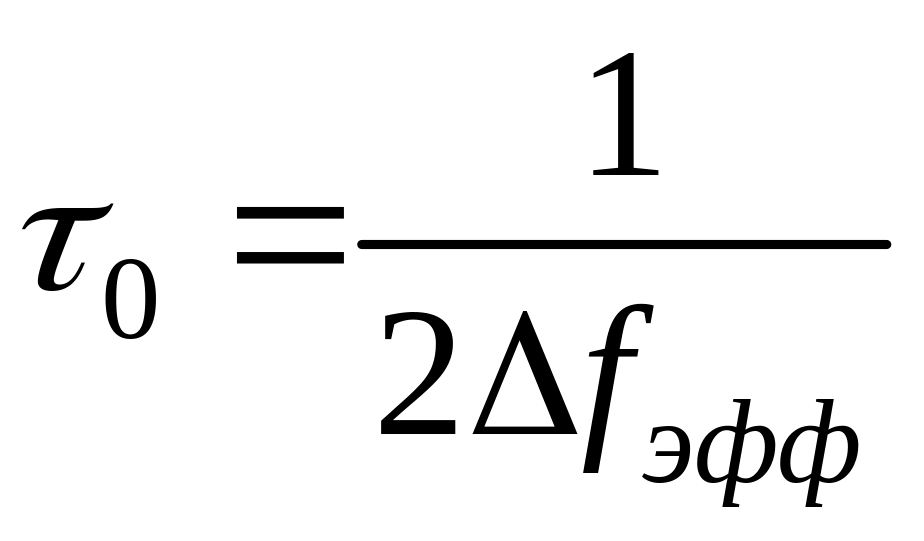
.
6.3 Обнаружение двукратных ошибок кодом Хэмминга
Код Хэмминга предназначен для обнаружения
и исправления однократной ошибки. При
построении кода каждый из k проверочных
символов определяется как результат
суммирования по модулю 2 определенного
сочетания информационных символов.
В результате этого сумма проверяемых
информационных и контрольного символа
всегда является четной. Количество
контрольных символов для исправления
1-кратной ошибки определяется по формуле:
,
где
-количество
символов в кодовой комбинации. Контрольные
символы располагаются на местах,
определяемых степенью двойки (1, 2, 4, 8,
16…)
В коде Хэмминга проверки на четность
организованы таким образом, что получается
число, указывающее номер позиции, на
которой произошло искажение.
При проверке на четность мы используем
номер позиции, соответствующей единице,
находящейся в том разряде, какую проверку
мы делаем, то есть если первая проверка,
то смотрим единицы по первому разряду.
Если число единиц на проверочных позициях
четное то контрольный символ равен 0,
а если число единиц на проверочных
позиция не четное, то контрольный символ
равен 1. Число проверок организовано
таким образом, что получается число,
указывающее на номер позиции, на которой
произошла однократная ошибка.
Для обнаружения двукратной ошибки
необходимо добавить 1 контрольный символ
к коду Хэмминга:
![]()
.
Дополнительная проверка включает в
себя все символы кодовой комбинации.
При декодировании сначала делают k
проверок в соответствии с формулами, а
потом осуществляют (k+1) проверку. При
этом, если некоторые проверки и (k+1)
проверка дают ненулевой результат, то
была однократная ошибка. Если же последняя
проверка даст нуль, то имеем дело с
двукратной ошибкой.
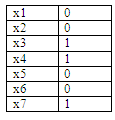
Например,
кодовая комбинация 1001 была закодирована
кодом Хэмминга. Для исправления 1-кратной
ошибки нужно использовать 3 контрольных
символа (позиции х1, х2, х4). После проверок
имеем код (табл). Чтобы
обнаружить двукратную ошибку, введем
дополнительный контрольный символ
х8=1, чтоб соблюдать четность. Например
произошла ошибка на позициях х4 (1→0) и
х7 (1→0). Делаем 4 проверки. В последней
проверки при суммировании всех членов
комбинации получили 0. Двукратная ошибка
обнаружена.
7.1 Статистический подход к измерению информации
Особенность статистического метода в
том, что он определяет энтропию как меру
неопределенности, с учетом вероятностей
появления элементов сообщения. Все
возможные сообщения составляют ансамбль
![]()
.
Вероятности не остаются постоянными,
поэтому можно говорить о статистических
характеристиках как о переменных
величинах (в большинстве случаев). Имеем
сообщение из n элементов и алфавита
m, где р1, р2…рm –
вероятности появления элементов, а сами
элементы алфавита обозначим как
![]()
.
Вероятность того, что в сообщение войдут
ni
элементов xi,
равняется
![]()
,
а вероятность образования сообщения
из n1
n2,
…, ni
…, nт соответствующих
элементов будет равна
![]()
При достаточно большом значении n
имеем
![]()
элементов хi, а
вероятность появления типичных сообщений
р может
быть найдена с учетом выражения
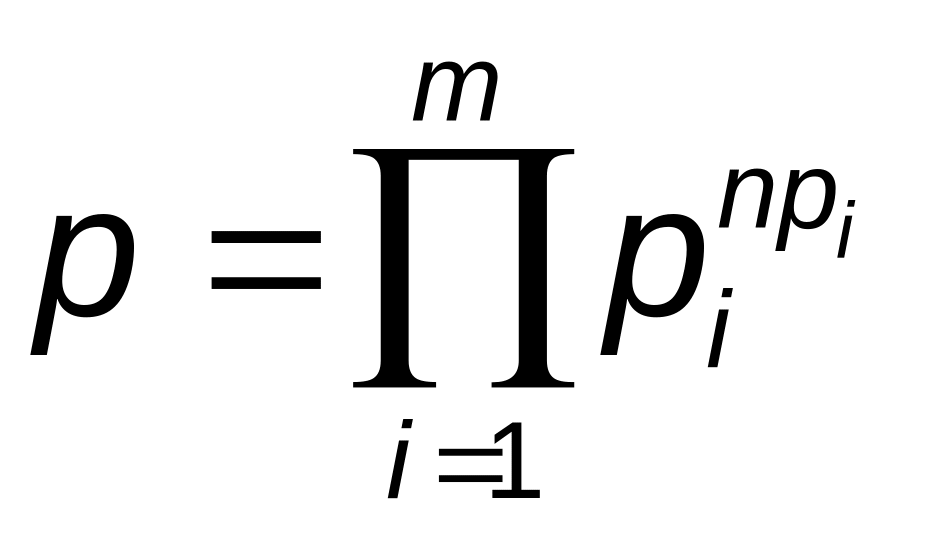
.
Количество информации в одном сообщении:
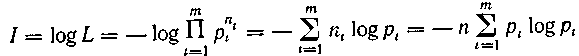
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
При спектральных преобразованиях случайных процессов важное значение приобретает ширина спектра процесса. Эффективная ширина энергетического спектра определяется следующим образом:
![]() , (5.73)
, (5.73)
или
![]() . (5.74)
. (5.74)
Этому определению можно дать графическую интерпретацию. На рис. 5.7 изображена кривая одностороннего энергетического спектра. Построим прямоугольник с площадью, равной площади по кривой ![]() , одна сторона которого составляет величину
, одна сторона которого составляет величину ![]() (в данном случае
(в данном случае ![]() ). Тогда вторая сторона прямоугольника будет характеризовать эффективную ширину энергетического
). Тогда вторая сторона прямоугольника будет характеризовать эффективную ширину энергетического 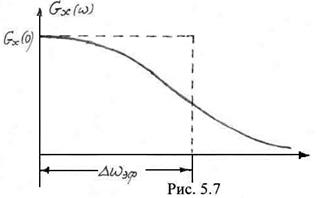 спектра
спектра ![]() . Представим выражение (5.71) в следующем виде
. Представим выражение (5.71) в следующем виде
![]() .
.
Левая сторона этого равенства представляет собой среднюю мощность случайного процесса с равномерным энергетическим спектром в пределах полосы частот ![]() , а правая – среднюю мощность рассматриваемого случайного процесса.
, а правая – среднюю мощность рассматриваемого случайного процесса.
Тогда эффективную ширину спектра рассматриваемого случайного процесса можно трактовать как ширину спектра процесса с равномерной плотностью мощности при равенстве средних мощностей обоих процессов.
Как подчеркивалось выше, автокорреляционная функция случайного процесса характеризует степень статистической связи между значениями процесса, разделенными интервалом времени ![]() . При этом, для эргодических процессов, которые изучаются в радиотехнике, АКФ стремится к нулю при неограниченном возрастании
. При этом, для эргодических процессов, которые изучаются в радиотехнике, АКФ стремится к нулю при неограниченном возрастании ![]() . Очевидно, при определенном значении
. Очевидно, при определенном значении ![]() , значения случайного процесса
, значения случайного процесса ![]() и
и ![]() можно считать статистически несвязанными (некоррелированными). Значение
можно считать статистически несвязанными (некоррелированными). Значение ![]() , при котором значения случайного процесса
, при котором значения случайного процесса ![]() и
и ![]() становятся статистически несвязанными, называется интервалом корреляции.
становятся статистически несвязанными, называется интервалом корреляции.
Интервал корреляции определяется в соответствии с выражением
![]() , (5.75)
, (5.75)
где ![]() – нормированная автокорреляционная функция.
– нормированная автокорреляционная функция.
Знак модуля в (5.75) введен для случая, когда ![]() может принимать отрицательные значения. На рис. 5.8 приведена графическая интерпретация понятия интервала корреляции. Интервал корреляции представляет собой сторону прямоугольника, по площади равному площади под кривой
может принимать отрицательные значения. На рис. 5.8 приведена графическая интерпретация понятия интервала корреляции. Интервал корреляции представляет собой сторону прямоугольника, по площади равному площади под кривой ![]() при
при ![]() .
.
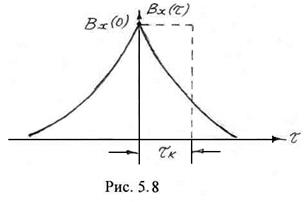 Установим связь между эффективной шириной спектра и интервалом корреляции в предположении, что
Установим связь между эффективной шириной спектра и интервалом корреляции в предположении, что ![]() , а функция корреляции представляет собой неотрицательную монотонно убывающую функцию, что позволяет в (5.75) полагать
, а функция корреляции представляет собой неотрицательную монотонно убывающую функцию, что позволяет в (5.75) полагать ![]() . Найдем произведение
. Найдем произведение ![]() и
и ![]() с учетом (5.73) и (5.75).
с учетом (5.73) и (5.75).
