- Авторы
- Резюме
- Файлы
- Ключевые слова
- Литература
Карташев Е.А.
1
Царегородцев А.Л.
1
1 АУ Ханты-Мансийского автономного округа — Югры «Югорский научно-исследовательский институт информационных технологий»
В настоящее время в нашем динамично развивающемся информационном мире особую значимость приобретает способность принимать своевременные и правильные решения, которые невозможны без сбора, обработки, хранения, анализа большого объема информации и предоставления результатов их обработки пользователю. Одной из таких задач является оперативное выявление сайтов в сети Интернет, содержащих информацию, распространение которой в Российской Федерации запрещено. Перечень данной информации представлен в ч. 2 ст. 15.1 Федерального закона от 27.07.2006 № 149-ФЗ «Об информации, информационных технологиях и о защите информации». В данной статье рассмотрено построение информационно-аналитической системы, предназначенной для оперативного поиска информации в сети Интернет, распространение которой в Российской Федерации запрещено. Предложен подход к построению информационных систем, осуществляющих поиск информации в сетях общего пользования и обработку большого объема разнородных неструктурированных данных, которые представлены в различных форматах: текст, содержащий фрагменты из нескольких документов; аудио- и видеозаписи; изображения (фотографии и рисунки).
анализ данных
информационно-поисковые системы
неструктурированные данные
загрузка данных с сайтов сети Интернет
1. Бериков В.С., Лбов Г.С. Современные тенденции в кластерном анализе // Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному направлению «Информационно-телекоммуникационные системы». – 2008. – 26 с.
2. Ерохин Г.Н., Дружинин В.А., Царегородцев А.Л., Махнева Т.В., Огородников И.Н., Карташев Е.А. Телемедицина отложенных консультаций на примере северных регионов // Информационно-измерительные и управляющие системы. – 2009. – Т. 7. – № 12. – С. 49–53.
3. Зеленков Ю.Г., Сегалович И.В. Сравнительный анализ методов определения нечетких дубликатов для WEB-документов // Электронные библиотеки: перспективные методы и технологии, электронные коллекции: труды 9-й Всероссийской научной конференции RCDL’2007: Сб. работ участников конкурса. – Т. 1. – Переславль- Залесский: «Университет города Переславля», 2007. – С. 166–174.
4. Карташев Е.А., Самков Л.М. Онлайновая информационно-аналитическая система мониторинга индикаторов жизнеобеспечения территориальных объектов Управление большими системами: сборник трудов. – 2009. – № 24. – С. 112–129.
5. Макунин, Алексей Анатольевич. Технология построения модульных автоматизированных информационных систем для сложных предметных областей и ее применение на примере информационной поддержки системы муниципального заказа органов местного самоуправления: дис. … канд. техн. наук: 05.13.11. – Томск, 2005. – 228 с.
В настоящее время в нашем динамично развивающемся информационном мире особую значимость приобретает способность принимать своевременные и правильные решения, которые невозможны без сбора, обработки, хранения, анализа большого объема информации и предоставления результатов их обработки пользователю.
Одной из таких задач является оперативное выявление сайтов в сети Интернет, содержащих информацию, распространение которой в Российской Федерации запрещено. Перечень данной информации представлен в ч. 2 ст. 15.1 Федерального закона от 27.07.2006 № 149-ФЗ «Об информации, информационных технологиях и о защите информации». Зачастую такая информация представлена на сайтах в сети Интернет, которые могут существенно различаться как по использующимся в них технологиям, так и по их функциональности. В свою очередь информация не структурирована и может быть представлена в различных форматах: текст, содержащий фрагменты из нескольких документов; аудио- и видеозаписи; изображения (фотографии и рисунки).
На рынке существует ряд информационных систем, осуществляющих подобную обработку данных и применяемых в других сферах, но информация об их структуре и применяемых методах обработки данных не раскрывается. Зачастую они предоставляются по технологии SaaS (англ. software as a service), что неприемлемо с учетом специфики обрабатываемых данных.
Цель данной работы – предложить структуру информационной системы, обеспечивающей возможность оперативного получения неструктурированной информации с большого количества различных сайтов в сети Интернет и ее хранения для последующей обработки, при этом должна предусматриваться возможность увеличения объема обрабатываемых данных за счет увеличения количества применяемого оборудования (горизонтальное масштабирование) и использование невысокопроизводительного серверного оборудования.
Разработка автоматизированной информационной системы поиска и анализа информации в сети Интернет (далее АИС Поиск) осуществлялась в Югорском научно-исследовательском институте информационных технологий и предназначена: для взаимодействия с сайтами в сети Интернет; хранения и анализа собранной информации; предоставления результатов обработки информации в виде отчетов пользователю.
Взаимодействие с сайтами в сети Интернет направлено на сбор с них исходной информации, предусматривает работу в режиме запрос – ответ по следующим направлениям: поиск требуемой информации на сайте сети Интернет; загрузка найденной информации в АИС Поиск; актуализация информации, хранящейся в АИС Поиск, за счет сравнения с версией [3], расположенной на сайте сети Интернет (выполняется через определенный интервал времени, определяемый с учетом обновления информации).
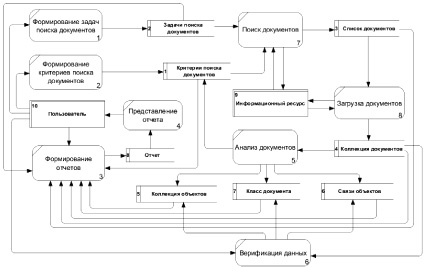
Контекстная диаграмма потоков данных АИС Поиск
Хранение собранной информации с сайтов в сети Интернет предусматривает множество точек входа для сбора и обработки информации, при этом каждая из них может собирать и обрабатывать данные по своим уникальным правилам.
На этапе проектирования были разработаны диаграммы потоков данных, описывающие основные процессы АИС Поиск и потоки данных, циркулирующих в системе. На рисунке представлена контекстная диаграмма потоков данных АИС Поиск.
Рассмотрим процессы контекстной диаграммы подробнее.
1. Формирование критериев поиска документов (ключевые слова, тематические фразы, поисковые запросы, образцы изображений, фрагменты аудио- и видеозаписей) – определяются требования к содержанию документов, которые должны быть найдены на информационных ресурсах, расположенных в сети Интернет, и загружены в базу данных. Первоначальное наполнение осуществляется оператором, в последующем уточняется по результатам анализа документов.
2. Формирование задач поиска документов – определяется режим поиска документов на информационных ресурсах с учетом имеющихся возможностей, периодичности обновления информации и приоритетов пользователя. Формируется в виде задачи, для которой определяется: время запуска, информационные ресурсы, критерии поиска документов.
3. Поиск документов – обеспечивает выполнение задач по поиску документов: периодическая проверка наличия требующих запуска задач поиска документов, выполнение задачи поиска документов в рамках которой по количеству установленных критериев поиска документов и информационных ресурсов выполняется набор действий:
а) формирование запроса на получение данных к информационному ресурсу на основе определенных критериев поиска документов и его синтаксиса;
б) направление запроса на получение данных в информационный ресурс и ожидание ответа;
в) обработка ответа информационного ресурса (запись ссылок на найденные документы в базу данных).
4. Загрузка документов – обеспечивает загрузку документа по найденной ссылке: проверка доступности документа по найденной ссылке; сравнение загруженного документа с предыдущей версией, при ее наличии (проверка на наличие изменений) в базе данных; запись загруженного документа в базу данных.
5. Анализ документов – обеспечивает автоматическую обработку загруженных документов: извлечение объектов из документа (структурированные данные: ФИО, должности, название территорий и веществ, контактная информация, события и т.д.); определение характера связи для выявленных объектов: объект – субъект, негатив – позитив и т.д.; расчет вероятности отнесения документа к различным группам документов, ранее определенных пользователем (классификация документа); выявление похожих документов (с использованием методов классификации объектов по группам за счет выявления наперед неизвестных общих признаков (введен в 1939 году Robert Tryon) [1]); уточнение критериев поиска документов на основе ранее классифицированных и кластеризованных документов.
6. Формирование отчетов – подготовка данных для отображения пользователю (выполнение операций, которые не могут быть выполнены за время ожидания пользователем отклика АИС Поиск).
7. Представление отчетов – представление данных в виде отчетов на основе определенных шаблонов с учетом предпочтений пользователя, при этом ему предоставляется возможность установки фильтра для отбора данных в него включаемых.
8. Верификация данных – подтверждаются пользователем результаты анализа документов: классификация, извлеченные объекты, установленные связи.
По результатам изучения опыта построения подобных систем, в том числе представленных в [2, 4], была выбрана модульная архитектура системы. Использование модульного подхода в качестве основы для такого инструментария позволяет не только просто строить сложные приложения, собирая их из «кирпичиков», но и обеспечивать их взаимозаменяемость для доработки программного обеспечения и расширения возможностей информационных систем. Основные преимущества модульной архитектуры этим не ограничиваются. Также к ключевым особенностям выбранного подхода к построению АИС Поиск можно отнести возможность выборочной ее компоновки, многократное использование однажды написанного кода и разработанных классов [5].
В общем виде структура АИС Поиск состоит из следующих модулей:
– База данных (совокупность средств для обеспечения хранения и доступа к найденным данным).
– Интерфейс пользователя (предоставляет инструменты пользователю для просмотра имеющихся данных и результатов их обработки, а также по управлению работой каждого из модулей).
– Подсистема анализа (осуществляет обработку (классификация, определение объектов и связей) найденных данных).
– Подсистема сбора данных (реализует заданный пользователем алгоритм работы Модулей взаимодействия (запуск, формирование параметров) и обеспечивает загрузку получаемых от них данных в Базу данных).
– Модуль взаимодействия (обеспечивает получение данных с определенного информационного ресурса в соответствии с установленными параметрами).
Все эти собранные неструктурированные данные требуется быстро анализировать, что в свою очередь невозможно без соответствующей организации хранения этих данных. Тенденции последних лет показывают, что для хранения неструктурированных данных используются современные СУБД, сочетающие в себе гибкость модели хранилища документов и строгость и простоту реляционной модели.
Например, в СУБД PostreSQL 9.2 появилась поддержка типа данных JSON (JavaScript Object Notation), а в 9.3 добавились функции обработки значений в нём. Этот же тип данных теперь поддерживается и в MySQL начиная с версии 5.7.8. Аналогичный функционал есть и в СУБД Oracle, MSSQL.
Существует несколько подходов к хранению неструктурированных данных в информационных системах:
– непосредственно в базе данных, при этом большинство современных СУБД предусматривают для этого специализированный тип данных: JSONB в PostgreSQL, CLOB в Oracle и т.д.;
– вне базы данных (в виде файлов в соответствующих хранилищах), при этом в базе данных хранятся только ссылки на них. Основными недостатками данного варианта являются сложности с администрированием, обеспечением доступности и целостности данных. В свою очередь преимуществом данного подхода является возможность использования стандартных приложений по их обработке (просмотр), сокращение общего объема базы данных (не требуется выделять большой объем дискового пространства в одном месте), данные могут храниться на большом количестве различных серверов с небольшим объемом дискового пространства. На сегодняшний день данное направление активно поддерживается разработчиками СУБД и ведутся работы по устранению указанных недостатков, в частности в MS SQL Server 2012 появились таблицы FileTable для работы с файлами, а в Oracle – параметр SecureFiles для типа данных LOB.
Принимая во внимание, что наибольшую часть (объем) будут занимать неструктурированные данные, доступ к которым нужен будет эпизодически (на этапе загрузки для извлечения метаданных и несколько раз для демонстрации результатов пользователю), была предложена следующая структура: Файловый сервер – Драйвер доступа – СУБД.
В качестве файловых серверов было принято решение использовать сервера под управлением свободно распространяемой операционной системы Linux (Debian, или Astra Linux), а в качестве СУБД Postgres, так как она: свободно распространяемая, имеет развитые инструменты для полнотекстового поиска и может быть сертифицирована по требованиям безопасности информации например в составе операционной системы Astra Linux.
