I was learning more about header guards in C++ from here. One of the paragraphs there said:
Even the standard library includes use header guards. If you were to
take a look at the iostream header file from Visual Studio, you would
see:#ifndef _IOSTREAM_ #define _IOSTREAM_ // content here #endif
I’m interested in finding the iostream header file to see this header guard myself and to learn more about how C++ directories are structured to find files like these. I had a working C++ project in Visual Studio 2015, and in the project directory I tried dir *iostream* /s in cmd, but I didn’t find anything. How can I find the iostream header file in a Visual Studio 2015 project if it’s accessible?
asked Oct 27, 2016 at 23:31
![]()
1
iostream is not part of your project. It’s part of c++ standard library. How about searching your HDD for it?
answered Oct 27, 2016 at 23:35
![]()
LehuLehu
7514 silver badges14 bronze badges
2
The header <iostream.h> is an antiquated header from before C++ became standardized as ISO C++ 1998 (it is from the C++ Annotated Reference Manual). The standard C++ header is <iostream>. There are some minor differences between the two, with the biggest difference being that <iostream> puts the included contents in namespace std, so you have to qualify cin, cout, endl, istream, etc. with «std::». As somewhat of a hack (it is a hack because header files should never contain «using» directives as they completely defeat the purpose of namespaces), you could define «iostream.h» as follows:
#ifndef HEADER_IOSTREAM_H
#define HEADER_IOSTREAM_H
#include <iostream>
using namespace std; // Beware, this completely defeats the whole point of
// having namespaces and could lead to name clashes; on the
// other hand, code that still includes <iostream.h> was
// probably created before namespaces, anyway.
#endif
While this is not exactly identical to the original antiquated header, this should be close enough for most purposes (i.e. there should be either nothing or very few things that you will have to fix).
Добавлено 12 апреля 2021 в 19:00
Заголовки и их назначение
По мере того, как программы становятся больше (и используют больше файлов), становится всё более утомительным давать предварительные объявления каждой функции, которую вы хотите использовать, и которая определена в другом файле. Было бы неплохо, если бы вы могли поместить все свои предварительные объявления в одно место, а затем импортировать их, когда они вам понадобятся?
Исходные файлы кода C++ (с расширением .cpp) – это не единственные файлы, которые обычно встречаются в программах на C++. Другой тип файлов – это заголовочный файл (иногда просто заголовок). Заголовочные файлы обычно имеют расширение .h, но иногда вы можете встретить их с расширением .hpp или вообще без расширения. Основная цель заголовочного файла – распространять объявления в исходные файлы кода.
Ключевой момент
Заголовочные файлы позволяют нам размещать объявления в одном месте, а затем импортировать их туда, где они нам нужны. Это может сэкономить много времени при наборе текста в проектах из нескольких файлов.
Использование заголовочных файлов стандартной библиотеки
Рассмотрим следующую программу:
#include <iostream>
int main()
{
std::cout << "Hello, world!";
return 0;
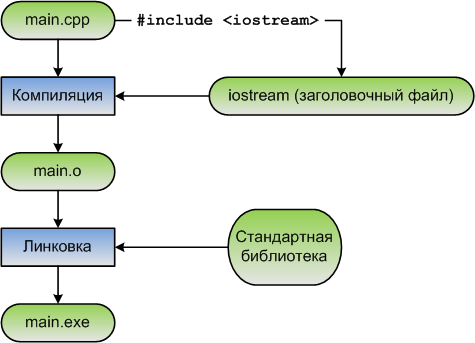
}Эта программа печатает «Hello, world!» в консоль с помощью std::cout. Однако эта программа никогда не предоставляла определение или объявление для std::cout, поэтому как компилятор узнает, что такое std::cout?
Ответ заключается в том, что std::cout был предварительно объявлен в заголовочном файле «iostream». Когда мы пишем #include <iostream>, мы запрашиваем, чтобы препроцессор скопировал всё содержимое (включая предварительные объявления для std::cout) из файла с именем «iostream» в файл, выполняющий #include.