![]() .
.
Подставляя в это выражение формулы (5.67) и (5.68) после несложных преобразований получим
![]() . (5.76)
. (5.76)
Аналогично, используя выражения (5.71), (5.72), (5.74) и (5.75), можно получить
![]() . (5.77)
. (5.77)
Таким образом, произведение эффективной ширины спектра и интервала корреляции представляет собой постоянную величину. Из этого вытекает, что чем шире энергетический спектр, тем меньше интервал корреляции между его значениями и наоборот. Но ширина энергетического спектра определяет скорость изменения значений случайного процесса: чем больше ![]() (или чем меньше
(или чем меньше ![]() ), тем выше скорость изменения процесса.
), тем выше скорость изменения процесса.
Обнаружение взаимосвязей между явлениями – одна из главных задач статистического анализа. На то есть две причины. Первая. Если известно, что один процесс зависит от другого, то на первый можно оказывать влияние через второй. Вторая. Даже если причинно-следственная связь отсутствует, то по изменению одного показателя можно предсказать изменение другого.
Взаимосвязь двух переменных проявляется в совместной вариации: при изменении одного показателя имеет место тенденция изменения другого. Такая взаимосвязь называется корреляцией, а раздел статистики, который занимается взаимосвязями – корреляционный анализ.
Корреляция – это, простыми словами, взаимосвязанное изменение показателей. Она характеризуется направлением, формой и теснотой. Ниже представлены примеры корреляционной связи.
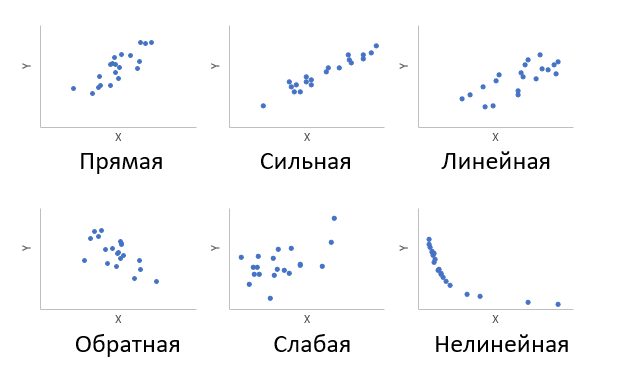
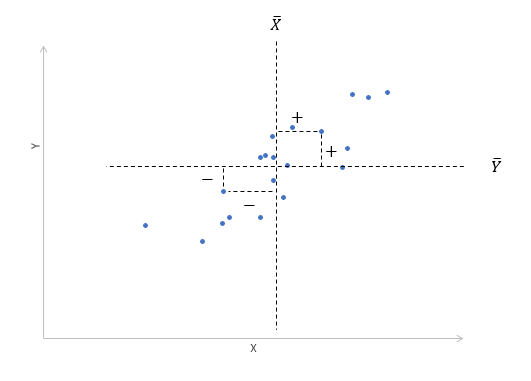
Далее будет рассматриваться только линейная корреляция. На диаграмме рассеяния (график корреляции) изображена взаимосвязь двух переменных X и Y. Пунктиром показаны средние.
При положительном отклонении X от своей средней, Y также в большинстве случаев отклоняется в положительную сторону от своей средней. Для X меньше среднего, Y, как правило, тоже ниже среднего. Это прямая или положительная корреляция. Бывает обратная или отрицательная корреляция, когда положительное отклонение от средней X ассоциируется с отрицательным отклонением от средней Y или наоборот.
Линейность корреляции проявляется в том, что точки расположены вдоль прямой линии. Положительный или отрицательный наклон такой линии определяется направлением взаимосвязи.
Крайне важная характеристика корреляции – теснота. Чем теснее взаимосвязь, тем ближе к прямой точки на диаграмме. Как же ее измерить?
Складывать отклонения каждого показателя от своей средней нет смысла, получим нуль. Похожая проблема встречалась при измерении вариации, а точнее дисперсии. Там эту проблему обходят через возведение каждого отклонения в квадрат.
![]()
Квадрат отклонения от средней измеряет вариацию показателя как бы относительно самого себя. Если второй множитель в числителе заменить на отклонение от средней второго показателя, то получится совместная вариация двух переменных, которая называется ковариацией.
![]()
Чем больше пар имеют одинаковый знак отклонения от средней, тем больше сумма в числителе (произведение двух отрицательных чисел также дает положительное число). Большая положительная ковариация говорит о прямой взаимосвязи между переменными. Обратная взаимосвязь дает отрицательную ковариацию. Если количество совпадающих по знаку отклонений примерно равно количеству не совпадающих, то ковариация стремится к нулю, что говорит об отсутствии линейной взаимосвязи.
Таким образом, чем больше по модулю ковариация, тем теснее линейная взаимосвязь. Однако значение ковариации зависит от масштаба данных, поэтому невозможно сравнивать корреляцию для разных переменных. Можно определить только направление по знаку. Для получения стандартизованной величины тесноты взаимосвязи нужно избавиться от единиц измерения путем деления ковариации на произведение стандартных отклонений обеих переменных. В итоге получится формула коэффициента корреляции Пирсона.
![]()
Показатель имеет полное название линейный коэффициент корреляции Пирсона или просто коэффициент корреляции.
Коэффициент корреляции показывает тесноту линейной взаимосвязи и изменяется в диапазоне от -1 до 1. -1 (минус один) означает полную (функциональную) линейную обратную взаимосвязь. 1 (один) – полную (функциональную) линейную положительную взаимосвязь. 0 – отсутствие линейной корреляции (но не обязательно взаимосвязи). На практике всегда получаются промежуточные значения. Для наглядности ниже представлены несколько примеров с разными значениями коэффициента корреляции.
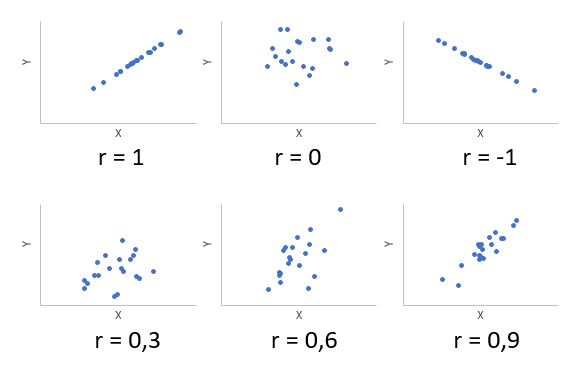
Таким образом, ковариация и корреляция отражают тесноту линейной взаимосвязи. Последняя используется намного чаще, т.к. является относительным показателем и не имеет единиц измерения.
Диаграммы рассеяния дают наглядное представление, что измеряет коэффициент корреляции. Однако нужна более формальная интерпретация. Эту роль выполняет квадрат коэффициента корреляции r2, который называется коэффициентом детерминации, и обычно применяется при оценке качества регрессионных моделей. Снова представьте линию, вокруг которой расположены точки.
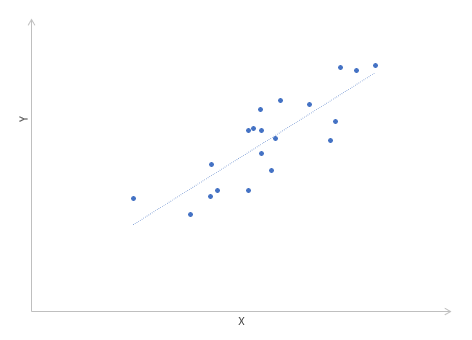
Линейная функция является моделью взаимосвязи между X иY и показывает ожидаемое значение Y при заданном X. Коэффициент детерминации – это соотношение дисперсии ожидаемых Y (точек на прямой линии) к общей дисперсии Y, или доля объясненной вариации Y. При r = 0,1 r2 = 0,01 или 1%, при r = 0,5 r2 = 0,25 или 25%.
Выборочный коэффициент корреляции
Коэффициент корреляции обычно рассчитывают по выборке. Значит, у аналитика в распоряжении не истинное значение, а оценка, которая всегда ошибочна. Если выборка была репрезентативной, то истинное значение коэффициента корреляции находится где-то относительно недалеко от оценки. Насколько далеко, можно определить через доверительные интервалы.
Согласно Центральное Предельной Теореме распределение оценки любого показателя стремится к нормальному с ростом выборки. Но есть проблемка. Распределение коэффициента корреляции вблизи придельных значений не является симметричным. Ниже пример распределения при истинном коэффициенте корреляции ρ = 0,86.
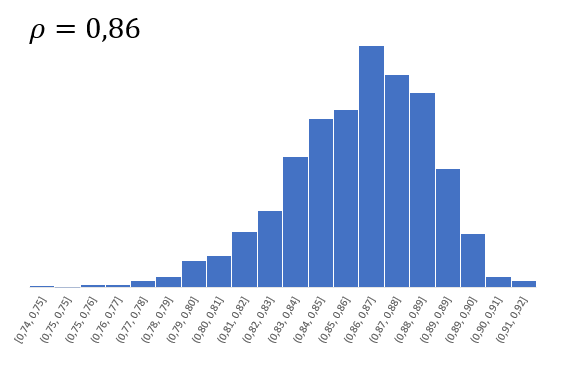
Предельное значение не дает выйти за 1 и, как бы «поджимает» распределение справа. Симметричная ситуация наблюдается, если коэффициент корреляции близок к -1.
В общем рассчитывать на свойства нормального распределения нельзя. Поэтому Фишер предложил провести преобразование выборочного коэффициента корреляции по формуле:
![]()
Распределение z для тех же r имеет следующий вид.
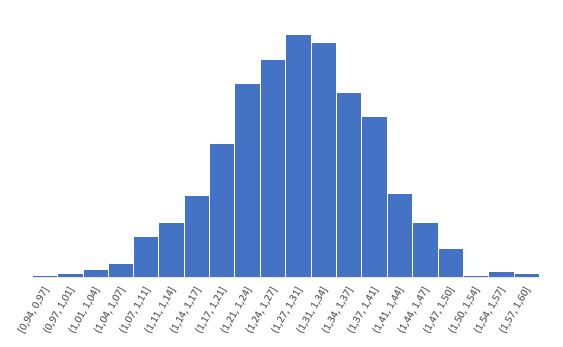
Намного ближе к нормальному. Стандартная ошибка z равна:
![]()
Далее исходя из свойств нормального распределения несложно найти верхнюю и нижнюю границы доверительного интервала для z. Определим квантиль стандартного нормального распределения для заданной доверительной вероятности, т.е. количество стандартных отклонений от центра распределения.