В соответствии с предложенным подходом нами в Югорском НИИ информационных технологий была осуществлена реализация АИС Поиск, которая используется компетентными ведомствами Ханты-Мансийского автономного округа – Югры для поиска доменных имен, указателей страниц сайтов в информационно-телекоммуникационной сети Интернет и сетевых адресов, позволяющих идентифицировать сайты в информационно-телекоммуникационной сети Интернет, содержащие информацию, распространение которой в Российской Федерации запрещено.
В настоящее время было обработано более 75 тыс. ссылок, загружено в базу данных более 21 тыс. уникальных документов. Для 922 документов было определено с высокой долей вероятности, что они содержат информацию, распространение которой в Российской Федерации запрещено, более 75 % из них были включены в соответствующий реестр, который ведется Роскомнадзором в соответствии с ч. 3 ст. 15.1 Федерального закона от 27.07.2006 № 149-ФЗ «Об информации, информационных технологиях и о защите информации».
В ходе опытной эксплуатации АИС Поиск получены положительные оценки от конечных пользователей, также ими отмечается предсказуемость появления документов в базе данных в зависимости от сформированных критериев поиска документов (результаты аналогичны полученным при ручном поиске) и снижение трудоемкости. По результатам также было рекомендовано ввести АИС Поиск в промышленную эксплуатацию.
В дальнейшем планируется проведение работ по повышению эффективности работы пользователей с АИС Поиск, в частности за счет внесения изменений в интерфейс пользователя, сокращению время отклика системы на действия пользователя за счет предварительной подготовки данных и повышению скорости работы алгоритмов обработки данных. Планируется также проведение работ по сравнению результатов классификации документов с использованием различных алгоритмов и методов.
Библиографическая ссылка
Карташев Е.А., Царегородцев А.Л. АВТОМАТИЗИРОВАННАЯ ИНФОРМАЦИОННАЯ СИСТЕМА ПОИСКА И АНАЛИЗА ИНФОРМАЦИИ В СЕТИ ИНТЕРНЕТ // Фундаментальные исследования. – 2016. – № 10-2.
– С. 296-300;
URL: https://fundamental-research.ru/ru/article/view?id=40848 (дата обращения: 29.05.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
Компании
всего мира широко используют сеть
Internet — эту всемирную информа-ционную
супермагистраль для поиска и получения
информации любого вида. В се-ти Internet
имеются тысячи баз данных и десятки
навигационных систем. Для об-легчения
и ускорения поиска необходимой информации
используются вспомога-тельные программы,
интегрированные в структуру Internet и
составляющие ядро автоматизированных
систем поиска и получения информации.
Сеть
Internet работает с тремя основными системами
поиска информации — Gopher, WAIS и WWW.
Гипертекстовая
система Gopher.
Это
достаточно известное и распространенное
средство поиска информации в сети
Internet, позволяющее находить информацию
по ключевым словам и фразам. При работе
с Gopher пользователю предлагается пройти
сквозь ряд вложенных меню, из которых
доступны файлы различных типов. Будучи
распределенной системой экспорта
структурированной информации. Gopher
является сервисом прямого дос-тупа и
требует, чтобы и сервер, и клиент были
полноценно подключены к Internet.
Система
Gopher позволяет получать информацию без
указания имен и адресов авторов.
Пользователь просто сообщает системе,
что ему нужно, и система находит
необходимые д
В
настоящее время в Internet имеется свыше
2000 Gopher-систем, часть из которых
узкоспециализированные, а часть содержит
более разностороннюю информацию. Это
усложняет поиск информации. В случае
возникновения затруднений можно
воспользоваться службами ARCHTE и VERONICA.
Служба VERONICA осуществ-ляет поиск более
чем в 500 системах Gopher, освобождая
пользователей от необ-ходимости
просматривать соответствующие меню
вручную, а служба ARCHTE ав-томатизирует
навигацию и поиск файлов в FTP-серверах.
Система
WAIS.
Это
информационная система широкого профиля,
представляющая собой ком-плект программ,
предназначенных для индексирования
больших объемов неструк-турированной
( как правило, просто текстовой) информации,
поиска по таким мате-риалам и извлечения
из них запрашиваемых данных. Эти функции
выполняются с помощью программ
индексирования, программ локального
поиска по полученным индексам, а также
серверных и клиентских программ,
взаимодействующих между собой по
специальному протоколу Z39.50.
Задача
поиска данных в больших объемах
неструктурированной информации весьма
нетривиальна, пока не существует
общепринятого ее решения. В системе
WAIS реализован приемлемый вариант решения
этой задачи, поэтому она получи-ла
достаточную известность как один из
сервисов Internet. Однако в последнее время
эта система самостоятельно почти не
используется, а во многих случаях
применяется как вспомогательное
средство, например, для индексирования
доку-ментов, хранящихся на WWW-сервере.
В сети Internet имеется более 200 WAIS-библиотек,
в которых большая часть материалов
относится к области исследова-ний и
компьютерных наук.
Система
WWW
(World
Wide Web — всемирная паутина). WWW — самое
популярное и удобное сред-ство работы
с информацией. Больше половины потока
данных в Internet приходит-ся на долю WWW.
Количество серверов WWW сегодня превышает
30 тысяч. WWW — гипертекстовая, гипермедийная,
распределенная, интегрированная,
глобальная децентрализованная
информационная система, реализующая
самую передовую и массовую технологию.
Это сервис прямого доступа, требующий
полноценного под-ключения к Internet. WWW
работает по принципу клиент-серверы.
Имеется множе-ство серверов, которые
по запросу клиента представляют ему
гипермедийный до-кумент, состоящий из
частей с разнообразным представлением
информации (текст, звук, графика,
трехмерные объекты и т.д.). Программные
средства WWW являются универсальными
для различных сервисов Internet, а сама
система играет интегрирующую роль.
Соединение между клиентом и сервером
WWW одноразовое: получив запрос от клиента
и выдав ему документ, сервер прерывает
связь.
В
Internet реализуются две стороны поиска
информации, разные по методам, но единые
в целях: каталоги и поисковые серверы.
Условно можно сказать, что ката-логи —
средства сфокусированного поиска
информации, а поисковые серверы —
рас-сеянного. Использование этих средств
позволяет быстро и эффективно находить
необходимую информацию в глобальной
сети.
Поисковые
серверы
Поисковые
серверы — это выделенные компьютеры,
которые, автоматически про-сматривая
все ресурсы сети Internet, могут найти
запрашиваемые ресурсы и про-индексировать
их содержание. Пользователь передает
поисковому серверу фразу или набор
ключевых слов, описывающих интересующую
его тему. Выполняя такой запрос, сервер
сообщает пользователю список
соответствующих ресурсов. В сети Internet
имеется множество поисковых серверов,
охватывающих практически все доступные
ресурсы. При этом разные серверы
охватывают различные, частично
перекрывающиеся,’ области информации
в сети. Они используют различающиеся
методы индексирования документов и
способы оценки значимости слов в них.
Имеются специализированные серверы
поиска по отдельным типам ресурсов сети
и универсальные, охватывающие все виды
сервисов.
Каталоги
и поисковые системы Internet
Со
времени зарождения Internet, люди ищут пути
упорядочения огромного количе-ства
доступных в Сети данных. Для решения
этой проблемы предназначены спе-циальные
поисковые системы и каталоги.
Существует
два типа поисковых систем: одни работают
с индексами (ссылками), другие — с
каталогами (классификаторами). Используемые
при этом технологии очень разнятся.
Такие системы, как AltaVista и InfoSeek, получают
информацию от каждого конкретного узла,
индексируют ее, а всю найденную информацию
(URL-адрес, заголовок, текст) добавляют к
своим базам данных. Другие (eXcite и
Web-Crawler) имеют механизмы, выискивающие
исключительно узлы с высоким трафи-ком,
добавляющие их к своим архивам и
классифицирующие по степени убывания
популярности. Системы, основанные на
каталогах (Point, Magellan и Yahoo!), обыч-но
полагаются на людей-редакторов, которые
организуют соответствующие поис-ковые
категории, устанавливают перекрестные
ссылки между ними и занимаются заполнением
баз данных.
В
то время как индексы постоянно
пересматриваются и обновляются, поскольку
их автоматизированные механизмы сбора
информации собирают и откладывают
но-вую информацию, — актуальность
каталогов может нарушаться и зависит
от рас-торопности хозяев поисковой
системы. Главным условием успешного
поиска явля-ется использование правильного
инструмента для работы.
Системы,
основанные на каталогах, лучше подходят
в тех случаях, когда вам надо осуществить
быстрый поиск каких-либо общих тем.
Небольшие размеры и создан-ная людьми
система упорядочения материала делают
их особенно пригодными для быстрого
нахождения качественной информации.
Общий поиск в системах Point или Magellan дает
только узлы, наиболее часто посещаемые
в Сети. Вообще в индексных системах
более изощренные программные агенты и
большие базы данных, что делает их
полезными для исчерпывающих поисков,
сложных запросов или для локализации
неясной информации. Это достоинство,
однако, становится недостатком, когда
производится тематический поиск. Хотя
большинство таких сис-тем облегчает
восприятие чрезмерного количества
информации, представляя ре-зультаты
поиска согласно математически
установленному порядку (например, ссылки
с наиболее высокими номерами соответствия
ключевых слов могут распо-лагаться
выше), но запаситесь терпением, «отсеивая»
ссылки, не относящиеся к делу или
недостаточно близкие по теме.
Важным
элементом успешного поиска является
правильно сформулированный за-прос.
Это означает, что иногда требуется
применение операторов, близких к буле-вым
(AND, OR, NOT, NEAR), знаков пунктуации (например,
кавычек, значков «*» или «$») и
чувствительности к регистру (для имен
собственных, заголовков и аббревиа-тур).
Каждая поисковая система использует
различные вариации этих простых
ат-рибутов запроса поиска. Поэтому почти
каждая предлагает область справки или
ответов на наиболее часто встречающиеся
вопросы. Если в первый раз не получен
нужный результат, можете изменить
формулировку поиска и начать с самого
нача-ла. Ни одна из этих систем не может
идеально подходить всем. Хотя каждая
из них позволяет достаточно быстро
выдавать результаты, некоторые имеют
более про-стые интерфейсы, более сильный
инструментарий или более полные базы
данных.
AltaVista
fhttD://altavista.digital.com)
AltaVista
обеспечивает наиболее тщательный поиск
среди всех представленных здесь систем.
Интерфейс AltaVista легок в использовании,
а раскрывающиеся меню помогают определить
предмет вашего поиска. Опция Advanced Search
позволяет вам настраивать запросы
определением булевых операторов,
проведением поис-ков с учетом регистров
символов, ограничением давности ссьшок,
использованием масок и т.д. Однако,
несмотря на свои достоинства, AltaVista не
предлагает индек-сированного указателя
для простого просмотра, результаты
поиска не ранжирова-ны и не организованы,
так что часто богатство предоставляемой
информации при-водит к большой трате
времени. В целом, способность AltaVista
распознавать за-просы на естественном
языке является ее большим преимуществом.
Просеивая результаты, полученные
AltaVista, вы можете потратить больше времени,
чем при использовании других поисковых
систем, но для исчерпывающих поисков
самых дальних «углов» WWW AltaVista
незаменима.
eXcite
ftittp: //www.excite.com)
Сильной
стороной eXcite является ее интерфейс и
некоторые специальные воз-можности.
При помощи этой системы можно вести
поиск не только в Web и Usenet, но и в базах
данных eXcite Reviews и классификаторах
Internet. Однако, поскольку eXcite поддерживает
поиски только по простой фразе или
ключевому слову, при необходимости
сложного поиска могут возникнуть
трудности. eXcite выдает прием-лемое число
качественных ссылок, особенно для
основных тем, хотя это у нее по-лучается
не лучше, чем у других поисковых систем.
HotBot
(http://www.hotbot.com)
Поисковая
система, созданная HotWired и усовершенствованная
совместно с Ink-tomi. Данная система
отказывается от «полносервисного»
подхода, свойственного, например, Lycos,
и вместо этого предлагает мощный, без
всяких излишеств интер-фейс. Соответствующие
меню позволяют искать по всем словам,
по любому из слов, по фразе, по URL-адресу,
использовать подмножество булевых
операторов, осуществлять поиск внутри
какой-нибудь области, ограничивать ваш
поиск рядом специфических данных и т.д.