Ключевой момент
Когда вы включаете файл с помощью #include, содержимое включаемого файла вставляется в точке включения. Это удобный способ извлечения объявлений из другого файла.
Подумайте, что бы произошло, если бы заголовок iostream не существовал. Каждый раз, когда вы хотели бы использовать std::cout, вам приходилось бы вручную вводить или копировать все объявления, связанные с std::cout, в начало каждого файла, который использовал бы std::cout! Для этого потребуется много знаний о том, как реализован std::cout, и потребуется много работы. Хуже того, если бы прототип функции изменился, нам пришлось бы вручную обновлять все предварительные объявления. Намного проще просто включить iostream с помощью #include!
Когда дело доходит до функций и переменных, стоит помнить, что заголовочные файлы обычно содержат только объявления функций и переменных, а не их определения (в противном случае может произойти нарушение правила одного определения). std::cout объявлен в заголовке iostream, но определен как часть стандартной библиотеки C++, которая автоматически подключается к вашей программе на этапе линкера.
Лучшая практика
Заголовочные файлы обычно не должны содержать определений функций и переменных, чтобы не нарушать правило одного определения. Исключение сделано для символьных констант (которые мы рассмотрим в уроке «4.14 – const, constexpr и символьные константы»).
Написание собственных заголовочных файлов
А теперь вернемся к примеру, который мы обсуждали в предыдущем уроке. Когда мы закончили, у нас было два файла, add.cpp и main.cpp, которые выглядели так:
add.cpp:
int add(int x, int y)
{
return x + y;
}main.cpp:
#include <iostream>
int add(int x, int y); // предварительное объявление с использованием прототипа функции
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << 'n';
return 0;
}(Если вы воссоздаете этот пример с нуля, не забудьте добавить add.cpp в свой проект, чтобы он компилировался).
В этом примере мы использовали предварительное объявление, чтобы при компиляции main.cpp компилятор знал, что такое идентификатор add. Как упоминалось ранее, добавление предварительных объявлений для каждой функции, которую вы хотите использовать, и которая находится в другом файле, вручную может быстро стать утомительным.
Давайте напишем заголовочный файл, чтобы избавиться от этого бремени. Написать заголовочный файл на удивление легко, поскольку файлы заголовков состоят только из двух частей:
- защита заголовка, о которой мы поговорим более подробно в следующем уроке («2.11 – Защита заголовков»);
- фактическое содержимое файла заголовка, которое должно быть предварительными объявлениями для всех идентификаторов, которые мы хотим, чтобы другие файлы могли видеть.
Добавление заголовочного файла в проект работает аналогично добавлению исходного файла (рассматривается в уроке «2.7 – Программы с несколькими файлами исходного кода»). Если вы используете IDE, выполните такие же действия и при появлении запроса выберите Файл заголовка (или C/C++ header) вместо Файла С++ (или C/C++ source). Если вы используете командную строку, просто создайте новый файл в своем любимом редакторе.
Лучшая практика
При именовании файлов заголовков используйте расширение .h.
Заголовочные файлы часто идут в паре с файлами исходного кода, при этом заголовочный файл предоставляет предварительные объявления для соответствующего исходного файла. Поскольку наш заголовочный файл будет содержать предварительное объявление для функций, определенных в add.cpp, мы назовем наш новый заголовочный файл add.h.
Лучшая практика
Если заголовочный файл идет в паре с файлом исходного кода (например, add.h с add.cpp), они оба должны иметь одинаковое базовое имя (add).
Вот наш завершенный заголовочный файл:
add.h:
// 1) У нас здесь на самом деле должна быть защита заголовка,
// но для простоты мы опустим ее (мы рассмотрим защиту заголовков в следующем уроке)
// 2) Это содержимое файла .h, где идут объявления
int add(int x, int y); // прототип функции для add.h - не забудьте точку с запятой!Чтобы использовать этот заголовочный файл в main.cpp, мы должны включить его с помощью #include (используя кавычки, а не угловые скобки).
main.cpp:
#include <iostream>
// Вставляем содержимое add.h в этот момент.