![]()
cγ – квантиль стандартного нормального распределения;
N-1 – функция обратного стандартного распределения;
γ – доверительная вероятность (часто 95%).
Затем рассчитаем границы доверительного интервала.
Нижняя граница z:
![]()
Верхняя граница z:
![]()
Теперь обратным преобразованием Фишера из z вернемся к r.
Нижняя граница r:
![]()
Верхняя граница r:
![]()
Это была теоретическая часть. Переходим к практике расчетов.
Как посчитать коэффициент корреляции в Excel
Корреляционный анализ в Excel лучше начинать с визуализации.
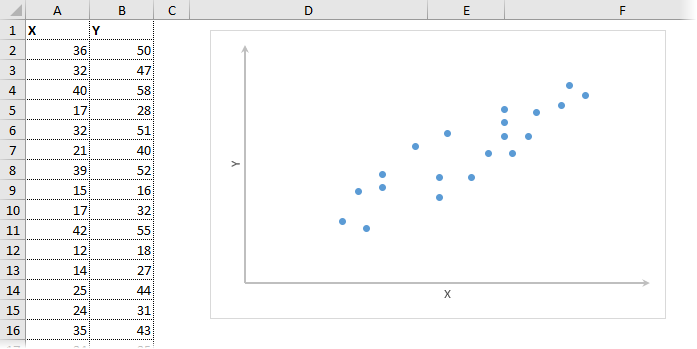
На диаграмме видна взаимосвязь двух переменных. Рассчитаем коэффициент парной корреляции с помощью функции Excel КОРРЕЛ. В аргументах нужно указать два диапазона.

Коэффициент корреляции 0,88 показывает довольно тесную взаимосвязь между двумя показателями. Но это лишь оценка, поэтому переходим к интервальному оцениванию.
Расчет доверительного интервала для коэффициента корреляции в Excel
В Эксель нет готовых функций для расчета доверительного интервала коэффициента корреляции, как для средней арифметической. Поэтому план такой:
— Делаем преобразование Фишера для r.
— На основе нормальной модели рассчитываем доверительный интервал для z.
— Делаем обратное преобразование Фишера из z в r.
Удивительно, но для преобразования Фишера в Excel есть специальная функция ФИШЕР.
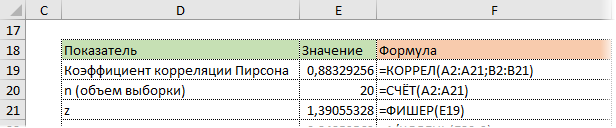
Стандартная ошибка z легко подсчитывается с помощью формулы.
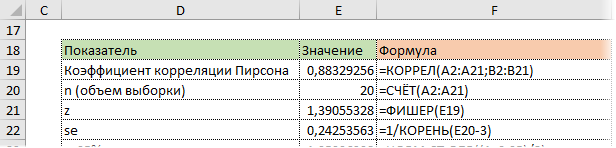
Используя функцию НОРМ.СТ.ОБР, определим квантиль нормального распределения. Доверительную вероятность возьмем 95%.
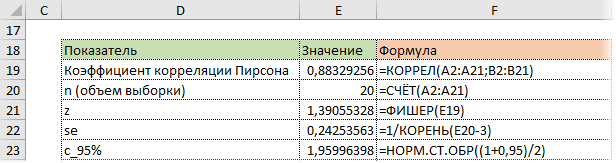
Значение 1,96 хорошо известно любому опытному аналитику. В пределах ±1,96σ от средней находится 95% нормально распределенных величин.
Используя z, стандартную ошибку и квантиль, легко определим доверительные границы z.
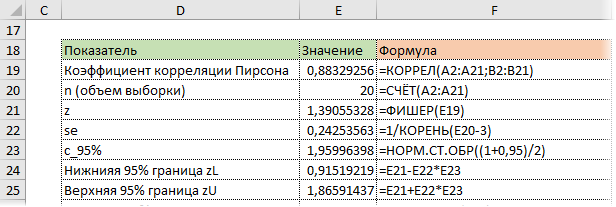
Последний шаг – обратное преобразование Фишера из z назад в r с помощью функции Excel ФИШЕРОБР. Получим доверительный интервал коэффициента корреляции.
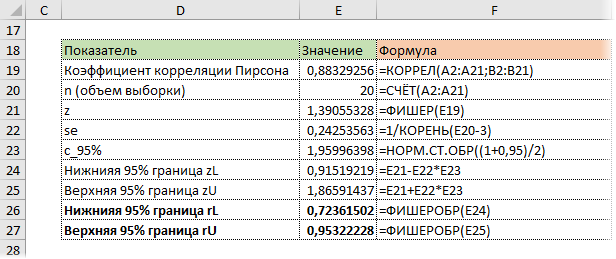
Нижняя граница 95%-го доверительного интервала коэффициента корреляции – 0,724, верхняя граница – 0,953.
Надо пояснить, что значит значимая корреляция. Коэффициент корреляции статистически значим, если его доверительный интервал не включает 0, то есть истинное значение по генеральной совокупности наверняка имеет тот же знак, что и выборочная оценка.
Несколько важных замечаний
1. Коэффициент корреляции Пирсона чувствителен к выбросам. Одно аномальное значение может существенно исказить коэффициент. Поэтому перед проведением анализа следует проверить и при необходимости удалить выбросы. Другой вариант – перейти к ранговому коэффициенту корреляции Спирмена. Рассчитывается также, только не по исходным значениям, а по их рангам (пример показан в ролике под статьей).
2. Синоним корреляции – это взаимосвязь или совместная вариация. Поэтому наличие корреляции (r ≠ 0) еще не означает причинно-следственную связь между переменными. Вполне возможно, что совместная вариация обусловлена влиянием третьей переменной. Совместное изменение переменных без причинно-следственной связи называется ложная корреляция.
3. Отсутствие линейной корреляции (r = 0) не означает отсутствие взаимосвязи. Она может быть нелинейной. Частично эту проблему решает ранговая корреляция Спирмена, которая показывает совместный рост или снижение рангов, независимо от формы взаимосвязи.
В видео показан расчет коэффициента корреляции Пирсона с доверительными интервалами, ранговый коэффициент корреляции Спирмена.
↓ Скачать файл с примером ↓
Поделиться в социальных сетях:
Содержание:
Корреляционный анализ:
Связи между различными явлениями в природе сложны и многообразны, однако их можно определённым образом классифицировать. В технике и естествознании часто речь идёт о функциональной зависимости между переменными x и у, когда каждому возможному значению х поставлено в однозначное соответствие определённое значение у. Это может быть, например, зависимость между давлением и объёмом газа (закон Бойля—Мариотта).
В реальном мире многие явления природы происходят в обстановке действия многочисленных факторов, влияния каждого из которых ничтожно, а число их велико. В этом случае связь теряет свою однозначность и изучаемая физическая система переходит не в определённое состояние, а в одно из возможных для неё состояний. Здесь речь может идти лишь о так называемой статистической связи. Статистическая связь состоит в том, что одна случайная переменная реагирует на изменение другой изменением своего закона распределения. Следовательно, для изучения статистической зависимости нужно знать аналитический вид двумерного распределения. Однако нахождение аналитического вида двумерного распределения по выборке ограниченного объёма, во-первых, громоздко, во-вторых, может привести к значительным ошибкам. Поэтому на практике при исследовании зависимостей между случайными переменными X и У обычно ограничиваются изучением зависимости между одной из них и условным математическим ожиданием другой, т.е. 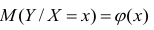
Вопрос о том, что принять за зависимую переменную, а что — за независимую, следует решать применительно к каждому конкретному случаю.
Знание статистической зависимости между случайными переменными имеет большое практическое значение: с её помощью можно прогнозировать значение зависимой случайной переменной в предположении, что независимая переменная примет определенное значение. Однако, поскольку понятие статистической зависимости относится к осредненным условиям, прогнозы не могут быть безошибочными. Применяя некоторые вероятностные методы, как будет показано далее, можно вычислить вероятность того, что ошибка прогноза не выйдет за определенные границы.
Введение в корреляционный анализ
Связь, которая существует между случайными величинами разной природы, например, между величиной X и величиной Y, не обязательно является следствием прямой зависимости одной величины от другой (так называемая функциональная связь).
В некоторых случаях обе величины зависят от целой совокупности разных факторов, общих для обеих величин, в результате чего и формируется связанные друг с другом закономерности. Когда связь между случайными величинами обнаружена с помощью статистики, мы не можем утверждать, что обнаружили причину происходящего изменения параметров, скорее мы лишь увидели два взаимосвязанных следствия.
Например, дети, которые чаще смотрят по телевизору американские боевики, меньше читают. Дети, которые больше читают, лучше учатся. Не так-то просто решить, где тут причины, а где следствия, но это и не является задачей статистики.
Статистика может лишь, выдвинув гипотезу о наличии связи, подкрепить ее цифрами. Если связь действительно имеется, говорят, что между двумя случайными величинами есть корреляция. Если увеличение одной случайной величины связано с увеличением второй случайной величины, корреляция называется прямой.
Например, количество прочитанных страниц за год и средний балл (успеваемость). Если, напротив рост одной величины связано с уменьшением другой, говорят об обратной корреляции. Например, количество боевиков и количество прочитанных страниц. Взаимная связь двух случайных величин называется корреляцией, корреляционный анализ позволяет определить наличие такой связи, оценить, насколько тесна и существенна эта связь. Все это выражается количественно.
Как определить, есть ли корреляция между величинами? В большинстве случаев, это можно увидеть на обычном графике. Например, по каждому ребенку из нашей выборки можно определить величину 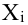 (число страниц) и
(число страниц) и 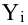 (средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
(средний балл годовой оценки), и записать эти данные в виде таблицы. Построить оси X и Y, а затем нанести на график весь ряд точек таким образом, чтобы каждая из них имела определенную пару координат (,) из нашей таблицы. Поскольку мы в данном случае затрудняемся определить, что можно считать причиной, а что следствием, не важно, какая ось будет вертикальной, а какая горизонтальной.