Полученные ссылки располагаются в ряд
и представ-ляются с коротким текстовым
резюме. HotBot находит почти так же много
ссылок, как Lycos и AltaVista, но по качеству
ссылок уступает им.
InfoSeek
Guide (http://guide.infoseek.com)
В
отличие от многих других средств поиска,
которые вынуждают вас обращаться к
непривычным булевым операторам, InfoSeek
предлагает понятный дружественный
интерфейс, позволяющий вам не терзаться
мыслью о том, как сформулировать во-прос.
Наряду с этим, InfoSeek предлагает самые
лучшие подкатегории поиска, по-зволяя
вам просматривать узлы Web, Usenet, адреса
e-mail, каталоги компаний и т.д. Предметом
гордости InfoSeek также являются удобные
системы «горячих» ссы-лок, такие
как Big Yellow и Personalized News (настраиваемые
страницы новостей). Качество получаемых
ссьшок в InfoSeek обычно выше, чем в других
поисковых сис-темах. Большинство из них
близки к заданной теме, актуальны и
четко организова-ны. Если бы не ограниченный
размер базы данных, InfoSeek могла бы легко
обойти другие средства поиска.
Lycos
(http;//www.lvcos.com)
С
этой системой поиска вам удастся получить
результаты, которые сопоставимы с
показателями AltaVista. Lycos оперирует со
множеством способов построения за-просов,
позволяя вам задавать область поиска,
выбирать число ссылок, приводи-мых на
страницу, меру близости запросу и
получать результаты в стандартном,
общем или детализированном формате.
Lycos тесно связан с системой Point (см.
далее), через нее он дает ссылки на
новости и некоторые другае ресурсы. В
Lycos не предусмотрена возможность работы
с естественным языком, но в остальных
случаях эта поисковая система дает
большое число подходящих ссылок.
Magellan
(http://www.mckinley.com)
Хотя
Magellan предлагает оригинальное
отредактированное содержимое и архив,
открытый для поиска Web-страниц, ее самая
важная черта — это индексы про-смотренных
и оцененных документов, которые также
являются частью системы eX-cite. Просмотренные
ссылки классифицируются с точки зрения
их распространен-ности, легкости в
использовании и общей «сетевой
привлекательности»; им при-сваивается
от одной до четырех звезд рейтинга.
Материалы, которые считаются «безопасными»
для всех пользователей, изображены
пиктограммой «Светофор» с горящим
зеленым светом. Magellan хороша для легкого
тематического просмотра, равно как и
для поисков во всем Internet, которые вы
можете провести исключи-тельно по
проверенным узлам или по всей
неклассифицированной базе данных.
Однако лучше всего не применять Magellan
для общих поисков, а использовать ее
для нахождения качественных ссылок,
подходящих для конкретных целей.
OpenText
(http://www.opentext.com)
Как
и HotBot, OpenText не использует указатели,
составленные редакторами, и дру-гие
несвойственные ему функции, а опирается
только на возможности своего поис-кового
механизма. Он предоставляет вам опции,
управляющие простым поиском по слову
(словам) или фразе. Простой поиск в
OpenText, наравне с InfoSeek и Lycos, дает достаточно
качественные результаты. Но так как
OpenText ищет по целой связке слов, а не по
отдельным ключевым словам, он сам
попадает впросак при сложном запросе
или при запросе на естественном языке.
Однако, если вы готовы потратить некоторое
время на изучение инструментария Power
Search, OpenText покорит вас своей гибкостью.
Point
(http://www.pointcom.com)
В
дополнение к средствам поиска Lycos база
данных Point содержит сообщения только о
«наиболее посещаемых 5% узлов Web».
Ссылки подобраны по качеству содержания,
представления и опыту использования.
Наряду с каталогом. Point предлагает
еженедельный список 10 самых популярных
узлов, ссылки на новую и актуальную
информацию и ссылки для Lycos. Эта
специфическая база данных не предназначена
для обычных поисков информации в
Internet. Функция поиска в Point по ключевому
слову ищет ссылки внутри текста документа,
а не по самим ссылкам. Это может исказить
результаты из-за сделанных экспромтом
ремарок, внесенных редакторами службы
Point. Ясно, что Point покажет более высокие
результаты при просмотре по категориям.
Подобно редакторам, работающим под
системой Magel-lan, рецензенты Point выполняют
неоценимую работу, отделяя «зерна от
плевел», так что вам не придется
тратить на это свое время.
WebCrawler
(http://www.webcrawler.com)
Интерфейс
WebCrawler предлагает мощный механизм поиска,
способный опериро-вать с большинством
булевых операторов. Подобно eXcite и
Magellan, WebCrawler позволяет вам просматривать
документы, размещенные и ранжированные
по кате-гориям (например: Life, Education, News и
т.д.). Интерфейс WebCrawler прост в ис-пользовании
и работает достаточно результативно,
находя адреса популярных уз-лов.
Yahoo!
(http://www.vahoo.com)
Yahoo!
является т.н. «индексированным
каталогом Internet». В отличие от других
поисковых систем, прибегающих для сбора
ссылок к помощи различного рода
ав-томатических агентов, Yahoo! строится
вручную, т.е. обширный штат сотрудников
постоянно работает с Web, выявляет новые
документы (или записывает те, кото-рые
предоставляются Web-администраторами),
составляет резюме об их содер-жимом и
относит их к какой-либо категории. При
просмотре Yahoo! ищет ключевые слова или
связку слов в заголовках документов, в
названиях категорий и текстовых резюме.
В параметрах поиска могут использоваться
булевы операторы, адреса электронной
почты или Usenet. Когда Yahoo! не может найти
данные в своей базе данных, производится
обращение к полнотекстовой базе данных
AltaVista. Простой интерфейс, большая база
накопленной информации. удачный и
обширный клас-сификатор, — все это
создало Yahoo! репутацию поисковой системы
высокого ка-чества.
Соседние файлы в папке Фрегат
- #
22.03.2015456.66 Кб475.jpg
- #
22.03.2015741.7 Кб476.jpg
- #
22.03.2015423.92 Кб477.jpg
- #
- #
- #
- #
- #
- #
- #
Тема 2.4
Поиск
и передача информации с Использованием компьютера.
Программные
поисковые системы.
Поиск информации — процесс выявления в
массиве информации записей, удовлетворяющих заранее определенному условию
поиска или запросу.
Запрос — это формализованный способ
выражения информационных потребностей пользователем системы. Для выражения
информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность,
которая хранится в базе автоматизированной системы поиска. Несмотря на то, что
наиболее распространенным объектом запроса является текстовый документ, не существует никаких принципиальных
ограничений. В частности, возможен поиск изображений, музыки и другоймультимедиа информации. Процесс занесения объектов поиска в ИПС
называется индексацией. Далеко не всегда ИПС хранит точную
копию объекта, нередко вместо неё хранится суррогат.
Информацио́нный по́иск (англ. information retrieval) —
процесс поиска неструктурированной документальной информации,
удовлетворяющей информационные потребности[1], и наука об этом поиске.
Термин «информационный поиск» был
впервые введён Кельвином Муэрсом в 1948 в его докторской
диссертации, опубликован и употребляется в литературе с 1950.
Сначала системы автоматизированного ИП,
или информационно-поисковые системы (ИПС), использовались лишь
для поиска научной информации и литературы. Многие университеты и публичные библиотеки стали использовать ИПС для обеспечения доступа к книгам,
журналам и другим документам. Широкое распространение ИПС получили с появлением
сети Интернет и развитием Всемирной паутины. У русскоязычных пользователей
наибольшей[2] популярностью
пользуются поисковые системы Яндекс, Google и Mail.Ru.
Центральная задача ИП — помочь
пользователю удовлетворить его информационную потребность. Так как описать
информационные потребности пользователя технически непросто, они формулируются
как некоторый запрос, представляющий из себя набор ключевых слов,
характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой
началось развитие этой области, — это поиск документов, удовлетворяющих
запросу, в рамках некоторой статической коллекции документов. Но список задач
ИП постоянно расширяется и теперь включает:
Виды поиска
Полнотекстовый поиск — поиск по всему содержимому
документа. Пример полнотекстового поиска — любой интернет-поисковик,
например www.yandex.ru,www.google.com. Как правило, полнотекстовый поиск для
ускорения поиска использует предварительно построенные индексы. Наиболее распространенной технологией для индексов
полнотекстового поиска являются инвертированные индексы.
Поиск по метаданным — это поиск по неким атрибутам документа, поддерживаемым
системой — название документа, дата создания, размер, автор
и т. д. Пример поиска по реквизитам — диалог поиска в файловой
системе (например, MS Windows).
Поиск изображений — поиск по содержанию
изображения. Поисковая система распознает содержание фотографии (загружена
пользователем или добавлен URL изображения). В результатах поиска пользователь
получает похожие изображения. Так работают поисковые системы: Polar Rose, Picollator и др.
Методы поиска
Адресный поиск
Процесс поиска документов по чисто формальным
признакам, указанным в запросе.
Для осуществления нужны следующие условия:
1.
Наличие у
документа точного адреса
2.
Обеспечение
строгого порядка расположения документов в запоминающем
устройстве или в хранилище системы.
Адресами документов могут выступать адреса веб-серверов и веб-страниц и элементы библиографической
записи, и адреса хранения
документов в хранилище.
Семантический поиск
Процесс поиска документов по их содержанию.
Условия:
· Перевод содержания документов и
запросов с естественного
языка на информационно-поисковый язык и
составление поисковых
образов документа и запроса.
· Составление поискового описания,
в котором указывается дополнительное условие поиска.
Принципиальная разница между адресным и
семантическим поисками состоит в том, что при адресном поиске документ
рассматривается как объект с точки зрения формы, а при семантическом
поиске — с точки зрения содержания.
Полнотекстовый поиск (англ. Full text searching, фр. Recherche en texte integral) — автоматизированный
документальный поиск, при котором в качестве поискового образа документа
используется его полный текст или существенные части текста.
При семантическом поиске находится множество
документов без указания адресов.
Каталог, картотека.
Библиотека — собрание библиографических
записей без
указания адресов.
Библиографическая запись — наименьшая единица
библиографического списка, состоящая из заголовка и библиографического
описания, одна из формбиблиографической информации. Используется для идентификации документа и осуществления библиографического поиска.
Документальный поиск
Процесс поиска в хранилище
информационно-поисковой системы первичных документов или в базе данных вторичных документов, соответствующих запросу
пользователя.
Два вида документального поиска:
1.
Библиотечный,
направленный на нахождение первичных документов.
2.
Библиографический,
направленный на нахождение сведений о документах, представленных в виде
библиографических записей.
Фактографический поиск
Процесс поиска фактов, соответствующих
информационному запросу.
К фактографическим данным относятся сведения, извлеченные из документов, как
первичных, так и вторичных и получаемые непосредственно из источников их
возникновения.
Различают два вида:
1.
Документально-фактографический,
заключается в поиске в документах фрагментов текста, содержащих факты.
2.
Фактологический
(описание фактов), предполагающий создание новых фактографических описаний в
процессе поиска путем логической переработки найденной фактографической
информации.
Существует много способов оценить насколько
хорошо документы, найденные ИПС, соответствуют запросу. К сожалению, понятие
степени соответствия запроса, или другими словами релевантности, является субъективным понятием, а степень
соответствия зависит от конкретного человека, оценивающего результаты
выполнения запроса.
Релева́нтность (лат. relevo — поднимать,
облегчать) в информационном поиске — семантическое соответствие поискового запроса и поискового
образа документа[1]. В более общем
смысле, одно из наиболее близких понятию качества«релевантности» — «адекватность».
Содержательная релевантность
Соответствие документа информационному запросу,
определяемое неформальным путём[1].
Формальная релевантность
Соответствие, определяемое путём сравнения образа
поискового запроса с поисковым образом документа по определённому алгоритму.
Одним из методов для оценки релевантности
является TF-IDF-метод. Его смысл сводится к тому, что чем больше
локальная частота термина (запроса) в документе (TF) и больше «редкость» (то
есть, чем реже он встречается в других документах) термина в коллекции (IDF),
тем выше вес данного документа по отношению к термину — то есть документ
будет выдаваться раньше в результатах поиска по данному термину.