// Обратите внимание на использование здесь двойных кавычек.
#include "add.h"
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << 'n';
return 0;
}add.cpp:
int add(int x, int y)
{
return x + y;
}Когда препроцессор обрабатывает строку #include "add.h", он копирует содержимое add.h в текущий файл в эту точку. Поскольку наш add.h содержит предварительное объявление для функции add, это предварительное объявление будет скопировано в main.cpp. Конечным результатом является программа, которая функционально аналогична той, в которой мы вручную добавили предварительное объявление вверху main.cpp.
Следовательно, наша программа будет правильно компилироваться и компоноваться.
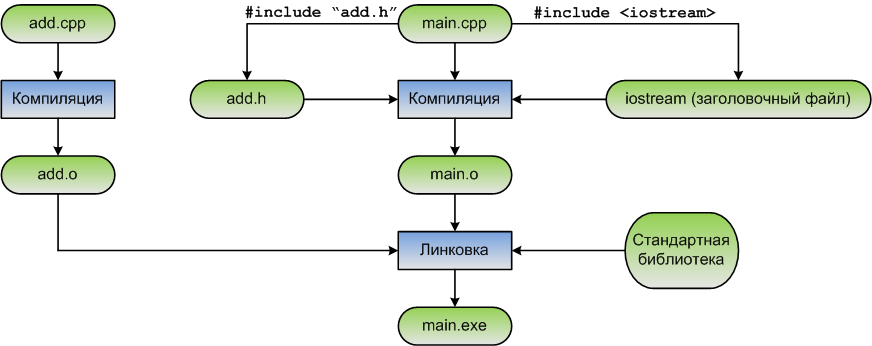
Включение заголовочного файла в соответствующий исходный файл
Позже вы увидите, что большинство исходных файлов включают свой соответствующий заголовочный файл, даже если он им не нужен. Зачем?
Включение заголовочного файла в исходный файл увеличивает прямую совместимость. Очень вероятно, что в будущем вы добавите больше функций или измените существующие таким образом, что им нужно будет знать о существовании друг друга.
Когда мы углубимся в изучение стандартной библиотеки, вы будете включать множество заголовочных файлов библиотек. Если вам потребовалось включение в заголовочном файле, оно, вероятно, понадобилось вам для объявления функции. Это означает, что вам также потребуется такое же включение в исходный файл. Это приведет к тому, что в исходном файле у вас будет копия включений заголовочного файла. Включив заголовочный файл в исходный файл, исходный файл получит доступ ко всему, к чему имел доступ заголовочный файл.
При разработке библиотеки включение заголовочного файла в исходный файл может даже помочь в раннем обнаружении ошибок.
Лучшая практика
При написании исходного файла включите в него соответствующий заголовочный файл (если он существует), даже если он вам пока не нужен.
Поиск и устранение проблем
Если вы получаете ошибку компилятора, указывающую, что add.h не найден, убедитесь, что файл действительно называется add.h. В зависимости от того, как вы его создали и назвали, возможно, файл может иметь имя вроде add (без расширения), add.h.txt или add.hpp. Также убедитесь, что он находится в том же каталоге, что и остальные исходные файлы.
Если вы получаете сообщение об ошибке компоновщика о том, что добавление функции не определено, убедитесь, что вы добавили в проект файл add.cpp, чтобы определение для функции add можно было слинковать в программе.
Угловые скобки и двойные кавычки
Вам, наверное, интересно, почему мы используем угловые скобки для iostream и двойные кавычки для add.h. Возможно, что заголовочные файлы с таким же именем могут существовать в нескольких каталогах. Использование угловых скобок и двойных кавычек помогает компилятору понять, где ему следует искать заголовочные файлы.