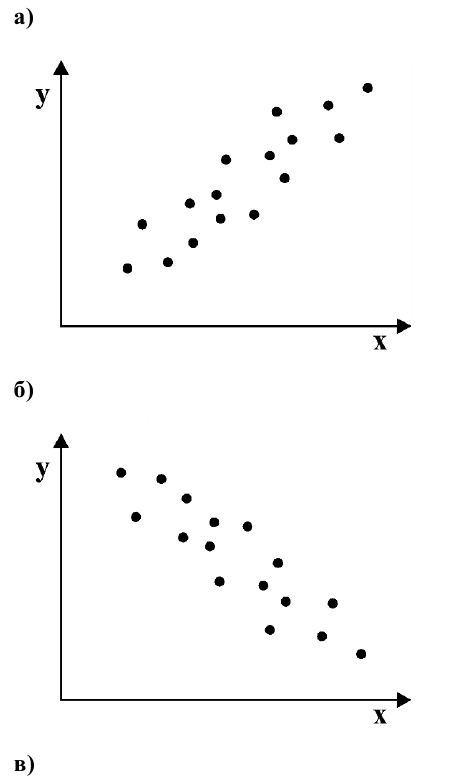
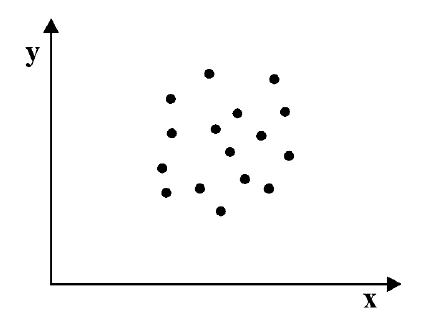
Если график имеет вид а), то это говорит о наличии прямой корреляции, в случае, если он имеет вид б) — корреляция обратная. Отсутствие корреляции тоже можно приблизительно определить по виду графика — это случай в).
С помощью коэффициента корреляции можно посчитать насколько тесная связь существует между величинами.
Пусть, существует корреляция между ценой и спросом на товар. Количество купленных единиц товара в зависимости от цены у разных продавцов показано в таблице:  Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции:
Видно, что мы имеем дело с обратной корреляцией. Для количественной оценки тесноты связи используют коэффициент корреляции: 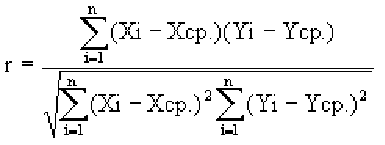
Коэффициент r мы считаем в Excel, с помощью функции 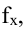 далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
далее статистические функции, функция KOPPEЛ. По подсказке программы вводим мышью в два соответствующих поля два разных массива (X и Y). В нашем случае коэффициент корреляции получился r = -0,988.
Надо отметить, что чем ближе к 0 коэффициент корреляции, тем слабее связь между величинами. Наиболее тесная связь при прямой корреляции соответствует коэффициенту r, близкому к +1. В нашем случае, корреляция обратная, но тоже очень тесная, и коэффициент близок к -1.
Что можно сказать о случайных величинах, у которых коэффициент имеет промежуточное значение? Например, если бы мы получили r = 0,65. В этом случае, статистика позволяет сказать, что две случайные величины частично связаны друг с другом. Скажем на 65% влияние на количество покупок оказывала цена, а на 35% — другие обстоятельства. И еще одно важное обстоятельство надо упомянуть.
Поскольку мы говорим о случайных величинах, всегда существует вероятность, что замеченная нами связь — случайное обстоятельство. Причем вероятность найти связь там, где ее нет, особенно велика тогда, когда точек в выборке мало, а при оценке Вы не построили график, а просто посчитали значение коэффициента корреляции на компьютере. Так, если мы оставим всего две разные точки в любой произвольной выборке, коэффициент корреляции будет равен или +1 или -1. Из школьного курса геометрии мы знаем, что через две точки можно всегда провести прямую линию. Для оценки статистической достоверности факта обнаруженной Вами связи полезно использовать так называемую корреляционную поправку: 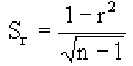
Связь нельзя считать случайной, если: 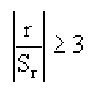
В то время как задача корреляционного анализа — установить, являются ли данные случайные величины взаимосвязанными, цель регрессионного анализа — описать эту связь аналитической зависимостью, т.е. с помощью уравнения. Мы рассмотрим самый несложный случай, когда связь между точками на графике может быть представлена прямой линией. Уравнение этой прямой линии 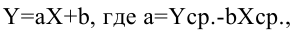
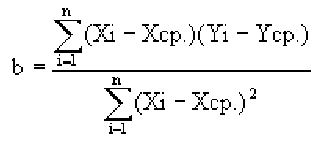
Зная уравнение прямой, мы можем находить значение функции по значению аргумента в тех точках, где значение X известно, a Y — нет. Эти оценки бывают очень нужны, но они должны использоваться осторожно, особенно, если связь между величинами не слишком тесная. Отметим также, что из сопоставления формул для b и r видно, что коэффициент не дает значение наклона прямой, а лишь показывает сам факт наличия связи.
Определение формы связи. Понятие регрессии
Определить форму связи — значит выявить механизм получения зависимой случайной переменной. При изучении статистических зависимостей форму связи можно характеризовать функцией регрессии (линейной, квадратной, показательной и т.д.).
Условное математическое ожидание 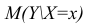 случайной переменной К, рассматриваемое как функция х, т.е.
случайной переменной К, рассматриваемое как функция х, т.е. 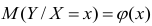 , называется
, называется
функцией регрессии случайной переменной Y относительно X (или функцией регрессии Y по X). Точно так же условное математическое ожидание
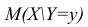 случайной переменной X, т.е.
случайной переменной X, т.е. 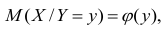 называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
называется функцией регрессии случайной переменной X относительно Y (или функцией регрессии X по Y).
На примере, дискретного распределения найдём функцию регрессии.
Функция регрессии имеет важное значение при статистическом анализе зависимостей между переменными и может быть использована для прогнозирования одной из случайных переменных, если известно значение другой случайной переменной. Точность такого прогноза определяется дисперсией условного распределения.
Несмотря на важность понятия функции регрессии, возможности её практического применения весьма ограничены. Для оценки функции регрессии необходимо знать аналитический вид двумерного распределения (X, Y). Только в этом случае можно точно определить вид функции регрессии, а затем оценить параметры двумерного распределения. Однако для подобной оценки мы чаще всего располагаем лишь выборкой ограниченного объема, по которой нужно найти вид двумерного распределения (X, Y), а затем вид функции регрессии. Это может привести к значительным ошибкам, так как одну и ту же совокупность точек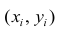 на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
на плоскости можно одинаково успешно описать с помощью различных функций. Именно поэтому возможности практического применения функции регрессии ограничены. Для характеристики формы связи при изучении зависимости используют понятие кривой регрессии.
Кривой регрессии Y по X (или Y на А) называют условное среднее значение случайной переменной У, рассматриваемое как функция определенного класса, параметры которой находят методом наименьших квадратов по наблюдённым значениям двумерной случайной величины (х, у), т.е.
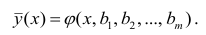
Аналогично определяется кривая регрессии X по Y (X на Y):
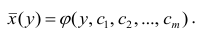
Кривую регрессии называют также эмпирическим уравнением регрессии или просто уравнением регрессии. Уравнение регрессии является оценкой соответствующей функции регрессии.
Возникает вопрос: почему для определения кривой регрессии
используют именно условное среднее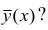 Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е.
Функция у(х) обладает одним замечательным свойством: она даёт наименьшую среднюю погрешность оценки прогноза. Предположим, что кривая регрессии — произвольная функция. Средняя погрешность прогноза по кривой регрессии определяется математическим ожиданием квадрата разности между измеренной величиной и вычисленной по формуле кривой регрессии, т.е. 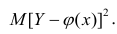 . Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является
. Естественно потребовать вычисления такой кривой регрессии, средняя погрешность прогноза по которой была бы наименьшей. Таковой является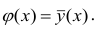 Это следует из свойств минимальности рассеивания около центра распределения
Это следует из свойств минимальности рассеивания около центра распределения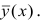
Если рассеивание вычисляется относительно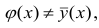 то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как
то средний квадрат отклонения увеличивается. Поэтому можно сказать, что кривая регрессии, выражаемая как 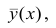 минимизирует среднеквадратическую погрешность прогноза величины Y по X.
минимизирует среднеквадратическую погрешность прогноза величины Y по X.
Основные положения корреляционного анализа
Статистические связи между переменными можно изучать методом корреляционного и регрессионного анализа. С помощью этих методов решают разные задачи; требования, предъявляемые к исследуемым переменным, в каждом методе различны.
Основная задача корреляционного анализа — выявление связи между случайными переменными путём точечной и интервальной оценки парных коэффициентов корреляции, вычисления и проверки значимости множественных коэффициентов корреляции и детерминации, оценки частных коэффициентов корреляции. Корреляционный анализ позволяет также оценить функцию регрессии одной случайной переменной на другую.
Предпосылки корреляционного анализа следующие:
- 1) переменные величины должны быть случайными;
- 2) случайные величины должны иметь совместное нормальное распределение.
Рассмотрим простейший случай корреляционного анализа — двумерную модель. Введём основные понятия и опишем принцип проведения корреляционного анализа. Пусть X и Y — случайные переменные, имеющие совместное нормальное распределение. В этом случае связь между X и Y можно описать коэффициентом корреляции p;. Этот коэффициент определяется как ковариация между X и Y, отнесённая к их среднеквадратическим отклонениям:
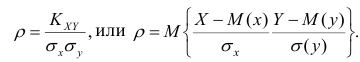 (1.1)
(1.1)
Оценкой коэффициента корреляции является выборочный коэффициент корреляции r. Для его нахождения необходимо знать оценки следующих параметров: 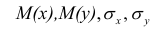 . Наилучшей оценкой
. Наилучшей оценкой
математического ожидания является среднее арифметическое, т.е.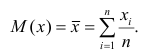
Оценкой дисперсии служит выборочная дисперсия, т.е.
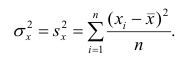
Тогда выборочный коэффициент корреляции
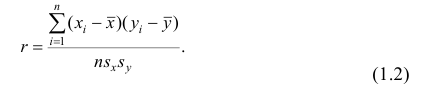
Коэффициент р называют также парным коэффициентом корреляции, а r— выборочным парным коэффициентом корреляции.
При совместном нормальном законе распределения случайных величин X и Y, используя рассмотренные выше параметры распределения и коэффициент корреляции, можно получить выражение для условного математического ожидания, т. е, записать выражение для функции регрессии одной случайной величины на другую. Так, функция регрессии Y на X имеет вид:
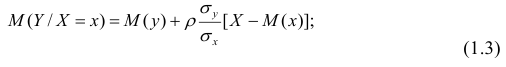
функция регрессии X на Y — следующий вид:
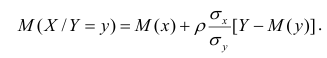
Выражения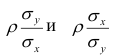 — называют коэффициентами регрессии.