Пертине́нтность (лат. pertineo — касаюсь, отношусь) —
соответствие найденных информационно-поисковой системой документов информационным
потребностямпользователя, независимо от того, как полно и как точно эта
информационная потребность выражена в тексте информационного запроса. Иначе
говоря, это соотношение объёма полезной информации к общему объёму полученной
информации
Электро́нная библиоте́ка — упорядоченная коллекция
разнородных электронных документов (в том числе книг, журналов), снабженных средствами
навигации и поиска. Может быть веб-сайтом, где постепенно накапливаются различные тексты (чаще литературные, но
также научные и любые другие, вплоть до компьютерных программ) и медиафайлы,
каждый из которых самодостаточен и в любой момент может быть востребован
читателем. Электронные библиотеки могут быть универсальными, стремящимися к
наиболее широкому выбору материала (как Библиотека Максима Мошкова или Либрусек),
и более специализированными, какФундаментальная электронная библиотека или проект Сетевая Словесность, нацеленный на собирание авторов и
типов текста, наиболее ярко заявляющих о себе именно в Интернете.
Электронные библиотеки следует отличать
от смежных структурных типов сайта, особенно литературного. В отличие от литературного журнала, родившегося как тип печатного издания,
но успешно и без принципиальных изменений структуры перебравшегося в Интернет,
электронная библиотека не подразделяется на выпуски и обновляется перманентно
по мере появления новых материалов. В отличие от сайта со свободной публикацией, электронная библиотека, как
правило, подбирается координатором проекта по своему усмотрению и, что гораздо
более важно, не предусматривает создания вокруг публикуемых текстов
коммуникативной среды. При этом в практике отдельных Интернет-проектов могут
возникать и гибридные формы и промежуточные решения: так, открытие в
электронной библиотеке Сетевая Словесность гостевых книг для каждого публикуемого
автора в известной степени вносит в проект элемент формирования коммуникативной
среды, состоящей из авторов и читателей, что для электронных библиотек вообще
нехарактерно.
Поисковые системы.
Поиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска
информации.
Системы, обеспечивающие реализацию подобного поиска информации,
называются поисковыми системами (ПС). В традиционных
технологиях ПС представляют картотеки и каталоги, адресные и иные справочники,
указатели, энциклопедии, справочный аппарат к изданиям и другие материалы.
В 1945 годы американский ученый и инженер В. Буш в статье
«Возможный механизм нашего мышления» впервые широко поставил вопрос о
необходимости механизации информационного поиска. Начиная с 1960 годов,
появляются автоматизированные поисковые системы, работающие с информацией. С
этого периода ведутся интенсивные работы в области формирования и реализации
принципов и методов информационного поиска.
«Поисковые системы» осуществляют поиск среди
документов базы или иных массивов машиночитаемых данных, содержащих заданные
слова.
Электронные ПС с помощью обычных или интеллектуальных терминалов
(ПЭВМ) дают возможность пользователям производить поисковые запросы при помощи
формальных и описывающих содержание элементов и с применением специальных
логических операторов; осуществляют поиск среди документов базы или иных
массивов машиночитаемых данных, содержащих заданные слова. Поисковые системы
позволяют осуществлять только поисковые процедуры и связанные с ними процессы.
Информационно-поисковые системы
ПС с большим набором функций и возможностей обычно входят в состав
СУБД и именуются информационно-поисковыми системами. Они также создаются и
используются для эффективного нахождения пользователями необходимых им данных,
в том числе в Интернете.
Терминологически «информационно-поисковая система»
(англ. «information retrieval system», IRS) — представляет систему,
предназначенную для поиска и хранения информации; пакет программного
обеспечения, реализующий процессы создания, актуализации, хранения и поиска в
информационных базах и банках данных.
Информационно-поисковая система трактуется и как система,
обеспечивающая поиск и отбор необходимых данных на основе
информационно-поискового языка и соответствующих правил поиска, а база
данных — как совокупность средств и методов описания, хранения и
манипулирования данными, облегчающих сбор, накопление и обработку больших
информационных массивов. Организация различных БД отличается видом объектов
данных и отношений между ними.
Функционирование современных ИПС основано на двух предположениях:
1) документы, необходимые пользователю, объединены наличием
некоторого признака или комбинации признаков;
2) пользователь способен указать этот признак.
Оба эти предположения на практике не выполняются, и можно говорить
только о вероятности их выполнения. Поэтому, процесс поиска информации обычно
представляет собой последовательность шагов, приводящих при посредстве системы
к некоторому результату, и позволяющих оценить его полноту. При этом поведение
пользователя, как организующее начало управления процессом поиска, мотивируется
не только информационной потребностью, но и разнообразием стратегий, технологий
и средств, предоставляемых системой.
Пользователь обычно не имеет исчерпывающих знаний об
информационном содержании ресурса, в котором проводит поиск. Оценить
адекватность выражения запроса, как и полноту получаемого результата, он может,
отыскав дополнительные сведения, или так организовав процесс, чтобы часть
результатов поиска могла использоваться для подтверждения или отрицания
адекватности другой части. В то же время, для пользователей-профессионалов
характерна устойчивость тематического профиля. Когда они являются
«информационно-ориентированными», то им свойственно желание и
способность организовать информационное пространство проблемы. Это означает,
что пользователь создаёт по существу новый, «самостоятельный»
проблемно-ориентированный, индивидуально обновляемый и пополняемый ИР,
включающий помимо подборок документов также и метаинформацию, например, словари
специальной терминологии, классификаторы предметных областей, описания ресурсов
и т.д.
Особенность работы пользователя в режиме
«самообслуживания», в контексте задачи автоматизации совокупной
деятельности, означает, что система должна представлять среду, обеспечивающую
поддержку функций потребителя по обработке найденной информации, а также
традиционно относящихся к функциям информационного посредника (интерпретация
запроса, его перевод на информационно-поисковый язык, выбор ИР,
автоматизированный поиск и ручной отбор материалов), но также и такие
«обеспечивающие» функции, как: структурирование информационной
потребности, лексическая адаптация запроса, оценка, систематизация и обработка
результатов поиска, причём на уровне как отдельного документа, так и информационных
ресурсов в целом. Технические возможности, которыми располагает пользователь,
позволяют ему создавать информационный ресурс — формировать массивы,
систематизировать и создавать внешние представления их содержания для
собственного или внешнего использования.
ИПС делятся на: традиционные (ручные, механические,
электромеханические) и автоматизированные (электронные).
Автоматизированные ИПС (АИПС), используют компьютерные
программно-технические средства и технологии и предназначаются для нахождения и
выдачи пользователям информации по заданным критериям. Определяющими для
понимания методов автоматизации поиска являются два следующих фактора:
1) сравниваются не сами объекты, а описания — так называемые
«поисковые образы»;
2) сам процесс является сложным (составным и не одноактным) и обычно
реализуется последовательностью операций.
Данные в АИПС вводятся на основе специально разрабатываемых
форматов ввода. Все сведения об одном объекте в ИПС представляются в виде
систематизированных данных, образующих одну строку таблицы и называются записью.
При этом, если ИПС представляет электронный каталог библиотеки, то любое
библиографическое описание (БО) документа в нём — это одна запись, состоящая из
полей, равных количеству элементов БО. Совокупность записей образует БД,
которая, как правило, хранится в одном файле. Совокупность БД, объединенных
одной СУБД, образует банк данных.
Поскольку АИПС инструмент, используемый человеком при
поиске (а не интеллектуальным автомат для поиска информации
— готовых решений задач основной деятельности), эффективность её использования
зависит от того, насколько хорошо человек знает природу операционных объектов и
свойства инструмента, посредством которого он работает с этими объектами.
Информационный поиск подразумевает использование определённых
стратегий, методов, механизмов и средств. Поведение пользователя,
осуществляющего управление процессом поиска, определяется не только
информационной потребностью, но и инструментальным разнообразием системы —
технологиями и средствами, предоставляемыми системой.
Стратегия поиска — общий план (концепция,
предпочтение, установка) поведения системы или пользователя для выражения и
удовлетворения информационной потребности пользователя, обусловленный как
характером цели и видом поиска, так и системными «стратегическими»
решениями — архитектурой БД, методами и средствами поиска в конкретной АИПС.
Выбор стратегии в общем случае является оптимизационной задачей. На практике в
значительной степени он определяется искусством достижения компромисса между
практическими потребностями и возможностями имеющихся средств.
Метод поиска — совокупность моделей и алгоритмов реализации
отдельных технологических этапов: построения поискового образа запроса (ПОЗ),
отбора документов (сопоставление поисковых образов запросов и документов),
расширения и реформулирования запроса, локализации и оценки выдачи.
Поисковый образ запроса — записанный на ИПЯ текст, выражающий смысловое
содержание информационного запроса и содержащий указания, необходимые для
наиболее эффективного осуществления информационного поиска.
Методы поиска, т.е. выделение подмножества документов,
потенциально содержащих описание решения задачи отбора документов (ОД),
являются отражением процесса нахождения решения и зависят от характера задачи и
предметной области.
Рассматривая поиск как итеративный процесс, методы сокращения пространства
перебора (просматриваемого подмножества) образуют по существу методологическую
основу стратегии поиска и могут быть разделены на следующие классы — методы поиска
в:
1) одном пространстве (обычно, тематическом);
2) иерархически упорядоченном пространстве;
3) альтернативных пространствах;
4) динамическом (изменяющемся в процессе поиска) пространстве.
Реализуемый метод построения ПОЗа должен обеспечивать эффективные
способы построения запроса для достижения целей различного типа.
Механизмы поиска — совокупность реализованных в
системе моделей и алгоритмов процесса формирования выдачи документов в ответ на
поисковый запрос.
Средства поиска, с одной стороны, — взаимозависимый
комплекс информационно-поисковых языков (ИПЯ) и языков определения/управления
данными, обеспечивающий структурные и семантические преобразования объектов
обработки (документов, словарей, совокупностей результатов поиска), а с другой,
— объекты пользовательского интерфейса, обеспечивающие управление
последовательностью выбора операционных объектов конкретной АИПС.
Поисковые технологии — унифицированные (оптимизированные в рамках
конкретной АИПС) последовательности эффективного использования отдельных
средств поиска в процессе взаимодействия пользователя с системой для
устойчивого получения конечного и промежуточных результатов.
Навигация как реализация процесса поиска по запросу в выбранной БД —
целенаправленная, определяемая стратегией, последовательность использования
методов, средств и технологий конкретной АИПС для получения и оценки
результата.
Средства навигации позволяют пользователю осуществлять управление процессом
поиска. Они предоставляются пользователю в виде интерфейса, позволяющего
организовать более или менее эффективный процесс взаимодействия с БД. При этом
«дружественность» интерфейса характеризуется не только
эргономичностью и понятностью, но и вариантностью выбора операционных объектов.
Процесс поиска информации представляет последовательность шагов,
приводящих при посредстве системы к некоторому результату, и позволяющих
оценить его полноту. Так как пользователь обычно не имеет исчерпывающих знаний
об информационном содержании ресурса, в котором проводит поиск, то оценить
адекватность выражения запроса, равно как и полноту получаемого результата, он
может, основываясь лишь на внешних оценках или на промежуточных результатах и
обобщениях, сопоставляя их, например, с предыдущими.
Процесс поиска можно представить в виде следующих основных
компонент:
1) формулирование запроса на естественном языке, выбор поисковых
системы и сервисов, формализация запроса на соответствующем ИПЯ;
2) проведение поиска в одной или нескольких поисковых системах;
3) обзор полученных результатов (ссылок);
4) предварительная обработка полученных результатов: просмотр содержания
ссылок, извлечение и сохранение релевантных и пертинентных данных;
5) при необходимости, модификация запроса и проведение повторного (уточняющего)
поиска с последующей обработкой полученных результатов.
Для уменьшения объёма отобранных материалов осуществляют
фильтрацию результатов поиска по типу источников (сайтов, порталов), тематике и
другим основаниям.
По используемым поисковым технологиям ИС можно разбить на 4 категории:
1. Тематические каталоги;
2. Специализированные каталоги (онлайновые справочники);
3. Поисковые машины (полнотекстовый поиск);
4. Средства метапоиска.
В Интернете ИПС размещается на одном или нескольких серверах. В
ИПС собирается, индексируется и регистрируется информация о документах,
имеющихся в обслуживаемой системой группе веб-серверов. В документах
индексируются все значащие слова или только слова из заголовков.