Когда мы используем угловые скобки, мы сообщаем препроцессору, что это заголовочный файл, который мы не писали сами. Компилятор будет искать заголовок только в каталогах, указанных в каталогах включаемых файлов (include directories). Каталоги включаемых файлов настраиваются как часть вашего проекта / настроек IDE / настроек компилятора и обычно по умолчанию используются для каталогов, содержащих заголовочные файлы, которые поставляются с вашим компилятором и/или ОС. Компилятор не будет искать заголовочный файл в каталоге исходного кода вашего проекта.
Когда мы используем двойные кавычки, мы сообщаем препроцессору, что это заголовочный файл, который написали мы. Компилятор сначала будет искать этот заголовочный файл в текущем каталоге. Если он не сможет найти там подходящий заголовочный файл, он будет искать его в каталогах включаемых файлов.
Правило
Используйте двойные кавычки, чтобы включать заголовочные файлы, которые написали вы или которые, как ожидается, будут найдены в текущем каталоге. Угловые скобки используйте, чтобы включать заголовочные файлы, которые поставляются с вашим компилятором, ОС или сторонними библиотеками, которые вы установили в другом месте своей системы.
Почему у iostream нет расширения .h?
Другой часто задаваемый вопрос: «Почему iostream (или любой другой заголовочный файл стандартной библиотеки) не имеет расширения .h?». Ответ заключается в том, что iostream.h – это другой заголовочный файл, отличающийся от iostream! Для объяснения требуется небольшой урок истории.
Когда C++ был только создан, все файлы в стандартной библиотеке оканчивались расширением .h. Жизнь была последовательной, и это было хорошо. Исходные версии cout и cin были объявлены в iostream.h. Когда комитет ANSI стандартизировал язык, они решили переместить все функции стандартной библиотеки в пространство имен std, чтобы избежать конфликтов имен с пользовательскими идентификаторами. Однако это представляло проблему: если бы они переместили всю функциональность в пространство имен std, ни одна из старых программ (включая iostream.h) больше не работала бы!
Чтобы обойти эту проблему, был представлен новый набор заголовочных файлов, которые используют те же имена, но не имеют расширения .h. Все функции в этих новых заголовочных файлах находятся в пространстве имен std. Таким образом, старые программы, содержащие #include <iostream.h>, не нужно переписывать, а новые программы могут использовать #include <iostream>.
Кроме того, многие библиотеки, унаследованные от C, которые всё еще используются в C++, получили префикс c (например, stdlib.h стал cstdlib). Функциональные возможности этих библиотек также были перенесены в пространство имен std, чтобы избежать конфликтов имен.
Лучшая практика
При включении заголовочного файла из стандартной библиотеки используйте версию без расширения (без .h), если она существует. Пользовательские заголовочные файлы по-прежнему должны использовать расширение .h.
Включение заголовочных файлов из других каталогов
Другой распространенный вопрос связан с тем, как включать заголовочные файлы из других каталогов.
Один (плохой) способ сделать это – добавить относительный путь к заголовочному файлу, который вы хотите включить как часть строки #include. Например:
#include "headers/myHeader.h"
#include "../moreHeaders/myOtherHeader.h"Хотя это будет компилироваться (при условии, что файлы существуют в этих относительных каталогах), обратная сторона этого подхода состоит в том, что он требует от вас отражения структуры каталогов в вашем коде. Если вы когда-нибудь обновите структуру каталогов, ваш код больше не будет работать.
Лучший способ – сообщить вашему компилятору или IDE, что у вас есть куча заголовочных файлов в каком-то другом месте, чтобы он смотрел туда, когда не может найти их в текущем каталоге. Обычно это можно сделать, установив путь включения (include path) или каталог поиска (search directory) в настройках проекта в IDE.
Для пользователей Visual Studio
Кликните правой кнопкой мыши на своем проекте в обозревателе решений и выберите Свойства (Properties), затем вкладку Каталоги VC++.(VC++ Directories). Здесь вы увидите строку с названием «Включаемые каталоги» (Include Directories). Добавьте каталоги, в которых компилятор должен искать дополнительные заголовочные файлы.