— называют коэффициентами регрессии.
Подставив в (1.3) соответствующие оценки параметров, получим уравнения регрессии, график которых — прямая линия, проходящая через точку 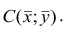 Запишем уравнение регрессии у на х и х на у:
Запишем уравнение регрессии у на х и х на у:
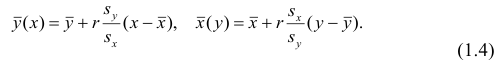
Таким образом, в корреляционном анализе на основе оценок параметров двумерной нормальной совокупности получаем оценки тесноты связи между случайными переменными и можем оценить регрессию одной переменной на другую. Особенностью корреляционного анализа является строго линейная зависимость между переменными. Это обусловливается исходными предпосылками. На практике корреляционный анализ можно применять для обработки наблюдений, сделанных на предприятиях при нормальных условиях работы, если случайные изменения свойства сырья или других факторов вызывают случайные изменения свойств продукции.
Свойства коэффициента корреляции
Коэффициент корреляции является одним из самых распространенных способов измерения связи между случайными переменными. Рассмотрим некоторые свойства этого коэффициента.
Теорема 1. Коэффициент корреляции принимает значения на интервале (-1, +1).
Доказательство. Докажем справедливость утверждения для случая дискретных переменных. Запишем явно неотрицательное выражение:
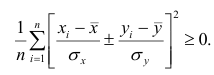
Возведём выражение под знаком суммы в квадрат:
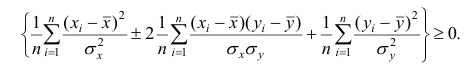
Первое и третье из слагаемых равны единице, поскольку из определения дисперсии следует, что 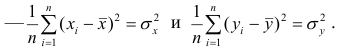
Таким образом, окончательно получаем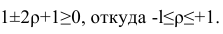
Если коэффициент корреляции положителен, то связь между переменными также положительна и значения переменных увеличиваются или уменьшаются одновременно. Если коэффициент корреляции имеет отрицательное значение, то при увеличении одной переменной уменьшается другая.
Приведём следующее важное свойство коэффициента корреляции: коэффициент корреляции не зависит от выбора начала отсчёта и единицы измерения, т. е. от любых постоянных 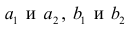 таких, что
таких, что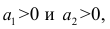 т.е.
т.е.
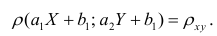
Таким образом, переменные X и У можно уменьшать или увеличивать в а раз, а также вычитать или прибавлять к значениям X и У одно и то же число b. В результате величина коэффициента корреляции не изменится.
Если коэффициент корреляции 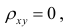 то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
то случайные переменные некоррелированы. Понятие некоррелированности не следует смешивать с понятием независимости, независимые величины всегда некоррелированы. Однако обратное утверждение невероятно: некоррелированные величины могут быть зависимы и даже функционально, однако эта связь не линейная.
Выборочный коэффициент корреляции вычисляют по формуле (1.2). Имеется несколько модификаций этой формулы, которые удобно использовать при той или иной форме представления исходной информации. Так, при малом числе наблюдений выборочный коэффициент корреляции удобно вычислять по формуле
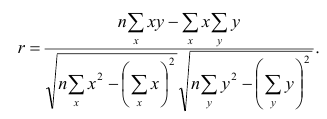
Если информация имеет вид корреляционной таблицы (см. п 1.5), то удобно пользоваться формулой
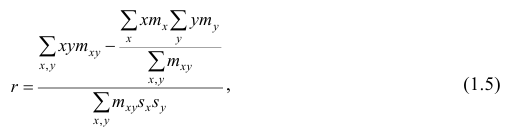
где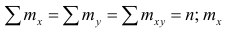 — суммарная частота наблюдаемого значенияпризнака х при всех значениях
— суммарная частота наблюдаемого значенияпризнака х при всех значениях 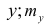 — суммарная частота наблюдаемого значения признака упри всех значениях х;
— суммарная частота наблюдаемого значения признака упри всех значениях х; 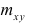 — частота появления пары признаков (x, у).
— частота появления пары признаков (x, у).
Из формулы (1.2) очевидно, что 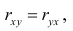 т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
т.е. величина выборочного коэффициента корреляции не зависит от порядка следования переменных, поэтому обычно пишут просто r.
Поле корреляции. Вычисление оценок параметров двумерной модели
На практике для вычисления оценок параметров двумерной модели удобно использовать корреляционную таблицу и поле корреляции. Пусть, например, изучается зависимость между объёмом выполненных работ (у) и накладными расходами (x). Имеем выборку из генеральной совокупности, состоящую из 150 пар переменных 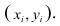 Считаем, что предпосылки корреляционного анализа выполнены.
Считаем, что предпосылки корреляционного анализа выполнены.
Пару случайных чисел 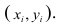 можно изобразить графически в виде точки с координатами
можно изобразить графически в виде точки с координатами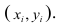 . Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
. Аналогично можно изобразить весь набор пар случайных чисел (всю выборку). Однако при большом объёме выборки это затруднительно. Задача упрощается, если выборку упорядочить, т.е. переменные сгруппировать. Сгруппированные ряды могут быть как дискретными, так и интервальными.
По осям координат откладывают или дискретные значения переменных, или интервалы их изменения. Для интервального ряда наносят координатную сетку. Каждую пару переменных из данной выборки изображают в виде точки с соответствующими координатами для дискретного ряда или в виде точки в соответствующей клетке для интервального ряда. Такое изображение корреляционной зависимости называют полем корреляции. На рис. 1.1 изображено поле корреляции для выборки, состоящей из 150 пар переменных (ряд интервальный).
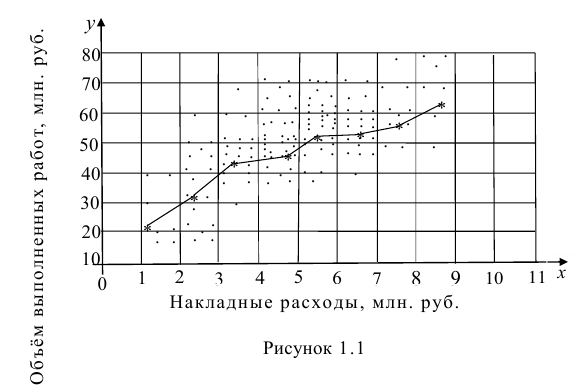
Если вычислить средние значения у в каждом интервале изменения х [обозначим их 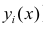 )], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
)], нанести эти точки на рис. 1.1 и соединить между собой, то получим ломаную линию, по виду которой можно судить, как в среднем меняются у в зависимости от изменения х. По виду этой линии можно также сделать предположение о форме связи между переменными. В данном случае ломаную линию можно аппроксимировать прямой линией, так как она достаточно хорошо приближается к ней. По выборочным данным можно построить также корреляционную табл. 1.1.
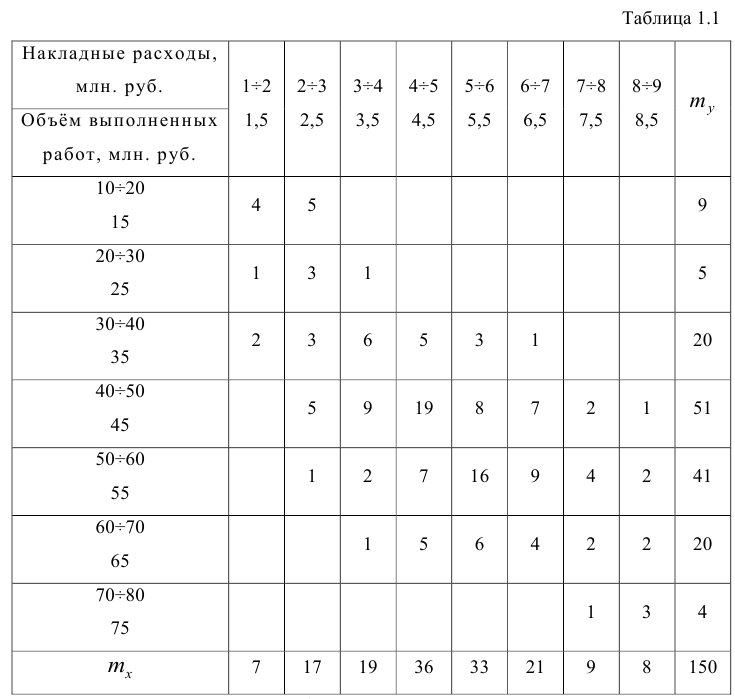
Корреляционную таблицу, как и поле корреляции, строят по
сгруппированному ряду (дискретному или интервальному). Табл. 1.1 построена на основе интервального ряда. В первой строке и первом столбце таблицы помещают интервалы изменения х и у и значения середин интервалов. Так, например, 1,5 — середина интервала изменения *=1-2,15— середина интервала изменения у= 10-20. В ячейки, образованные пересечением строк и столбцов, заносят частоты попадания пар значений (л у) в соответствующие интервалы по х и у. Например, частота 4 означает, что в интервал изменения у от 10 до 20 попало 4 пары наблюдавшихся значений. Эти частоты обозначают 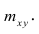 В 9-й строке и 10-м столбце находятся значения
В 9-й строке и 10-м столбце находятся значения 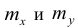 — суммы
— суммы 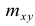 по соответствующим столбцу и строке.
по соответствующим столбцу и строке.
Как будет показано в дальнейшем, корреляционно таблицей удобно пользоваться при вычислении коэффициентов корреляций и параметров уравнений регрессии.
Корреляционная таблица построена на основе интервального ряда, поэтому для оценок параметров воспользуемся формулами гл. 1 для вычисления средней арифметической и дисперсии. Имеем:
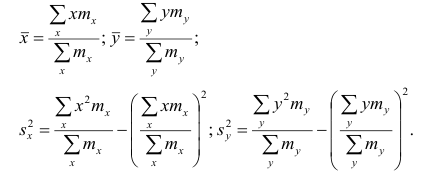 (1.6)
(1.6)
Проверка гипотезы о значимости коэффициента корреляции
На практике коэффициент корреляции р обычно неизвестен. По результатам выборки может быть найдена его точечная оценка — выборочный коэффициент корреляции r.