Тематические каталоги предусматривают обработку документов и отнесение их к
одной из нескольких категорий, перечень которых заранее задан. Фактически это
индексирование на основе классификации. Индексирование может проводиться
автоматически или вручную с помощью специалистов, просматривающих популярные
веб-узлы и составляющих краткое описание документов-резюме (ключевые слова,
аннотация, реферат).
Специализированные каталоги или справочники создаются
по отдельным отраслям и темам, по новостям, по городам, по адресам электронной
почты и т. п.
Поисковые машины (самое развитое средство поиска в Интернете) реализуют
технологию полнотекстового поиска. Индексируются тексты, расположенные на
опрашиваемых серверах. Индекс может содержать информацию о нескольких миллионах
документов. Например, в индексе популярной ИПС «AltaVista» более 56
млн. URL-адресов.
При использовании средств метапоиска запрос
осуществляется одновременно несколькими поисковыми системами. Результат поиска
объединяется в общий, упорядоченный по степени релевантности список. Каждая
система обрабатывает только часть узлов сети, что позволяет расширить базу
поиска. К подобному классу можно отнести и «персональные программы
поиска», позволяющие формировать свои собственные инструменты метапоиска
(например, автоматически опрашивать часто посещаемые узлы).
Базы информационных данных могут содержать практически любые виды
информации, в том числе в любой комбинации. Информационный поиск осуществляется
как по существующим в полнотекстовых ЭИР терминам, так и по специальным
элементам, входящим в состав ИПЯ. Для формирования запросов используются
специальные информационно-поисковые языки.
ИПС внутри найденной выборки обычно пытаются расположить документы
в порядке их «релевантности«, то есть близости к введенному
пользователем запросу. Критериев такой близости много и выявление близких «по
смыслу» к запросу документов не решает проблемы получения информации при
отсутствии релевантного документа. Подобная ситуация достаточно тривиальна, в
том числе и потому, что пользователь зачастую ищет документ, который сам
собирается написать. Следует отметить, что в результате проведенного поиска
пользователь может получить как релевантные, пертинентные, так и нерелевантные
и непертинентные подмассивы данных.
ИПС фактически являются системами информационного
обеспечения и представляют собой базы и банки данных. В качестве объекта в
них выступает индивид, организация, отрасль, регион и т.п. Субъектом
информационного обеспечения является специалист-информатик, любой
потребитель информации.
Организация поиска
Предлагается процедуру поиска необходимой информации разделить на
девять основных этапов:
· Определение области знаний;
· Выбор типа и источников данных;
· Сбор материалов необходимых для наполнения
информационной модели;
· Отбор наиболее полезной информации;
· Выбор метода обработки информации
(классификация, кластеризация, регрессионный анализ и т.д.);
· Выбор алгоритма поиска закономерностей;
· Поиск закономерностей, формальных правил и
структурных связей в собранной информации;
· Творческая интерпретация полученных
результатов;
· Интеграция извлеченных «знаний».
Для проведения поиска первоначально на компьютере пользователя
загружается интерфейс работы с соответствующей БД. Это может быть локальная или
удалённая БД. Первоначально следует определиться с видом поиска (простой,
расширенный и т.д.). Затем с набором предлагаемых для поиска полей. ИПС могут
предложить для ввода одно или несколько полей. В последнем случае это обычно
поля: автора, заглавия (названия), временного периода, вида документа, ключевых
слов, рубрик и др. При формировании запроса практически все системы позволяют
использовать логические элементы «И», «ИЛИ»,
«НЕТ».
Технологии поиска информации
Поисковые средства и технологии, используемые для реализации
информационных потребностей, определяются типом и состоянием решаемой
пользователем задачи основной деятельности: соотношением его знания и незнания
об исследуемом объекте. Кроме того, процесс взаимодействия пользователя с
системой определяется уровнем знания пользователем содержания ресурса (полноты
представления, достоверности источника и т.д.) и функциональных возможностей
системы как инструмента. В целом эти факторы обычно сводятся к понятию
«профессионализма» — информационного (подготовленный/неподготовленный
пользователь) и предметного (профессионал/непрофессионал)
«профессионализма«.
Процесс поиска информации обычно носит эмпирический характер. Он
представляет последовательность шагов, приводящих при посредстве системы к
некоторому результату, позволяющих оценить его полноту. При этом поведение
пользователя, как организующее начало управления процессом поиска, мотивируется
не только информационной потребностью, но и разнообразием стратегий, технологий
и средств, предоставляемых системой.
Обычно пользователь не имеет исчерпывающих знаний об
информационном содержании ресурса, в котором проводит поиск, поэтому оценить
адекватность выражения запроса, как и полноту получаемого результата, он может,
отыскав дополнительные сведения, или организовав процесс так, чтобы часть
результатов поиска могла использоваться для подтверждения или отрицания
адекватности другой части.
Операционными объектами, непосредственно участвующими во
взаимодействии пользователей с поисковой системой являются поисковый образ
документа (ПОД) и ПОЗ, соответствие которых устанавливается поисковым
механизмом АИПС на формальном уровне. Адекватность образа действительному
содержанию документа определяется качеством процесса свертки информации и
уровнем знания субъектом средств отражения — концептуальной схемы предметной
области и возможностей ИПЯ.
Поисковый образ документа — описание документа, выраженное
средствами ИПЯ и характеризующее основное смысловое содержание или какие-либо
другие признаки этого документа, необходимые для его поиска по запросу.
Большинство ПС изначально предлагают пользователям либо БО, либо
ссылки на полные или частичные документы, их описание и другое, хранящиеся в
различных АИПС. Современные ПС позволяют определиться и указать какой и в каком
виде источник информации интересует пользователя.
Методы обработки результатов поиска
По характеру преобразований (в контексте дальнейшего использования
результатов обработки) методы обработки результатов поиска можно условно
разделить на две группы:
1. Структурно-форматные преобразования;
2. Структурно-семантические преобразования (информационно-аналитические,
логико-семантические).
Реализация поиска
Что обычно ищут в Интернете: персональные данные об индивидуумах и
организациях; различные адресные данные; конкретные материалы (статьи, книги,
фотографии, справочные данные, программное обеспечение и др.) в том числе место
их хранения; где и сколько стоят те или иные материалы, услуги, продукты и
т.п.; информационные сайты и порталы и др.
Общепринята организация поиска по начальным фрагментам слова
(поиск с усечением справа), например, вместо слова «библиотечный» можно
ввести его фрагмент «библиоте*». При этом будут найдены документы, в
которых содержится не только слово «библиотечный», но и
«библиотека», «библиотекарь», «бибилотековедение»
и др. В каждом случае пользователь должен представлять, что именно он хочет
найти, так как в предложенном ему варианте будет найдено гораздо большее
количество документов, чем при задании данного слова полностью (без усечения).
В подобном случае возможно в полученном массиве информации провести уточняющий
поиск и в результате получить более релевантные и пертинентные данные.
Оформление результатов
С точки зрения ИПС результат поиска в ней есть совокупность
(подмножество) найденных документов или ссылок на них. Обычно он представляется
пользователю в виде списка. То есть простейшей выходной формой в данном случае
будет список ссылок в виде полных или частичных БО, найденных ИР. Такой список
может быть тут же распечатан или послан на какой-либо адрес электронной почты,
если такая возможность предоставляется ИПС и пользователь подключен к
Интернету.
Графические и полнотекстовые ЭИР могут предлагаться пользователю
только для просмотра, для копирования в различных форматах и масштабах, причём
полностью или частично. Графические ИР обычно существуют в общепринятых
форматах типа: JPG, GIFF, TIFF, BMP и др., а для текстовых материалов обычно
используют текстовые форматы TXT, DOC и др., HTML и PDF — фактически
графический формат, в котором могут сохраняться как текстовые, так и
графические данные.
Полученные в результате поиска документы сохраняют.
Критерии оценки поиска
Критерием результата поиска является получение пользователем
списка документов, одного документа или их частей, максимально удовлетворяющего
его потребностям, сформулированным в поисковом запросе. В ИПС принято
формировать список полученных в результате поиска документов по их
релевантности. Различают критерии смыслового и формального соответствия между
поисковым предписанием и выдаваемым документом.
Полнота и точность поиска являются взаимосвязанными показателями.
Увеличение одного из них ведёт к снижению другого. В современных ИПС при
сбалансированном поиске их значения составляет примерно 70%. Следует учитывать
ситуацию, при которой список выданных поисковой системой ссылок содержит
несколько, а порой и десятки разных адресов с одним и тем же текстом. Подобные
ссылки характеризуются как дубликаты. Из них, при подсчёте коэффициентов
учитывается только один документ.
Оценка и обработка результатов поиска
Учитывая, что идеальный результат поиска должен удовлетворять
требованиям единственности, полноты и непротиворечивости, получаем, что
различные виды поиска определяют различные требования к функциональным
возможностям системы в части оценивания результата. Однако, для случая
предметного поиска доказательство полноты является тривиальным: непустой
результат поиска подтверждает факт существования (или отсутствия) объекта,
обладающего искомыми свойствами. При этом результат тематического поиска
множественен и требует последующей систематизации — ещё одного процедурного
шага для упорядочения полученного множества объектов по значениям не
определённого явно основания. В свою очередь, проблемный поиск предполагает уже
двухуровневую систематизацию.
Развитие процесса поиска осуществляется путём модификации
выражения ПОЗ, путем реформулирования запроса и проведения повторного поиска в
том же массиве данных или в подмассиве, полученном в результате осуществления
первоначального поиска.
Интерфейсные средства обработки результата и развития поиска используют два типа
операционных объектов — отдельные документы или коллекции документов.
Для получения информации в среде Интернета создаются специальные
поисковые системы. Как правило, они общедоступны и обслуживают пользователей в
любой точке планеты, где имеется возможность работы с Интернетом.
Непосредственно для поиска используются поисковые машины, число которых в мире
исчисляется несколькими сотнями. Они ориентируются на определенные типы
запросов или их сочетание (библиографический, адресный, фактографический,
тематический и др.). Кроме того, бывают полнотекстовые, смешанные и другие
поисковые машины.
Для проведения поиска в Интернете (в WWW) функционирует множество
сайтов и поисковых систем, поэтому необходимо не только ориентироваться в таких
системах, но и уметь осуществлять в них эффективный поиск, то есть использовать
соответствующие технологии.
«Технология поиска (англ. «Search
Technology») означает совокупность правил и процедур, в результате
выполнения которых пользователь получает ИР. При поиске в Интернете
рекомендуется обращать внимание на две составляющие: полноту (ничего не
потеряно) и точность (не найдено ничего лишнего). Обычно соответствие найденных
материалам этим критериям называют релевантностью, то есть
соответствием ответа вопросу (запросу).
Поисковые системы характеризуются также временем выполнения
поиска, интерфейсом, предоставляемым пользователю и видом отображаемых
результатов. При выборе поисковых систем обращают внимание на такие их
параметры, как охват и глубина. Под охватом понимается объём
базы поисковой машины, измеряемый тремя показателями: общим объёмом
проиндексированной информации, количеством уникальных серверов и количеством
уникальных документов. Под глубиной понимается — существует ли ограничение на
количество страниц или на глубину вложенности директорий на одном сервере.
Каждая поисковая машина имеет свои алгоритмы сортировки
результатов поиска. Чем ближе к началу списка, полученного в результате
проведения поиска, оказывается нужный документ, тем выше релевантность и лучше
работает поисковая машина.
Поисковые машины используют общие принципы работы, ориентированные
на выполнение двух основных функций. Первая функция реализуется
программой-роботом, автоматически просматривающей различные сервера в
Интернете. Находя новые или изменившиеся документы, она осуществляет их
индексацию и передаёт на базовый компьютер поисковой машины. «Робот»
— автоматизированный браузер, загружающий веб-страницу, изучающий её и, при
необходимости, переходящим к одной из её гиперсвязей. Когда ему попадается
страница, не содержащая связей, робот возвращается на одну-две ступени назад и
переходит по адресу, указанному в одной из обнаруженных ранее связей.