Для пользователей Code::Blocks
В Code:: Blocks перейдите в меню Project (Проект) и выберите Build Options (Параметры сборки), затем вкладку Search directories (Каталоги поиска). Добавьте каталоги, в которых компилятор должен искать дополнительные заголовочные файлы.
Для пользователей GCC/G++
Используя g++, вы можете использовать параметр -I, чтобы указать альтернативный каталог для включения.
g++ -o main -I/source/includes main.cppХороший момент в этом подходе заключается в том, что если вы когда-нибудь измените структуру каталогов, вам нужно будет изменить только одну настройку компилятора или IDE, а не каждый файл кода.
Заголовочные файлы могут включать другие заголовочные файлы
Обычно для заголовочных файлов требуется объявление или определение, которое находится в другом заголовочном файле. Из-за этого заголовочные файлы часто включают с помощью #include другие заголовочные файлы.
Когда ваш исходный файл включает с помощью #include первый заголовочный файл, вы также получите любые другие заголовочные файлы, которые были включены в первый заголовочный файл (и любые заголовочные файлы, которые были включены в предыдущие, и т.д.). Эти дополнительные заголовочные файлы иногда называют «транзитивными включениями», поскольку они включаются неявно.
Содержимое этих транзитивных включений доступно для использования в вашем файле исходного кода. Однако не следует полагаться на содержимое заголовков, которые включены транзитивно. Реализация заголовочных файлов может со временем меняться или отличаться в разных системах. Если это произойдет, ваш код может компилироваться только на определенных системах или может компилироваться сейчас, но перестать в будущем. Этого легко избежать, явно включив все заголовочные файлы, необходимые для содержимого вашего файла исходного кода.
Лучшая практика
Каждый файл должен явно включать с #include все заголовочные файлы, необходимые для компиляции. Не полагайтесь на заголовочные файлы, включенные транзитивно из других заголовков.
К сожалению, нет простого способа определить, полагается ли ваш файл кода случайно на содержимое заголовочного файла, который был включен другим заголовочным файлом.
Вопрос: Я не включил <someheader.h>, и моя программа всё равно работала! Почему?
Это один из наиболее часто задаваемых вопросов. Ответ: скорее всего, он работает, потому что вы включили какой-то другой заголовок (например, <iostream>), который сам включает <someheader.h>. Несмотря на то, что ваша программа будет компилироваться, в соответствии с приведенными выше рекомендациями вам не следует полагаться на это. То, что компилируется у вас, может не компилироваться на машине друга.
Порядок #include заголовочных файлов
Если ваши заголовочные файлы написаны правильно и включают с #include всё, что им нужно, порядок включения не имеет значения. Однако включение заголовочных файлов в определенном порядке может помочь выявить ошибки, когда заголовочные файлы могут не включать в себя всё, что им нужно.
Лучшая практика
Упорядочьте свои включения с #include следующим образом: сначала ваши собственные пользовательские заголовки, затем заголовки сторонних библиотек, затем заголовки стандартных библиотек; заголовки в каждом разделе должны быть отсортированы в алфавитном порядке.
Таким образом, если в одном из ваших пользовательских заголовков отсутствует #include для заголовка сторонней библиотеки или стандартной библиотеки, это с большей вероятностью вызовет ошибку компиляции, чтобы вы могли ее исправить.
Рекомендации по использованию заголовочных файлов
Вот еще несколько рекомендаций по созданию и использованию заголовочных файлов.
- Всегда включайте защиту заголовков (мы рассмотрим это в следующем уроке).
- Не определяйте переменные и функции в файлах заголовков (глобальные константы являются исключением – мы рассмотрим их позже)
- Давайте файлам заголовков те же имена, что и исходным файлам, с которыми они связаны (например, grades.h идет в паре с grades.cpp).