Равенство нулю выборочного коэффициента корреляции ещё не свидетельствует о равенстве нулю самого коэффициента корреляции, а следовательно, о некоррелированности случайных величин X и Y. Чтобы выяснить, находятся ли случайные величины в корреляционной зависимости, нужно проверить значимость выборочного коэффициента корреляции г, т.е. установить, достаточна ли его величина для обоснованного вывода о наличии корреляционной связи. Для этого проверяют нулевую гипотезу 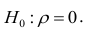 . Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют
. Предполагается наличие двумерного нормального распределения случайных переменных; объём выборки может быть любым. Вычисляют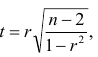
которая имеет распределение Стьюдента с k=n-2
степенями свободы. Для проверки нулевой гипотезы по уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (t-распределение; см. табл. 1 приложения) критическое значение 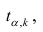 удовлетворяющее условию
удовлетворяющее условию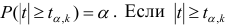 , то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При
, то нулевую гипотезу об отсутствии корреляционной связи между переменными X и Y следует отвергнуть. Переменные считают зависимыми. При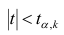 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
В случае значимого выборочного коэффициента, корреляции есть смысл построить доверительный интервал для коэффициента корреляций р. Однако для этого нужно знать закон распределения выборочного коэффициента корреляции r.
Плотность вероятности выборочного коэффициента корреляции имеет сложный вид, поэтому прибегают к специально подобранным функциям от выборочного коэффициента корреляции, которые сводятся к хорошо изученным распределениям, например нормальному или Стьюдента. Чаще всего для подбора функции применяют преобразование Фишера. Вычисляют статистику:
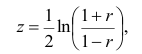
где r=thz — гиперболический тангенс от z.
Распределение статистики z хорошо аппроксимируется нормальным распределением с параметрами
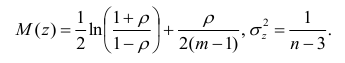
В этом, случае доверительный интервал для римеетвид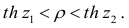 Величины
Величины 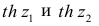 находят по таблицам по следующим значениям:
находят по таблицам по следующим значениям:
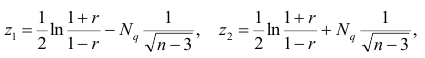
где 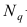 — нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции
— нормированная функция Лапласа для q % доверительного интервала (см. табл. 2 приложений значение функции 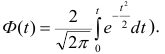
Если коэффициент корреляции значим, то коэффициенты регрессии также значимо отличаются от нуля, а интервальные оценки для них можно получить по следующим формулам:
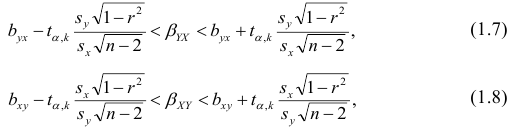
где 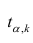 имеет распределение Стьюдента с k=n—2 степенями свободы.
имеет распределение Стьюдента с k=n—2 степенями свободы.
Корреляционное отношение
На практике часто предпосылки корреляционного анализа нарушаются: один из признаков оказывается величиной не случайной, или признаки не имеют совместного нормального распределения. Однако статистическая зависимость между ними существует. Для изучения связи между признаками в этом случае существует общий показатель зависимости признаков, основанный на показателе изменчивости — общей (или полной) дисперсии.
Полной называется дисперсия признака относительно его математического ожидания. Так, для признака Y это 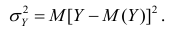 Дисперсию
Дисперсию 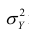 можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
можно разложить на две составляющие, одна из которых характеризует влияние фактора X на Y, другая — влияние прочих факторов.
Очевидно, чем меньше влияние прочих факторов, тем теснее связь, тем более приближается она к функциональной. Представим 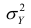 в следующем виде:
в следующем виде:
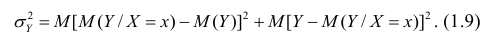
Первое слагаемое обозначим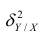 Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим
Это дисперсия функции регрессии относительно математического ожидания признака (в данном случае признака У);.она измеряет влияние признака X на Y. Второе слагаемое обозначим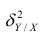 . Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией
. Это дисперсия признака Y относительно функции регрессии. Её называют также средней из условных дисперсий или остаточной дисперсией 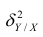 измеряет влияние на Y прочих факторов.
измеряет влияние на Y прочих факторов.
Покажем, что 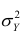 действительно можно разложить на два таких слагаемых:
действительно можно разложить на два таких слагаемых:
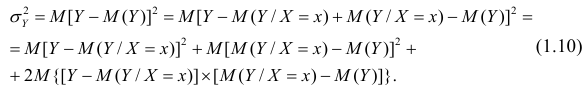
Для простоты полагаем распределение дискретным. Имеем 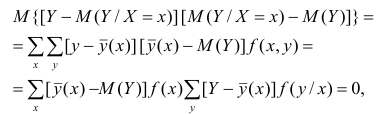
так как при любом х справедливо равенство
Третье слагаемое в равенстве (1.10) равно нулю, поэтому равенство (1.9) справедливо. Поскольку второе слагаемое в равенстве (1.9) оценивает влияние признака X на Y, то его можно использовать для оценки тесноты связи между X и Y. Тесноту связи удобно оценивать в единицах общей дисперсии 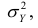 т.е. рассматривать отношение
т.е. рассматривать отношение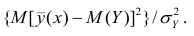 . Эту величину обозначают
. Эту величину обозначают 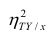 и называют теоретическим корреляционным отношением. Таким образом,
и называют теоретическим корреляционным отношением. Таким образом,
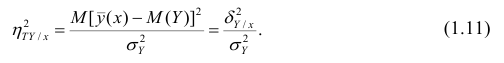
Разделив обе части равенства (1.9) на 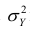 получим
получим
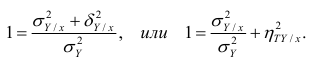
Из последней формулы имеем

Поскольку 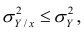 так как
так как 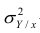 — составная часть
— составная часть 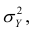 то из равенства (1.12) следует, что значение
то из равенства (1.12) следует, что значение 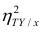 всегда заключено между нулем и единицей.
всегда заключено между нулем и единицей.
Все сделанные выводы справедливы и для 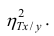 Из равенства (1.12)
Из равенства (1.12)
следует, что 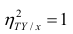 только тогда, когда
только тогда, когда 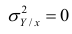 , т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии
, т.е. отсутствует влияние прочих факторов и всё распределение сконцентрировано на кривой регрессии 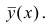 . В этом случае между Y и X существует функциональная зависимость.
. В этом случае между Y и X существует функциональная зависимость.
Далее, из равенства (1.12) следует, что 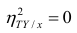 тогда и только тогда, когда
тогда и только тогда, когда
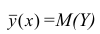 = const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
= const, т.е. линия регрессии У по X — горизонтальная прямая, проходящая через центр распределения. В этом случае можно сказать, что переменная У не коррелирована с X (рис. 1.2,а, б, в).
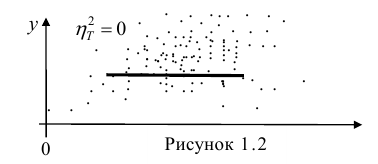
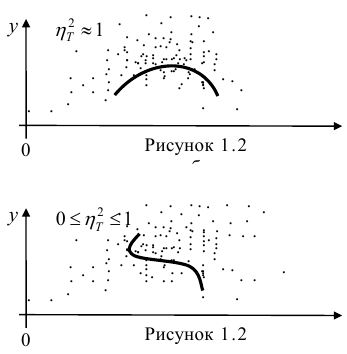
Аналогичными свойствами обладает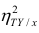 — показатель тесноты связи между X и У.
— показатель тесноты связи между X и У.
Часто используют величину

Считают, что она не может быть отрицательной. Значения величины 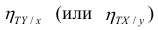 также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
также могут находиться лишь в пределах от нуля до единицы. Это очевидно из формулы (1.13).
Значения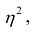 лежащие в интервале
лежащие в интервале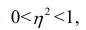 являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение
являются показателями тесноты группировки точек около кривой регрессии независимо от её вида (формы связи). Корреляционное отношение 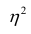 связано
связано 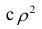 следующим образом:
следующим образом: 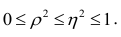 В случае линейной зависимости между переменными
В случае линейной зависимости между переменными 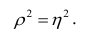
Разность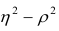 может быть использована как показатель нелинейности связи между переменными.
может быть использована как показатель нелинейности связи между переменными.
При вычислении 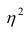 по выборочным данным получаем выборочное корреляционное отношение. Обозначим его
по выборочным данным получаем выборочное корреляционное отношение. Обозначим его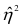 . Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид
. Вместо дисперсий в этом случае используются их оценки. Тогда формула (1.12) принимает вид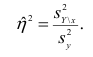
Понятие о многомерном корреляционном анализе
Частный коэффициент корреляции. Основные понятия корреляционного анализа, введенные для двумерной модели, можно распространить на многомерный случай. Задачи и предпосылки корреляционного анализа были сформулированы в п. 1.3. Однако если при изучении взаимосвязи переменных по двумерной модели мы ограничивались рассмотрением парных коэффициентов корреляции, то для многомерной модели этого недостаточно. Многообразие связей между переменными находит отражение в частных и множественных коэффициентах корреляции.
Пусть имеется многомерная нормальная совокупность с m признаками 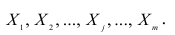 В этом случае взаимозависимость между признаками
В этом случае взаимозависимость между признаками
можно описать корреляционной матрицей. Под корреляционной матрицей будем понимать, матрицу, составленную из парных коэффициентов корреляции (вычисляются по формуле (1,1)):
где 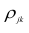 — парные коэффициенты корреляции; m — порядок матрицы.
— парные коэффициенты корреляции; m — порядок матрицы.
Оценкой парного коэффициента корреляции является выборочный парный коэффициент корреляции, определяемый по формуле (1.2), однако для m признаков формула (9.2) принимает вид
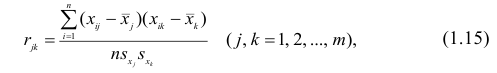
где 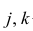 — порядковые номера признаков.
— порядковые номера признаков.
Как и в двумерном случае, для оценки коэффициента корреляции необходимо оценить математические ожидания и дисперсии. В многомерном корреляционном анализе имеем т математических ожиданий и m дисперсий, а также m(m—1)/2 парных коэффициентов корреляции. Таким образом, нужно произвести оценку 2m+m(m—1)/2 параметров.
В случае многомерной корреляции зависимости между признаками более многообразны и сложны, чем в двумерном случае. Одной корреляционной матрицей нельзя полностью описать зависимости между признаками. Введём понятие частного коэффициента корреляции l-го порядка.