Запущенный робот проходит огромные расстояния в среде Интернета
(киберпространстве), ориентируясь на развитие веб-сети и изменяя в соответствии
с этим свои маршруты. Индексирующие роботы обрабатывают лишь HTML-файлы,
игнорируя изображения и другие мультимедийные файлы. Они могут: обнаруживать
связи с уже несуществующими страницами; устанавливать связь с наиболее популярными
узлами, подсчитывая количество ссылок на них в других веб-страницах;
регистрировать веб-страницы для оценки роста системы и др. Чаще всего роботы
просматривают сервера самостоятельно, находя новые внешние ссылки в уже
обследованных документах. Вторая функция заключается в
обработке выявленных документов. При этом учитывается все содержание страниц
(не только полный текст, но и наличие иллюстраций, аудио и видео файлов,
Java-приложений). Индексации подвергаются все слова в документе, что дает
возможность использовать поисковые системы для детального поиска по самой узкой
тематике. Образуемые гигантские индексные файлы, хранящие информацию о том,
какое слово, сколько раз, в каком документе и на каком сервере употребляется,
составляют БД, к которой собственно и обращаются пользователи, вводя в
поисковую строку ПОЗ (сочетания ключевых слов). Выдача результатов
осуществляется с помощью специальной подсистемы, производящей интеллектуальное
ранжирование результатов. В своих расчетах она опирается на местоположение
термина, частоту его повторения в тексте, процентное соотношение данного
термина с остальным текстом на данной странице и другие параметры,
характеризующие возможности конкретной поисковой машины.
«Роботы» имеют ряд разновидностей, одной из которых
является «паук» (англ. «spider»). Он непрерывно
«ползает по сети», переходя с одной веб-страницы к другой с целью
сбора статистических данных о самой «паутине» (Web) и (или)
формирования некоторой БД с индексами содержимого веб.
Автоматизированные агенты «спайдеры» регулярно
сканируют веб-страницы и актуализируют БД адресов (гиперссылки), средства
индексирования информации, расположенные по указанным адресам. Полученные
индексы используются для быстрого и эффективного поиска по набору терминов,
задаваемых пользователем.
В разных системах эта цель достигается различным образом. Одни
посылают «агентов» на каждую попадающуюся веб-страницу, индексируя
все встречающиеся слова. Другие сначала анализируют БД адресов, определяя
наиболее популярные (обычно подсчитывается число имеющихся ссылок на них).
Именно эти веб-страницы в различной степени индексируются (только заголовки
веб-страниц и ссылки, включая автоматическое аннотирование документов или весь
текст).
Все чаще применяются «интеллектуальные агенты» —
небольшие программы, обладающие способностью самообучаться, и действовать
самостоятельно от имени своего владельца. Имея связь с компьютером
пользователя, они выступают в роли персональных помощников, выполняющих ряд
задач с применением знаний о потребностях и интересах пользователя.
Интеллектуальные роботы-агенты ведут самостоятельный поиск в сети по
собственным уникальным алгоритмам. Некоторые из них не только просматривают
ключевые слова, но и осуществляют в Интернете семантический анализ информации, выявляя
степень ее смыслового соответствия поставленной задаче.
Эффективный доступ к информации в Интернете обеспечивают
такие зарубежные поисковые системы (машины), как
Альта-Виста (AltaVista), «Lycos», «Yahoo»,
«Google», «OpenText», «Wais»,
«WebCrawler» и др. Их адреса в Интернете: www.altavista.com,
www.yahoo.com, www.gogle.com, www.opentext.com,
К отечественным поисковым машинам относятся: Апорт
(«Aport» АО Агама), Rambler (фирма Stack Ltd.), Яндех
(«Yandex» фирма CompTek Int), «Русская машина поиска», «Новый
русский поиск», и др. Их адреса в Интернете: www.aport.ru, www.rambler.ru,
www.yandex.ru, search.interrussia.com, www.openweb.ru соответственно) и др.
Все эти поисковые машины позволяют по ключевым словам,
тематическим рубрикам и даже отдельным буквам оперативно находить в сети,
например, все или почти все тексты, где эти слова присутствуют. При этом
пользователю сообщаются адреса сайтов, где найденные ИР постоянно присутствуют.
Однако ни одна из них не имеет подавляющих преимуществ перед другими. Для
проведения надежного поиска по сложным запросам специалисты рекомендуют
использовать последовательно или параллельно (одновременно) различные ИПС.
Полнотекстовая поисковая машина индексирует все слова видимого
пользователю текста. Наличие морфологии дает возможность находить искомые слова
во всех склонениях или спряжениях. Кроме этого, в языке HTML существуют тэги,
которые также могут обрабатываться поисковой машиной (заголовки, ссылки,
подписи к картинкам и т.д.). Некоторые машины умеют искать словосочетания или
слова на заданном расстоянии, что часто бывает важно для получения разумного
результата.
Несмотря на общие принципы построения, поисковые системы
отличаются тематикой, ее объемом, классификацией и интерфейсами. Для удобства
перемещения (навигации) по имеющимся на поисковых машинах разделам некоторые из
них используют специальный раздел «Карта».
Зачастую пользователю требуется текстовая и картографическая
информация одновременно. В 80-е годы XX века эксперименты по решению этой
проблемы начали проводить в Канаде, так появились первые географические
информационные системы (ГИС) — компьютерные системы, позволяющие
эффективно работать с пространственно-распределенной картографической
информацией. ГИС — закономерное расширение концепции БД, дополняющее их
наглядностью представления и возможностью решать задачи пространственного
анализа. Они применяются для землеустройства, контроля ресурсов, экологии,
муниципального управления, транспорта, экономики, решения социальных задач и
др. До 80-90% всей информации, с которой обычно имеют дело пользователи, может
быть представлено в ГИС. ГИС — этап перехода к безбумажной технологии обработки
информации.
При проведении поиска поисковые серверы обычно используют данные,
хранящиеся в веб-страницах в тегах метаданных: (title), (meta name=”keywords”)
и (meta name=”description”). Формируя свои страницы, следует отражать в этих
тегах сведения о назначении сайта и его тематике.
При этом необходимо знать, что чем меньше количество ключевых слов
включено в эти теги, тем с большей частотой они могут встречаться в текстах
страниц сайта и, следовательно, тем выше их релевантность. Оптимальным
считается частота таких слов не более 5%. Ключевых слов должно быть не очень
много, они в большей степени должны состоять из одного или двух слов, образуя
наиболее употребляемые термины. Чем большую релевантность имеют ключевые слова,
тем большую конкурентоспособность они придают документу с точки зрения
поисковых машин.
Полноту и точность ответа пользователь получает в зависимости от точности
сформулированного им запроса. В результате поиска ему обычно предоставляется
гораздо больше информации, чем ему необходимо, часть которой может вообще не
иметь отношение к сформированному запросу. Легко заметить, что многое зависит
не только от грамотно сформулированного запроса, но и от возможностей поисковых
систем, которые весьма различны. При этом достаточно ярко проявляется «лесной
синдром» (из-за леса не видно дров), заключающийся в том, что в
полученных данных можно пропустить главные, необходимые сведения. Очевидно,
никакие меры не являются исчерпывающими в условиях постоянного расширения среды
и появления новых разнообразных ИР, что подтверждает трудности поиска в WWW.
Простые запросы в виде отдельных достаточно распространенных
терминов приводят к извлечению тысяч (сотен тысяч) документов, абсолютное
большинство которых пользователю не требуется (информационный шум).
Важным аспектом также является возможность таких систем
поддерживать многоязычность, то есть способность обрабатывать запросы на
различных языках. Пользователям предлагаются двуязычные словари, электронный
переводчик и др. Кроме того, появились системы, осуществляющие мгновенный
(«на лету») перевод информационных ресурсов, найденных пользователем
в Интернет и копируемых на его компьютер.
Актуальным является использование машиночитаемых тезаурусов.
Электронный тезаурус — словарь, предназначенный для анализа текста и
информационного поиска, включающий широкий набор семантических отношений между
составляющими его терминами.
Создаются системы, позволяющие эффективно вести поиск в
полнотекстовых БД. Они базируются на использовании технологий синтаксического и
морфологического анализа текста (разбивка на элементы, распознаваемые
программой) и оперативной обработки текстов на естественных языках.
Разработчики поисковых систем пытаются адаптировать их под
начинающих и «средних» пользователей Интернета, количество которых
неуклонно растет. В канадской системе (www.web-help.com), пользователям
предлагается набор ссылок, подготовленных сотрудниками интернет-компании. На
запрос пользователя сотрудник в реальном режиме времени находит и подключает на
экран пользователя соответствующий (по его мнению) сайт. Метод удобен для
нахождения конкретных фактов, статистики и т.п., которые другими способами
непросто найти.
При организации одинакового запроса на разных поисковых машинах
возможно получение различных по содержанию и широте охвата материалов.
Искусство построения запроса требует знаний особенностей каждой конкретной
поисковой системы и наличия опыта работы с Интернетом вообще. Некоторые
поисковые машины предлагают квазиинтеллектуальные средства, позволяющие менее
опытному пользователю, традиционно задавая вопросы на естественном языке,
получать достаточно релевантные данные.
Обычно поиск в полнотекстовых БД осуществляется с использованием
морфологических анализаторов (как правило, русских и английских), позволяющих
автоматически находить существующие словоформы по фрагменту слова, слову,
фразе, даже если в словах запроса присутствуют некоторые опечатки.
Используются метапоисковые системы, обеспечивающие в результате
поиска получение суммарных данных с десятка поисковых систем, но при этом объем
информации может быть весьма значительным. Частично данная проблема решается
предоставлением ими общего списка, в начале которого будут данные, наиболее
релевантные запросу. Другим способом удовлетворения потребностей пользователей
явилось создание тематически узконаправленных поисковых систем на веб-сайтах
— порталов.
Важность проблемы информационного поиска в Интернете породила
целую отрасль, задача которой заключается в том, чтобы помочь пользователю в
его навигации в киберпространстве. Составляют эту отрасль специальные поисковые
инструменты. Условно их можно разделить на поисковые средства
справочного типа или просто справочники (directories) и поисковые
системы в чистом виде (search engines).
Метапоисковые системы
Увеличение числа поисковых систем в Интернете обусловило появление
«метапоисковых систем». Они дают возможность
пользователю одновременно в едином пользовательском интерфейсе, используя
индексы обычных поисковых систем, работать с несколькими БД. Пока еще
«метапоисковые системы» не позволяют реализовать все возможности
отдельных поисковых систем, но в большинстве своем он обладают существенными быстродействием
и степенью охвата Web-пространства, что определяет их все более возрастающие
значение и популярность.
Органические поисковые результаты
Основную часть поисковой выдачи
составляют органические (или естественные) поисковые результаты. Это список
документов, найденных и проиндексированных поисковой системой, на ранжирование
и показ которых не влияет продаваемая поисковой системой реклама. Обычно он
упорядочен по убыванию релевантностидокументов поисковому запросу согласно применяемым в поисковой
системе алгоритмам ранжирования, но во многих системах предусмотрены также и другие виды
сортировки, например, по дате документов.
В качестве документов обычно
выступают веб-страницы, но многие системы способны также индексировать и
выдавать ссылки на файлы в таких форматах, как .pdf,.doc, .ppt и т. д., страницы с
Flash-анимацией (.swf). Некоторые системы внедрили так называемый универсальный
поиск (англ. universal search)[5] — наряду с обычными
документами в поисковую выдачу могут замешиваться, например, результаты поиска
по картинкам, видеороликам, новостям, картам. С ростом популярности
структурированных данных (Structured data) все чаще в поисковой выдаче можно
наблюдать «расширенные» сниппеты, которые занимают около 20-30%
от первой страницы Google.
Для каждого документа, как
правило, показывается по крайней мере его заголовок, адрес и сниппет,
показывающий слова запроса в контексте документа. Часто рядом с адресом есть
также ссылка на сохранённую копию документа в кэше поисковой системы и функцию
поиска похожих документов. Google способен показывать для
некоторых документов карту сайта (sitemap) и дополнительные релевантные
страницы с того же сайта.