- Каждый заголовочный файл должен иметь конкретное назначение и быть максимально независимым. Например, вы можете поместить все объявления, относящиеся к функциональности
A, в A.h, а все объявления, относящиеся к функциональностиB, в B.h. Таким образом, если позже вам нужен будет толькоA, вы можете просто включить A.h и не получать ничего, связанного сB. - Учитывайте, какие заголовки вам нужно явно включить для функций, которые вы используете в своих файлах исходного кода.
- Каждый заголовок, который вы пишете, должен компилироваться сам по себе (он должен включать с
#includeвсе необходимые зависимости) - Включайте с
#includeтолько то, что вам нужно (не включайте всё только потому, что вы можете). - Не включайте с
#includeфайлы .cpp.
Теги
C++ / CppLearnCppДля начинающихОбучениеПрепроцессорПрограммирование
В этой главе мы напишем первую программу на C++ и научимся печатать и считывать с клавиатуры строки и числа.
Функция main
Пожалуй, самая простая и короткая программа на C++ — это программа, которая ничего не делает. Она выглядит так:
int main() {
return 0;
}
Здесь определяется функция с именем main, которая не принимает никаких аргументов (внутри круглых скобок ничего нет) и не выполняет никаких содержательных команд. В каждой программе на C++ должна быть ровно одна функция main — с неё начинается выполнение программы.
У функции указан тип возвращаемого значения int (целое число), и она возвращает 0 — в данном случае это сообщение для операционной системы, что программа выполнилась успешно. И наоборот, ненулевой код возврата означает, что при выполнении возникла ошибка (например, программа получила некорректные входные данные).
Для функции main разрешается не писать завершающий return 0, чем мы и будем пользоваться далее для краткости. Поэтому самую короткую программу можно было бы написать вот так:
int main() {
}
Hello, world!
Соблюдая традиции, напишем простейшую программу на C++ — она выведет приветствие в консоль:
#include <iostream>
int main() {
std::cout << "Hello, world!n";
return 0;
}
Разберём её подробнее.
Директива #include <iostream> подключает стандартный библиотечный заголовочный файл для работы с потоками ввода-вывода (input-output streams). Для печати мы используем поток вывода std::cout, где cout расшифровывается как character output, то есть «символьный вывод».
В теле функции main мы передаём в std::cout строку Hello, world! с завершающим переводом строки n. В зависимости от операционной системы n будет преобразован в один или в два управляющих байта с кодами 0A или 0D 0A соответственно.
Инструкции внутри тела функции завершаются точками с запятой.
Компиляция из командной строки
Вы можете запустить эту программу из какой-нибудь IDE. Мы же покажем, как собрать её в консоли Linux с помощью компилятора clang++.
Пусть файл с программой называется hello.cpp. Запустим компилятор:
$ clang++ hello.cpp -o hello
В результате мы получим исполняемый файл с именем hello, который теперь можно просто запустить. Он напечатает на экране ожидаемую фразу:
$ ./hello Hello, world!
Если опцию -o не указать, то сгенерированный исполняемый файл будет по умолчанию назван a.out. В дальнейшем для простых примеров мы будем использовать краткую форму записи команды:
$ clang++ hello.cpp && ./a.out Hello, world!
С её помощью мы компилируем программу и в случае успеха компиляции сразу же запускаем.
Комментарии
Комментарии — это фрагменты программы, которые игнорируются компилятором и предназначены для программиста. В C++ есть два вида комментариев — однострочные и многострочные:
int main() { // однострочный комментарий продолжается до конца строки
/* Пример
многострочного
комментария */
}
Мы будем использовать комментарии в примерах кода для пояснений, а в реальных программах ими лучше не злоупотреблять.
Хорошо: комментировать, что делает библиотека, функция или класс или почему этот код написан именно так.
Плохо: комментировать, что происходит на отдельной строчке. Это признак того, что код можно написать лучше.
Библиотеки и заголовочные файлы
Библиотека — это код, который можно переиспользовать в разных программах. В стандарт языка C++ входит спецификация так называемой стандартной библиотеки, которая поставляется вместе с компилятором. Она содержит различные структуры данных (контейнеры), типовые алгоритмы, средства ввода-вывода и т. д. Конструкции из этой библиотеки предваряются префиксом std::, который обозначает пространство имён.