Пусть исходная совокупность состоит из т признаков. Можно изучать зависимости между двумя из них при фиксированном значении l признаков из m-2 оставшихся. Рассмотрим, например, систему из 5 признаков. Изучим зависимости между 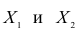 при фиксированном значении признака
при фиксированном значении признака 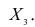 В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
В этом случае имеем частный коэффициент корреляции первого порядка, так как фиксируем только один признак.
Рассмотрим более подробно структуру частных коэффициентов корреляции на примере системы из трёх признаков 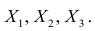 . Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков
. Эта система позволяет изучить частные коэффициенты корреляции только первого порядка, так как нельзя фиксировать больше одного признака. Частный коэффициент корреляции первого порядка для признаков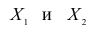 при фиксированном значении
при фиксированном значении 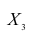 выражается через парные коэффициенты
выражается через парные коэффициенты
корреляции и имеет вид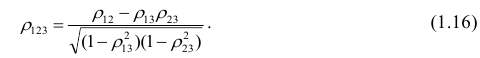
Частный коэффициент корреляции, так же как и парный коэффициент корреляции, изменяется от —1 до +1, В общем виде, когда система состоит из m признаков, частный коэффициент корреляции l-го порядка может быть найден из корреляционной матрицы. Если 1=m—2, то рассматривается матрица порядка m, при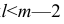 — подматрица порядкаl+2, составленная из элементов матрицы
— подматрица порядкаl+2, составленная из элементов матрицы 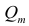 , которые отвечают индексам коэффициента частной
, которые отвечают индексам коэффициента частной
корреляции. Например, корреляционная матрица системы из пяти признаков имеет вид
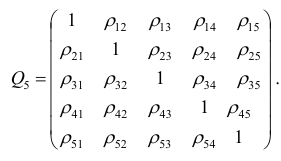
Для определения частного коэффициента корреляции второго порядка, например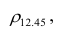 следует использовать подматрицу четвертого порядка,
следует использовать подматрицу четвертого порядка,
вычеркнув из исходной матрицы 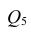 третью строку и третий столбец, так как признак
третью строку и третий столбец, так как признак 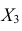 не рассматривают.
не рассматривают.
В общем виде формулу частного коэффициента корреляции l-го порядка (1=m—2) можно записать в виде
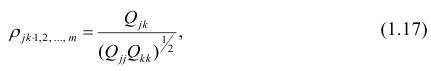
где 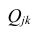 — алгебраические дополнения к элементу
— алгебраические дополнения к элементу 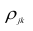 корреляционной
корреляционной
матрицы 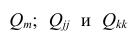 — алгебраические дополнения к элементам
— алгебраические дополнения к элементам 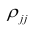 и ркк корреляционной матрицы
и ркк корреляционной матрицы 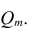
Очевидно, что выражение (1.16) является частым случаем выражения (1.17), в чём легко убедиться, рассмотрев корреляционную матрицу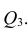
Оценкой частного коэффициента корреляции l-го порядка является выборочный частный коэффициент корреляции l-го порядка. Он вычисляется на основе корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции:
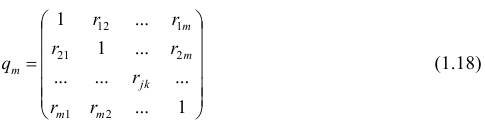
Формула выборочного частного коэффициента корреляции имеет вид

где 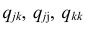 — алгебраические дополнения к соответствующим элементам матрицы (1.18).
— алгебраические дополнения к соответствующим элементам матрицы (1.18).
Частный коэффициент корреляции l-го порядка, вызволенный на основе п наблюдений над признаками, имеет такое же распределение, что и парный коэффициент корреляции, вычисленный  наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
наблюдениям. Поэтому значимость частных коэффициентов корреляции оценивают так же, как и в п. 1.6.
Множественный коэффициент корреляции
Часто представляет интерес оценить связь одного из признаков со всеми остальными. Это можно сделать с помощью множественного, или совокупного, коэффициента корреляции

где 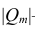 —определитель корреляционной матрицы
—определитель корреляционной матрицы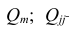 —алгебраическое
—алгебраическое
дополнение к элементу 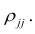
Квадрат коэффициента множественной корреляции 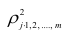 называется
называется
множественным коэффициентом детерминации. Коэффициенты множественной корреляции и детерминации — величины положительные, принимающие значения в интервале Оценками этих
Оценками этих
коэффициентов являются выборочные множественные коэффициенты корреляции и детерминации, которые обозначают соответственно 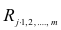 и
и
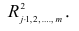 Формула для вычисления выборочного множественного коэффициента корреляции имеет вид
Формула для вычисления выборочного множественного коэффициента корреляции имеет вид

где 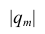 —определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции;
—определитель корреляционной матрицы, составленной из выборочных парных коэффициентов корреляции; 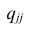 алгебраическое дополнение к элементу
алгебраическое дополнение к элементу 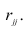
Многомерный корреляционный анализ позволяет получить оценку функции регрессии — уравнение регрессии. Коэффициенты в уравнении регрессии можно найти непосредственно через выборочные парные коэффициенты корреляции или воспользоваться методом многомерной регрессии, который мы рассмотрим в вопросе 2.7. В этом случае все предпосылки регрессионного анализа оказываются выполненными и, кроме того, связь между переменными строго линейна.
Ранговая корреляция
В некоторых случаях встречаются признаки, не поддающиеся количественной оценке (назовём такие признаки объектами). Попытаемся, например, оценить соотношение между математическими и музыкальными способностями группы учащихся. «Уровень способностей» является переменной величиной в том смысле; что он варьирует от одного индивидуума к другому. Его можно измерить, если выставлять каждому индивидууму отметки. Однако этот способ лишен объективности, так как разные экзаменаторы могут выставить одному и тому же учащемуся разные отметки. Элемент субъективизма можно исключить, если учащиеся будут ранжированы. Расположим учащихся по порядку, в соответствии со степенью способностей и присвоим каждому из них порядковый номер, который назовем рангом. Корреляция между рангами более точно отражает соотношение между способностями учащихся, чем корреляция между отметками.
Тесноту связи между рангами измеряют так же, как и между признаками. Рассмотрим уже известную формулу коэффициента корреляции
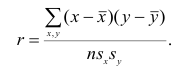
Пусть 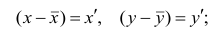 тогда, учитывая,
тогда, учитывая,
что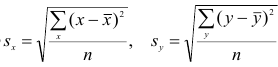 ,можно записать
,можно записать

В зависимости от того, что принять за меру различия между величинами 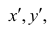 можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла
можно получить различные коэффициенты связи между рангами. Обычно используют коэффициент корреляции рангов Кэнделла 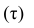 и коэффициент корреляции рангов Спирмэна р.
и коэффициент корреляции рангов Спирмэна р.
Введём следующую меру различия между объектами: будем считать 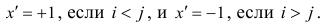 Поясним сказанное на примере. Имеем две последовательности:
Поясним сказанное на примере. Имеем две последовательности:
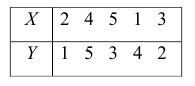
Рассмотрим отдельно каждую из них. В последовательности X первой паре элементов —2; 4 припишем значение +1, так как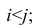 второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку
второй паре 2; 5 также припишем значение +1, третьей паре 2; 1 припишем значение —1, поскольку 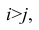 и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
и т.д. Последовательно перебираем все пары, причём каждая пара должна быть учтена один раз. Так, если учтена пара 2; 1, то не следует учитывать пару 1; 2. Аналогичные действия проделаем с последовательностью У, причём порядок перебора пар должен в точности повторять порядок перебора пар в последовательности X. Результаты этих действий представим в виде табл. 1.3.
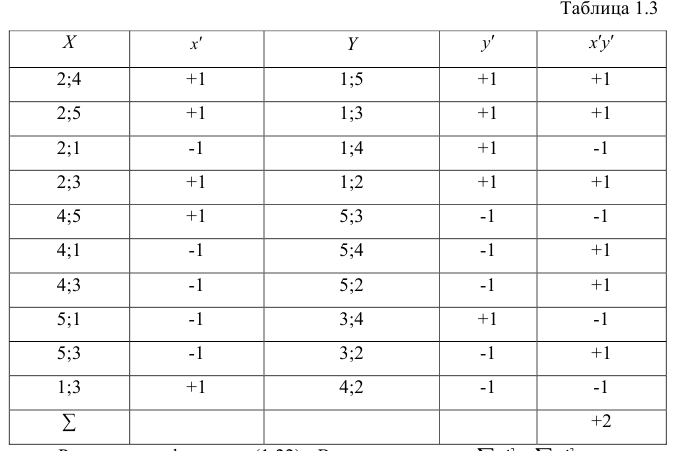
Рассмотрим формулу ( 1 .22). В нашем случае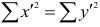 и равна
и равна
количеству пар, участвовавших в переборе. Каждая пара встречается только один раз, поэтому их общее количество равно числу сочетаний из n по 2, т.е.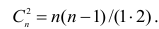 Обозначая
Обозначая 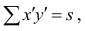 получаем формулу коэффициента корреляции рангов Кэнделла:
получаем формулу коэффициента корреляции рангов Кэнделла:
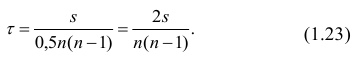
Теперь рассмотрим другую меру различия между объектами. Если обозначить через  средний ранг последовательности X, через
средний ранг последовательности X, через 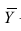 — средний ранг последовательности Т, то
— средний ранг последовательности Т, то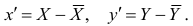 Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна
Поскольку ранги последовательности X и Y есть числа натурального ряда, то их сумма равна 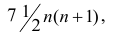 а средний ранг
а средний ранг 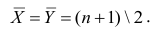
Тогда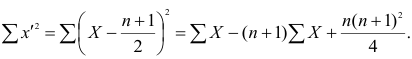 Сумма
Сумма
чисел натурального ряда равна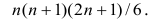
Тогда 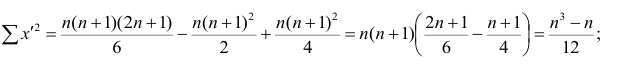
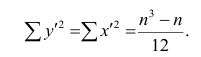
Введём новую величину d, равную разности между рангами: d=X—Y, и определим через неё величину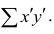 . Имеем:
. Имеем: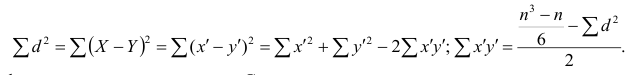
Коэффициент корреляции рангов Спирмэна

У коэффициентов 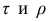 разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает
разные масштабы, они отличаются шкалами измерений. Поэтому на практике нельзя ожидать, что они совпадут. Чаще всего, если значения обоих коэффициентов не слишком, близки к 1, p; по абсолютной величине примерно на 50% превышает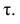 Выведены неравенства, связывающие
Выведены неравенства, связывающие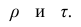 Например, при больших n можно пользоваться следующим приближённым соотношением:
Например, при больших n можно пользоваться следующим приближённым соотношением: 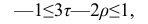 или
или
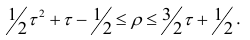 Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент
Коэффициент p легче рассчитать, однако с теоретической точки зрения больший интерес представляет коэффициент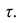
При вычислении коэффициента корреляций рангов Кэнделла для подсчёта s можно использовать следующий приём: одну из последовательностей упорядочивают так, чтобы её элементы были числами натурального ряда; соответственно изменяют и другую последовательность. Тогда сумму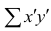 можно подсчитывать лишь по последовательности К, так как все
можно подсчитывать лишь по последовательности К, так как все 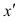 равны +1.