Шорткаты
Во многих поисковых системах для
некоторых типов запросов в поисковой выдаче появляются специальным образом
составленные результаты, сразу дающие ответ на пользовательский запрос, когда
это возможно, или предоставляющие полезную ссылку или информацию. Общепринятого
названия этим результатам не сложилось.Yahoo и некоторые независимые
исследователи[4] называют их «шорткатами» (англ. shortcuts), Google — «one-box’ами», Яндекс — «колдунщиками»[6], Bing — «быстрыми ответами» (англ. instant answers), QIP — «чудодеями»[7][8], DuckDuckGo — «полезностями» или «вкусностями» (англ. goodies)[9]. Обычно они появляются над
результатами органической выдачи. Шорткаты можно рассматривать как часть
технологии универсального поиска.
В качестве примеров ниже
перечислены некоторые из one-box’ов, реализованных в Google:[10]
·
Калькулятор. В ответ на запрос, содержащий
арифметическое выражение, вычисляется его значение. Google также поддерживает
функцию перевода денег из разных валют как часть калькулятора.
·
Поиск
определений.
Например, запрос «что такое астрофизика» выведет определение этого термина,
найденное на странице из Википедии.
·
Поиск
фактов. Google способен
распознавать и отвечать на такие запросы, как, например, «высота Эльбруса».
·
Запрос
«MSFT» (тикер корпорации Microsoft на фондовых биржах) выдаёт информацию о котировках её
акций.
·
Запрос
«время в Москве» покажет текущее время в этом городе.
Поисковая система тем лучше, чем больше
документов, релевантных запросу пользователя, она будет возвращать. Результаты
поиска могут становиться менее релевантными из-за особенностей алгоритмов (см.
«Пузырь фильтров»[⇨]) или вследствие человеческого фактора[⇨]. По состоянию на 2015 год самой
популярной поисковой системой в мире является Google, однако есть страны, где
пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на
10 %[⇨].
По методам поиска и обслуживания
разделяют четыре типа поисковых систем: системы, использующиепоисковых роботов, системы, управляемые человеком, гибридные системы и
мета-системы[⇨]. В архитектуру поисковой системы обычно
входят:
· поисковый робот, собирающий
информацию с сайтов сети Интернет или из других документов,
· индексатор, обеспечивающий быстрый поиск по
накопленной информации, и
· поисковик — графический
интерфейс для работы пользователя[⇨].

Операторы в поисковых запросах
Для уточнения результатов поиска можно использовать специальные
операторы и пунктуацию. Пунктуация при поиске, как правило, игнорируется.
Исключения приведены ниже.
Пунктуация и символы
Хотя перечисленные ниже символы поддерживаются, их включение в
запросы не всегда улучшает результаты поиска. Если пунктуация не сделает поиск
точнее, Google может предлагать результаты без нее.
|
Символ |
Инструкции |
|
+ |
Поиск +страниц или групп крови |
|
@ |
Поиск |
|
$ |
Поиск |
|
# |
Поиск популярных хештегов для |
|
– |
Если |
|
« |
Если |
|
* |
Звездочка |
|
.. |
Чтобы |
|
OR |
Операторы в поисковых запросах
Операторы поиска – это слова, добавляемые к поисковым
запросам для уточнения результатов поиска. Их необязательно запоминать: те же возможности
доступны на странице Расширенный поиск.
|
Оператор |
Инструкции |
|
site: |
Получение |
|
link: |
С |
|
related: |
Используйте |
|
OR |
Используйте |
|
info: |
С |
|
cache: |
Этот |
|
lang:язык |
Linux lang:en |
|
Date:количество месяцев |
3,6,12 |
Примечание. При поиске с использованием операторов не добавляйте пробел
между оператором и поисковым запросом. Например, поисковый запрос site:korrespondent.ru сработает, а запрос site: korrespondent.ru – нет.
Конструктивный компонент информационной деятельности специалиста технического сервиса предполагает деятельность по сбору, обработке, передаче информации с использованием средств ИТ, связанную с организацией работ по ремонту и обслуживанию транспортных и технологических машин, оборудования и их подсистем в современных условиях с использованием средств ИТ. Организация научно-исследовательской деятельности по освоению новой техники и технологий средствами ИТ, предполагает сбор и обработку информации, доступной из специализированных баз данных, обеспечивающих автоматизацию процессов информационно обеспечения. Помимо этого предполагается автоматизация процесса поиска информации о претензиях владельцев техники по поводу качества проданной и отремонтированной техники, автоматизация процесса обработки информации с целью установления реального качества ремонта и технического обслуживания техники организациями технического сервиса, а также автоматизация процесса использования информации по результатам обследования станций технического обслуживания. [c.277]
При автоматизации поиска документальной информации важнейшими являются задачи формализации содержания документа и запроса. При решении этих задач могут использоваться различные подходы. [c.501]
Переход к новой информационной технологии хозяйственного учета требует также решения проблем электронных коммуникаций. Современные коммуникационные системы, используемые для автоматизации информационной деятельности [16, 24], в том числе и хозяйственного учета, предназначены для выполнения функций переноса, обработки, хранения и поиска информации. Вместе с тем широкое применение должны найти средства так называемой электронной почты (ЭП), выполняющие функции обмена производственно-экономической информацией как в рамках одного предприятия (объединения), так и между несколькими предприятиями. В качестве абонентных устройств в системах электронной почты используются обычные термина- [c.160]
Важно подчеркнуть, однако, что стандартизация официальной переписки на основе формализации как внешних, так и содержательных элементов официального письма служит не только средством облегчения обработки письма традиционными методами, но и обусловливает в известной степени применение для обработки писем, хранящихся в канцеляриях предприятий и учреждений, средств автоматизации составления писем и поиска информации. Однако уже давно назрела проблема более широкой автоматизации управленческого труда. [c.7]
Получение достоверных данных в условиях автоматизированного учета возможно лишь при создании системы контроля, основанной на максимальной автоматизации поиска и выявления ошибочной информации на различных этапах ее обработки. Опыт показывает, что-на предприятиях по поставкам продукции в процессе разработки и эксплуатации АСУ нет единства в подходах к методам контроля. Применяемые методы контроля не всегда обеспечивают высокую степень достоверности информации. В связи с этим целесообразно на основе обобщения передового опыта разработать и внедрить методические рекомендации по созданию систем подготовки и обработки исходных данных с учетом отраслевой специфики. Создание такого документа будет способствовать повышению эффективности систем обработки информации. [c.109]
При выборе оптимального состава КТС следует исходить из основных показателей их качества времени сбора информации и решения задач надежности КТС точности обработки и выдачи выходной информации гибкости КТС, которая обеспечивается варьированием различных видов устройств в зависимости от сложности решаемых задач возможность максимальной механизации и автоматизации технологических процессов по сбору и обработке, хранению и поиску информации при минимальной стоимости КТС простота обслуживания и возможность наращивания мощности КТС в процессе развития системы. [c.46]
Внедрение этой техники поднимает управленческий труд на более высокий инженерный уровень, обеспечивает его четкое функционирование. В целях широкого внедрения средств механизации требуется разработать алгоритмы плановых расчетов для разных ступеней и этапов планирования, обеспечить серийный выпуск унифицированных блоков, чтобы ЭВМ можно было комплектовать для экономических и инженерных расчетов, оперативного планирования и регулирования и других целей, создать средства автоматизации подготовки информации к обработке, считывания показателей счетчиков и передачи их в центр обработки и т. д. Повышение уровня управления во многом зависит от механизации и автоматизации процессов обработки, хранения и поисков информации о развитии науки и техники. [c.317]
Системы автоматизации продаж изначально предназначались для того, чтобы увеличить производительность труда специалистов по продажам и дать им стимул лучше документировать свои взаимодействия с клиентами. Как видно из графика, только 25-30% времени менеджеры по продажам в средней российской компании тратят на свои непосредственные задачи — взаимодействие с клиентами и анализ новых поступающих сделок (квалификация). Большая часть времени утекает на решение рутинных операционных задач — поиск информации, решение всевозможных технических и организационных проблем, согласования и т.д. [c.181]
Экономические информационные системы предназначены для решения задач обработки данных, автоматизации конторских работ, выполнения поиска информации и отдельных задач, основанных на методах искусственного интеллекта. [c.11]
ОГАС призван объединить все информационно-вычислительные центры страны и на этой основе создать всесоюзный автоматизированный банк данных (АБД)., который обеспечит полную механизацию и автоматизацию процессов сбора, обработки, передачи, контроля, хранения, поиска и выдачи информации, в том числе и бухгалтерской. [c.54]
Основные направления механизации и автоматизации инженерных работ показаны на рис. 5.4. Информационно-прогностические системы имеют целью обеспечение прогрессивности технологических решений. В памяти системы используется патентная информация, а также информация из книг и журналов, отчетов по командировкам, информация по конференциям, выставкам, обмену опытом и др. Информационно-поисковые системы (см. п. 4.3) предназначены для поиска в памяти системы [c.162]
Средства хранения, поиска и транспортировки документов различной емкости, назначения и степени механизации и автоматизации (хранилища, боксы, шкафы, картотечное оборудование, средства микрофильмирования и поисковые системы, транспортирующие устройства и оборудование электрическое, пневматическое, электромагнитное, контейнерное и др.), а также средства передачи информации. [c.302]
Инструментальные программные средства могут быть разных видов текстовые и графические редакторы для подготовки текстов, графиков, диаграмм, табличные процессоры или электронные таблицы для автоматизированной обработки информации, представленной в табличной форме, системы управления базами данных для автоматизации работ по созданию базы данных, поиска необходимых сведений для аналитических расчетов. Интегрированные пакеты включают в себя текстовый и графический редакторы, табличный процессор, СУБД. [c.243]
Облегчить труд аппарата управления, повысить его производительность и культуру и призвана организационная техника. Необходимость широкого использования средств оргтехники возникает также в связи с переходом к рыночным отношениям, ростом производства и изменением номенклатуры товаров, а также увеличением объемов информации, требующей быстрой обработки. Традиционные приемы сбора, обработки и передачи информации становятся малоэффективными, а это требует поиска и внедрения высокопроизводительных систем механизации и автоматизации управленческого труда. Так, внедрение даже простейших средств техники управления сокращает затрачиваемое на обработку документов время приблизительно на 20 %, а системное их применение увеличивает производительность управленческого труда в 3 раза. [c.176]
В условно-постоянной информации большой удельный вес занимает нормативная информация, которая используется при решении задач бухгалтерского учета. К этой информации относятся данные о составе изделий и применяемости деталей в этих изделиях, данные о технологических маршрутах изготовления изделий, пооперационные нормы затрат труда и подетальные нормы расхода материалов и др. Нормативные данные могут быть первичными и сводными, которые получаются путем обработки и обобщения первичных нормативов. Примером первичных нормативов являются пооперационные нормы затрат труда и подетальные нормы расхода материалов, сводных — нормативные затраты на изделия в разрезе статей затрат. Кроме нормативной информации используется также планово-договорная информация планы выпуска продукции на год, квартал, месяц, плановые (сметные) расходы на выпуск продукции, договоры и контракты и т.д. Вся эта нормативная и планово-договорная информация обрабатывается и подготавливается вне бухгалтерии. Храниться она должна в виде единого нормативно-справочного фонда, доступ к которому должен быть обеспечен при решении любых задач управления, в том числе и задач бухгалтерского учета. Нормативно-справочный фонд должен отвечать требованиям полноты (иметь весь необходимый набор данных для решения любых задач пользователей), актуальности и достоверности, удобству работы и быстроте поиска данных, безопасности данных, обеспечения работы в многопользовательском режиме. Проблема организации и ведения нормативно-справочного фонда актуальна для крупных предприятий, для которых характерна автоматизация на уровне корпоративных информационных систем или бухгалтерских комплексов. В корпоративных информационных системах эта проблема решается сразу при создании системы. Если же на предприятии автоматизируется только бухгалтерский учет, пусть даже на основе комплексных систем, то необходимо продумать вопросы организации и ведения нормативно-справочного фонда и взаимодействие его с бухгалтерским комплексом. Иначе не решить многих задач учета, требующих привлечения нормативных данных при расчетах или сравнительном анализе, например при сопоставлении фактических и нормативных (сметных) затрат на изделия или продукцию в целом. [c.126]