Чтобы воспользоваться теми или иными библиотечными конструкциями, в начале программы надо подключить нужные заголовочные файлы. Так, в программе, которая печатала Hello, world!, нам уже встречался заголовочный файл iostream и конструкция std::cout из стандартной библиотеки.
Для C++ существует также множество сторонних библиотек. Наиболее известной коллекцией сторонних библиотек для C++ является Boost.
Ошибки компиляции
Перед запуском программу необходимо скомпилировать. Компилятор проверяет корректность программы и генерирует исполняемый файл. Во время компиляции компилятор может обнаружить синтаксические ошибки.
Рассмотрим пример такой программы:
#include <iostream>
int main() {
cout << "Hello, worldn"
Компилятор может выдать такие сообщения:
$ clang++ hello.cpp
hello.cpp:4:5: error: use of undeclared identifier 'cout'; did you mean 'std::cout'?
cout << "Hello, world!n"
^~~~
std::cout
hello.cpp:4:30: error: expected ';' after expression
cout << "Hello, world!n"
^
;
hello.cpp:5:1: error: expected '}'
^
a.cpp:3:12: note: to match this '{'
int main() {
^
3 errors generated.
Первая ошибка — вместо std::cout мы написали cout. Вторая ошибка — не поставили точку запятой после "Hello, world!n". Наконец, третья – не закрыли фигурную скобку с телом функции.
Ошибки компиляции (compile errors) следует отличать от возможных ошибок времени выполнения (runtime errors), которые происходят после запуска программы и, как правило, зависят от входных данных, неизвестных во время компиляции.
Отступы и оформление кода
Фрагменты программы на C++ могут быть иерархически вложены друг в друга. На верхнем уровне находятся функции, внутри них написаны их тела, в теле могут быть составные операторы, и так далее.
Среди программистов есть соглашение — писать внутренние блоки кода с отступами вправо: компилятор полностью игнорирует эти отступы, а код читать удобнее. Мы будем использовать отступы в четыре пробела. Также мы будем придерживаться стиля оформления кода, принятого в Яндексе. Имена переменных мы будем писать с маленькой буквы, имена функций и классов — с большой (если речь не идёт о конструкциях стандартной библиотеки, где действуют другие соглашения).
Переменные
Любая содержательная программа так или иначе обрабатывает данные в памяти. Переменная — это именованный блок данных определённого типа. Чтобы определить переменную, нужно указать её тип и имя. В общем виде это выглядит так:
Type name;
где вместо Type — конкретный тип данных (например, строка или число), а вместо name — имя переменной. Имена переменных должны состоять из латинских букв, цифр и знаков подчёркивания и не должны начинаться с цифры. Также можно в одной строке определить несколько переменных одного типа:
Type name1 = value1, name2 = value2, name3 = value3;
Например:
#include <string> // библиотека, в которой определён тип std::string
int main() {
// Определяем переменную value целочисленного типа int
int value;
// Определяем переменные name и surname типа std::string (текстовая строка)
std::string name, surname;
}
В этом примере мы используем встроенный в язык тип int (от слова integer — целое число) и поставляемый со стандартной библиотекой тип std::string. (Можно было бы использовать для строк встроенный тип с массивом символов, но это неудобно.)
Тип переменной должен быть известен компилятору во время компиляции.
От типа зависит:
- сколько байтов памяти потребуется для хранения данных;
- как интерпретировать эти байты;
- какие операции с этой переменной возможны.
Например, переменной типа int можно присваивать значения и с ней можно производить арифметические операции. Подробнее про разные типы данных и их размер в памяти мы поговорим ниже.
Важно понимать, что тип остаётся с переменной навсегда. Например, присвоить целочисленной переменной строку не получится — это вызовет ошибку компиляции:
int main() {
int value;
value = 42; // OK
value = "Hello!"; // ошибка компиляции!