равны +1.
Если нельзя установить ранговое различие нескольких объектов, говорят, что такие объекты являются связанными. В этом случае объектам приписывается средний ранг. Например, если связанными являются объекты 4 и 5, то им приписывают ранг 4.5; если связанными являются объекты 1, 2, 3, 4 и 5, то их средний ранг (1+2+3+4+5)/5=3. Сумма рангов связанных объектов должна быть равна сумме рангов при ранжировании без связей. Формулы коэффициентов корреляции для 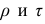 в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
в этом случае также можно вывести из формулы обобщённого коэффициента корреляции, только знаменатель выражения (1.21) в этом случае не равен n(n—1)/2. Если / последовательных членов связаны, то все оценки, относящиеся к любой вобранной из них паре, равны нулю; число таких пар t(t—1), Следовательно,
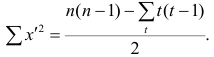 Соответственно для другой последовательности
Соответственно для другой последовательности
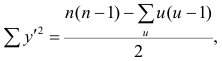
где t и u—число связанных пар в последовательностях.
Обозначая 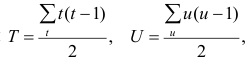 получаем
получаем
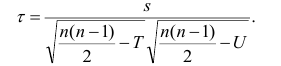
Аналогично находим выражение для р. Только в этом случае
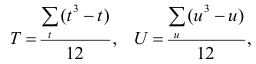 , где е и г — число связанных пар в
, где е и г — число связанных пар в
последовательностях, а
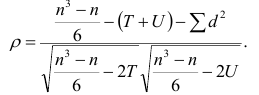
Если имеется несколько последовательностей, то возникает необходимость определить общую меру согласованности между ними. Такой мерой является коэффициент копкордации.
Пусть ь — число последовательностей, т — количество рангов в каждой последовательности. Тогда коэффициент конкордации

где d — фактически встречающееся отклонение от среднего значения суммы рангов одного объекта.
Коэффициент корреляции рангов может быть использован для быстрого оценивания взаимосвязи между признаками, не имеющими нормального распределения, и полезен в тех случаях, когда признаки поддаются ранжированию, но не могут быть точно измерены.
Пример:
Для данных табл. 13 найти выборочный коэффициент корреляции, проверить его значимость на уровне 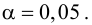
Решение. Для вычислений составим таблицу. Находим суммы
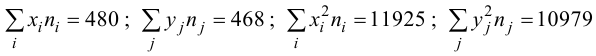 и заносим их в таблицу. Вычислим
и заносим их в таблицу. Вычислим
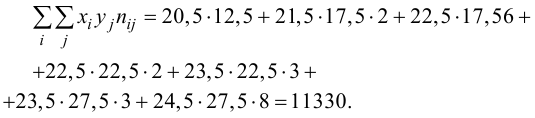
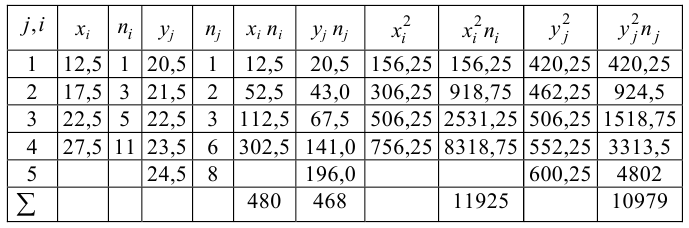
Подставляя полученные значения сумм в (8), найдем выборочный коэффициент корреляции
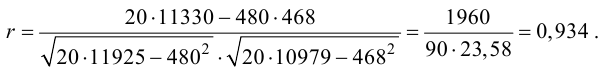
Проверим значимость  на уровне
на уровне  Для этого вычислим статистику
Для этого вычислим статистику
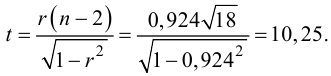
По таблице распределения П6 Стьюдента  находим критическое значение
находим критическое значение 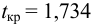 Так как
Так как 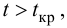 то считаем
то считаем 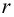 значимым.
значимым.
Пример:
Для данных табл. 13 найти корреляционное отношение 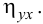
Для вычисления эмпирического корреляционного отношения найдем групповые средние 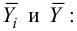
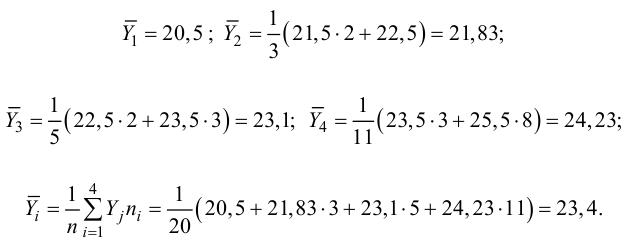
Тогда
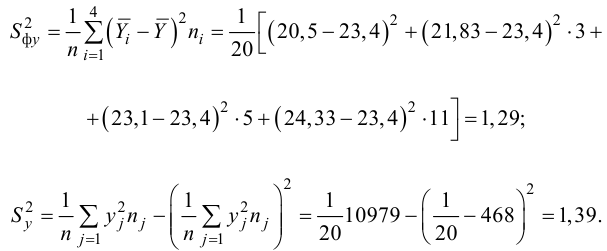
Вычисляем корреляционное отношение
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Статистическая проверка гипотез
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
- Регрессионный анализ
Доверительный интервал для коэффициента корреляции
17 авг. 2022 г.
читать 2 мин
Доверительный интервал для коэффициента корреляции — это диапазон значений, который может содержать коэффициент корреляции совокупности с определенным уровнем достоверности.
В этом руководстве объясняется следующее:
- Мотивация для создания этого типа доверительного интервала.
- Формула для создания этого типа доверительного интервала.
- Пример того, как создать этот тип доверительного интервала.
- Как интерпретировать этот тип доверительного интервала.
Доверительный интервал для коэффициента корреляции: мотивация
Причина создания доверительного интервала для коэффициента корреляции состоит в том, чтобы зафиксировать нашу неопределенность при оценке коэффициента корреляции совокупности.
Например, предположим, что мы хотим оценить коэффициент корреляции между ростом и весом жителей определенного округа. Поскольку в округе проживают тысячи жителей, было бы слишком дорого и долго собирать информацию о росте и весе каждого жителя.
Вместо этого мы могли бы выбрать простую случайную выборку жителей и просто собрать информацию о них.
Поскольку мы выбираем случайную выборку жителей, нет гарантии, что коэффициент корреляции между ростом и весом для этих жителей в выборке будет точно соответствовать коэффициенту корреляции в большей совокупности.
Итак, чтобы зафиксировать эту неопределенность, мы можем создать доверительный интервал, содержащий диапазон значений, которые, вероятно, содержат истинный коэффициент корреляции между ростом и весом жителей этого округа.
Доверительный интервал для коэффициента корреляции: формула
Мы используем следующие шаги для расчета доверительного интервала для коэффициента корреляции совокупности на основе размера выборки n и коэффициента корреляции выборки r .
Шаг 1: Выполните преобразование Фишера.
Пусть z r = ln((1+r)/(1-r))/2
Шаг 2: Найдите верхнюю и нижнюю границы журнала.
Пусть L = z r – (z 1-α/2 /√ n-3 )
Пусть U = z r + (z 1-α/2 /√ n-3 )
Шаг 3: Найдите доверительный интервал.
Окончательный доверительный интервал можно найти по следующей формуле:
Доверительный интервал = [(e 2L -1)/(e 2L +1), (e 2U -1)/(e 2U +1)]
Доверительный интервал для коэффициента корреляции: пример
Предположим, мы хотим оценить коэффициент корреляции между ростом и весом жителей определенного округа. Выбираем случайную выборку из 30 жителей и находим следующую информацию:
- Размер выборки n = 30
- Коэффициент корреляции между ростом и весом r = 0,56.
Вот как найти 95% доверительный интервал для коэффициента корреляции населения:
Шаг 1: Выполните преобразование Фишера.
Пусть z r = ln((1+r)/(1-r))/2 = ln((1+0,56)/(1-0,56))/2 = 0,6328
Шаг 2: Найдите верхнюю и нижнюю границы журнала.
Пусть L = z r – (z 1-α/2 /√ n-3 ) = 0,6328 – (1,96 /√ 30-3 ) = 0,2556
Пусть U = z r + (z 1-α/2 /√ n-3 ) = 0,6328 + (1,96 /√ 30-3 ) = 1,01
Шаг 3: Найдите доверительный интервал.
Доверительный интервал = [(e 2L -1)/(e 2L +1), (e 2U -1)/(e 2U +1)]
Доверительный интервал = [(e 2 (0,2556) -1)/(e 2 (0,2556) +1), (e 2 (1,01) -1)/(e 2 (1,01) +1)] = [0,2502 , .7658]
Примечание. Этот доверительный интервал также можно найти с помощью калькулятора доверительного интервала для коэффициента корреляции .
Доверительный интервал для коэффициента корреляции: интерпретация
То, как мы интерпретируем доверительный интервал, выглядит следующим образом:
Существует вероятность 95%, что доверительный интервал [0,2502, 0,7658] содержит истинный коэффициент популяционной корреляции между ростом и весом жителей этого округа.
Другой способ сказать то же самое состоит в том, что существует только 5% вероятность того, что истинный коэффициент корреляции населения находится за пределами 95% доверительного интервала.
То есть существует только 5% вероятность того, что истинный коэффициент популяционной корреляции между ростом и весом жителей этого округа меньше 0,2502 или больше 0,7658.