Эффективность управления и оперативность регулирования производственного процесса во многом зависят от степени механизации и автоматизации процесса управления. Поэтому при оценке уровня организации управления важно определять показатель технической оснащенности управленческого труда (Тут.), который характеризует стоимость технических средств управления (вычислительная техника с необходимым вспомогательным оборудованием, средства подготовки, размножения и копирования документов, средства их обработки, хранения, поиска и транспортировки, средства связи, сигнализации, передачи информации и др.) в расчете на одного работника управления. [c.183]
К настоящему времени в НТО машиностроения накоплен определенный опыт автоматизации исследований и проектирования — начиная с выполнения с помощью ЭВМ отдельных функций и операций (прежде всего — сложных расчетов, поиска и обработки информации, графических построений) и кончая созданием и развитием автоматизированных систем для выполнения комплекса работ, объединенных по тем или иным признакам. [c.13]
В современном информационном обществе эффективность работы транспортных и технологических машин и оборудования и их подсистем — сервиса и технической эксплуатации — зависит от компетентности специалистов в области использования средств автоматизации сбора, поиска, использования информации об обеспечении качества ремонта и технологического обслуживания техники организациями технического сервиса с использованием средств ИТ. [c.275]
Автоматизация телемаркетинга существенно упрощает процедуру поиска важной информации, например [c.388]
Заметным явлением в истории делопроизводства 70—80-х гг. было издание государственных стандартов (ГОСТ) на управленческие документы (ГОСТ 6.38-72, ГОСТ 6.39-72 и др.), разработка общесоюзных классификаторов технико-экономической информации (ОК ТЭИ) — ОКУД, ОКПО, ОКОНХ и др., унифицированных систем документации (УСД) и серии государственных стандартов на унифицированные системы. Внедрение этих документов в практику управления значительно улучшило оформление документов, упростило процедуры поиска, учета и хранения документов и документной информации, подготовило почву для автоматизации управленческой деятельности. [c.29]
Ключом к решению проблемы повышения уровня эффективности деятельности персонала офиса считается концепция так называемого электронного (автоматизированного) офиса. Речь идет о комплексном использовании современных технических средств для автоматизации процедур и функций управления (обработка текстов, их редактирование, хранение и поиск, передача информации по каналам электросвязи внутри офиса и за его пределы, информационное обслуживание персонала офиса, некоторые аспекты процесса подготовки и принятия решения и т. д.), средств программной поддержки, подходов к проектированию помещений офиса, охраны труда персонала. [c.367]
Системы управления документами (СУД) предназначены для автоматизации хранения, поиска и управления электронными документами разнообразных форматов, в том числе и изображениями документов. Можно сказать, что СУД фактически выполняют роль СУБД для неструктурированной информации. [c.539]
В автоматизации деятельности строительных компаний это может оказывать существенную помощь. Доступ к справочной информации, поиск заказов, партнеров, поставщиков, транспортные перевозки и многое другое можно осуществлять через Интернет. Но глобальная автоматизация не полностью овладела строительными предприятиями, парк компьютерной техники не всегда соответствует требуемым характеристикам, да и линии связи через наши допотопные АТС не способствуют комфортному погружению в мировую информационную систему. Поэтому коснемся реальной помощи от подключения к интернету и уровню поддержки, которую можно получать от использования информационной сети. [c.514]
В настоящий период 40—60% рабочего времени руководителей затрачивается на выполнение таких видов деятельности, которые могли бы выполняться специалистами более низкой квалификации. Много времени теряется на поиск необходимой информации, данных и документов. Это свидетельствует о необходимости автоматизации рутинных операций, более широкого применения в практике управленческой [c.313]
Рассматривая вопросы унификации и стандартизации документов, далее мы будем иметь в виду, что занимаемся рационализацией не избыточного документного потока, а только теми документами, которые действительно необходимы для эффективного управления. Ориентация документов на использование банков данных вытекает из предыдущего направления и является его дальнейшим развитием. Принцип проектирования интегрированных первичных документов, обслуживающих группу задач, можно считать этапом на пути этого развития . Хранение интегрированной информации может производиться в различном виде, т. е. банк данных может представлять традиционные документы, сформированные в удобном для пользования виде, или систему карт обычной картотеки, или перфорационные карты с краевой перфорацией для сортировки и поиска с применением простейшей механизации. Если подобная система накопления, хранения и поиска данных, необходимых для решения задач, основывается на применении средств вычислительной техники с автоматизацией выполняемых операций, то такой банк называют автоматизированным. [c.35]
Существенно облегчает экономический анализ, повышает комплексность и оперативность обслуживания потребителей статистическими данными автоматизация функций хранения, поиска и выдачи информации — создание автоматизированных банков данных (АБД). АБД позволяет выдавать потребителям через дисплей в абонентский пункт необходимую им информацию в любой момент времени и в любой требуемой форме. Аналитическая, плановая или управленческая работа в своей основе сводится к целенаправленной переработке информации. Часть ее процедур не формализована и поэтому может быть выполнена только людьми. В силу творческого характера этой деятельности подчас практически невозможно заранее точно предугадать и сроки, и точный состав необходимой информации. [c.18]
Белоногов Г. Г., Новоселов А. П. Автоматизация процессов накопления, поиска и обобщения информации.—М. Наука, 1979.—256 с. [c.241]
Информационно-поисковая система строится на базе данных регистрации документов с использованием единого обязательного набора реквизитов. В зависимости от специфики организации состав реквизитов может быть увеличен. В автоматизированной информационно-поисковой системе используются коды общесоюзного классификатора технико-экономической информации. При частичной автоматизации поисковых операций должна соблюдаться совместимость традиционной и автоматизированной систем регистрации и поиска. [c.210]
По степени механизации и автоматизации сбора и обработки, хранения и поиска необходимой для управления информации системы обработки данных подразделяются на следующие пять групп [c.8]
Системы автоматизации работы офиса ( APO) используются для создания, хранения, изменения, отображения информации, а также выполняют вспомогательную роль в деловой корреспонденции. Сегодня редко можно встретить фирму, которая не имела бы своего электронного адреса (e-mail) некоторые фирмы активно используют и другие возможности глобальной компьютерной сети Интернет, например, поиск информации в Интернет, реклама через Интернет, проведение видеоконференций. В настоящее время существуют даже фирмы, специализирующиеся исключительно на бизнесе (например, на торговле) в Интернет. [c.168]
Организационные автоматы, кроме функций, присущих пишущим автоматам, выполняют ряд дополнительных операций, например автоматизацию переформирования текста по строкам (с меньшего формата бумаги на больший или наоборот), подсчет количества строк на странице, поиск информации на носителе с выводом ее на автоматическую печать, выполнение расчетных операций и т. д. Пишущие автоматы резко повышают производительность работ при многократной перепечатке одного и того же документа с внесением небольших изменений. Ответственные доклады, проекты планов и другие документы пере-печатываются порой до десяти и более раз. Однако даже в больших организациях такие документы готовятся относительно редко и пишущие автоматы ими полностью, как правило, не могут быть загружены. Эффективно применение пишущих автоматов для изготовления документов, включающих типовые тексты, для которых нецелесообразно применять бланки. В практике управления на пишущих автоматах часто изготавливаются типовые письма, и особенно эффективно их применение, если они составляются на нескольких языках. Здесь экономится время не только составителя письма и машинистки, но и переводчика. 42 [c.142]
К средствам автоматизации можно отнести ЭВМ и приданные ей электронные системы обработки данных, электронные пишущие машинки и печатающие устройства, список адресатов, графики, электронные графопостроители, электронные системы регистрации документации, телефаксы и телексы, средства поиска информации, цветное воспроизведение диаграмм, передачу с помощью факса (факсимиле), доступ к базе данных, видеотекст (например, телетекст или гелеинформацкя). [c.184]
Data Mining. Пакет предназначен для автоматизации обработки огромных объемов информации в глобальных сетях и больших базах данных крупных ведомств и фирм посредством поиска данных и выявления их взаимосвязей. [c.150]
По оценкам американских экспертов (фирма Delphi onsulting), в США ежедневно генерируется более 1 млрд страниц документов, а в архивах хранится уже более 1,3 трлн документов, причем поток деловой информации чрезвычайно разнообразен по видам ее представления. Можно выделить три основных составляющих деловой информации. Поданным вышеназванной фирмы, 12% информации структурировано, представлено в электронной форме, хранится и управляется с помощью систем управления базами данных. Примерно 15% информации представляет собой неструктурированные данные в электронной форме, как правило, это текстовая информация. Для автоматизации хранения и поиска такой информации используются технологии информационно-поисковых систем. Оставшиеся около 73% информации традиционно хранятся на бумаге. Организация быстрого и эффективного поиска такой документальной информации становится все более неразрешимой проблемой. [c.500]
Постоянное увеличение количества информации, необходимой для принятия правильного управленческого решения, приводит к тому, что традиционные методы работы с документами становятся неэффективными. Так, по сведениям компании Delphi, 15% бумажных документов безвозвратно теряются и для их поиска сотрудники тратят до 30% своего рабочего времени. При переходе к электронным документам и автоматизации документооборота рост производительности [c.536]
К числу существенных перспектив совершенствования следующей стадии (этапа) учетного процесса — систематизации и группировки учетной информации — следует отнести поиск и применение наиболее рациональных форм учетных регистров, в первую очередь машинограмм в целях более совершенного формирования учетной информации для контроля, экономического анализа и управления. К этой проблеме тесно примыкают вопросы более тесной связи бухгалтерского учета с другими видами учета, достижения наиболее полного единства показателей планирования и учета, автоматизации всех трудоемких операций технологического процесса механизированной обработки информации, наиболее полного сочетания методологических и организационных принципов учета и условий механизации и автоматизации учетно-вычисли-тельных работ. [c.47]
Третьим вариантом обеспечения сверки складского и бухгалтерского учета является его автоматизация с использованием ЭВМ. При этом карточки складского учета, ведущиеся вручную, в конце месяца или на дату инвентаризации передаются на вычислительную установку, где данные за отчетный период перфорируются, вводятся в ЭВМ и автоматически сравниваются с остатками товаров на соответствующую дату, сформированными при решении задачи учета наличия и движения товаров в натурально-стоимостном выражении. Вначале сравнению подлежат остатки товаров в разрезе товарных групп внутри склада. При несовпадении остатков товаров на уровне групп сопоставляется информация на уровне номенклатурных единиц товара. Выявленные расхождения распечатываются в специальной ведомости, содержащей информацию номер склада, дату сверки, код товара, цену, остаток продукции в натурально-стоимостном измерении по данным карточки складского учета и числящейся по учетным данным в ЭВМ, номер приходного или расходного документа, отклонения по остаткам товаров. Таким образом, поиск ошибки и ее идентификацию осуществляет ЭВМ. Бухгалтер исправляет ошибку и анализирует причины установленного несоответствия. [c.145]
САЦНТИ) все более широко используются устройства, обеспечивающие удаленный доступ к базам данных всесоюзных, центральных отраслевых и республиканских органов НТИ. Для этого могут применяться устройства с визуальным отображением информации на экране (дисплеи), например ЕС 7920, или мини- и микро-ЭВМ, которые в настоящее время осваиваются и выпускаются нашей промышленностью (например, Иск-ра-226 ). Мини- и микро-ЭВМ могут быть использованы также для автоматизации основных библиотечно-инфор-мационных процессов комплектования (проверки на дублетность заказанных книг составления перечней заказанной литературы учета новых поступлений) подготовки печатных каталогов учета и отчетности подготовки информационных бюллетеней новых поступлений и вспомогательных указателей тематического поиска в режиме ИРИ и справочно-информационного обслуживания в режиме запрос—ответ . [c.121]
72,1% бесплатных материалов
968 руб. средняя цена курсовой работы
353 руб. средняя цена домашнего задания
116 руб. средняя цена решённой задачи
161 руб. средняя цена лабораторной работы
174 руб. средняя цена реферата
177 руб. средняя цена доклада
1626 руб. средняя цена ВКР
665 руб. средняя цена диссертации
596 руб. средняя цена НИР
358 руб. средняя цена отчёта по практике
276 руб. средняя цена ответов (шпаргалок)
202 руб. средняя цена лекций
232 руб. средняя цена семинаров
280 руб. средняя цена рабочей тетради
187 руб. средняя цена презентации
67 руб. средняя цена перевода
143 руб. средняя цена изложения
150 руб. средняя цена сочинения
308 руб. средняя цена статьи
Гарантия возврата средств