}
Переменные можно сразу проинициализировать значением. В С++ есть много разных способов инициализации. Нам пока будет достаточно способа, который называется copy initialization:
#include <string>
int main() {
int value = 42;
std::string title = "Bjarne Stroustrup";
}
Если переменная, была объявлена, но нигде дальше не использовалась, то компилятор выдаёт об этом предупреждение. При проверке решений мы используем опцию -Werror, которая считает предупреждения компилятора ошибками компиляции.
Потоковый ввод и вывод
Поток — это абстракция для чтения и записи последовательности данных в форматированном виде.
Записывать данные можно на экран консоли, в файл, буфер в памяти или в строку. Считывать их можно с клавиатуры, из файла, из памяти. Причём с каждым таким «устройством» можно связать свой поток.
Важно, что потоки не просто пересылают байты памяти, а применяют форматированный человекочитаемый ввод-вывод. Например, числа печатаются и считываются в десятичной нотации, хотя в памяти компьютера они хранятся в двоичном виде.
В программе Hello, world! нам уже встречался поток вывода std::cout, по умолчанию связанный с экраном консоли. Познакомимся с потоком ввода std::cin, связанным с клавиатурой. Для его использования нужен тот же заголовочный файл iostream.
Рассмотрим программу, которая спрашивает имя пользователя и печатает персональное приветствие:
#include <iostream>
#include <string>
int main() {
std::string name; // объявляем переменную name
std::cout << "What is your name?n";
std::cin >> name; // считываем её значение с клавиатуры
std::cout << "Hello, " << name << "!n";
}
Обратите внимание на направление угловых скобок в этом примере — они условно показывают направление потока данных. При печати данные выводятся на экран, и стрелки направлены от текста к cout. При вводе данные поступают с клавиатуры, и стрелки направлены от cin к переменной.
В нашем примере в переменную name считается одно слово, которое будет выведено в ответном сообщении. Пример работы программы:
What is your name? Alice Hello, Alice!
Однако если ввести строку из нескольких слов с пробелами, то в name запишется только первое слово:
$ ./a.out What is your name? Alice Liddell Hello, Alice!
Дело в том, что cin читает поток данных до ближайшего пробельного разделителя (пробела, табуляции, перевода строки или просто конца файла). Чтобы считать в строковую переменную всю строчку целиком (не включая завершающий символ перевода строки), нужно использовать функцию std::getline из заголовочного файла string:
#include <iostream>
#include <string>
int main() {
std::string name;
std::getline(std::cin, name);
std::cout << "Hello, " << name << "!n";
}
В этом примере мы печатаем в одном выражении друг за другом несколько строк ("Hello, ", name и "!n"), разделённых угловыми скобками <<. Таким образом, cin и cout позволяют кратко считывать и печатать несколько объектов одной командой.
Например, считывание нескольких чисел целого типа, набранных через пробельные разделители, может выглядеть так:
int main() {
int a;
int b;
int c;
std::cin >> a >> b >> c;
}
Напечатать их значения можно следующим образом:
std::cout << a << " " << b << " " << c << "n";
Обратите внимание, что мы дополнительно вставляем между ними пробелы, чтобы в выводе числа не слиплись вместе. В конце вывода мы вставляем символ перевода строки n, чтобы отделить этот результат от последующего вывода или от сообщений командной строки.
Тот же вопрос, но все гораздо запущенней. Скачал и установил Visual Studio Professional 2017, Visual Studio Code, Распространяемый компонент Microsoft Visual C++ для Visual Studio 2017.
Первый урок Hello World^
| C++ | ||
|
И он не видит ни одной библиотеки (((
Выдает:
The system cannot find the file specified
А в проблемах для каждой из первых трех строк следующее:
message: ‘Include file not found in browse.path.’
at: ‘1,1’
Сразу пишу, что библиотек установленных на компе нет, через поиск их не находит, папки include тоже нет, где по идее все это должно храниться.
Где их взять эти библиотеки? Почему их нет после установки того, что я установил?