✅ В данной статье пойдет речь об актуальной проблеме на 2021 год -🔥 “Дубли страниц” на сайтах и в интернет магазинах. 🔥 Что делать если у вас одна запись или товар находится в разных категориях, но поисковые системы склеивают эти страницы и видят их как дубли. В данной статья я рассмотрю на примере своего блога под управлением WordPress, ✅ где с помощью тега canonical решил проблему дублей страниц.
Сегодня от яндекс вебмастера мне пришел еженедельный отчет после открытия которого я немного побелел, но как говорится нет дыма без огня и сейчас мы разберем очень актуальную тему которая на сегодняшний 2021 год закроет вопрос по дублям страниц!
В письме я увидел что недавние статьи которые я добавлял на сайт были удалены по причине Дубль
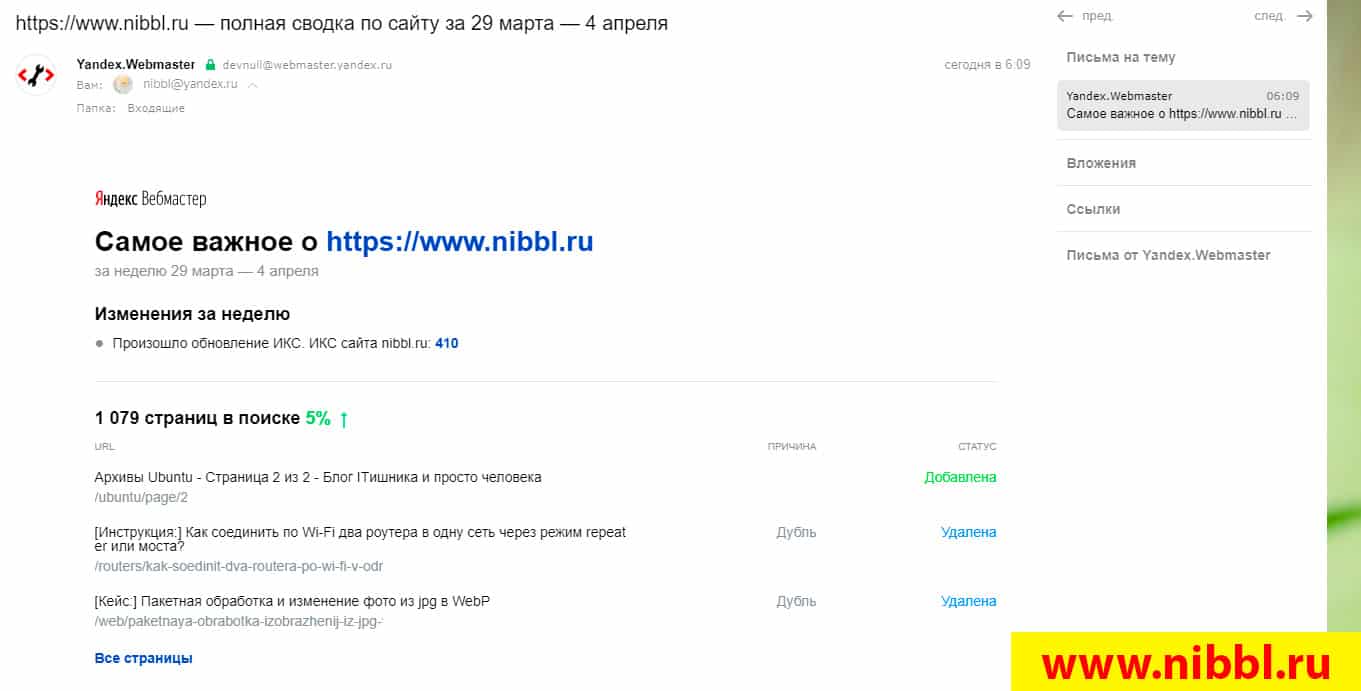
Отчет Яндекс Вебмастер
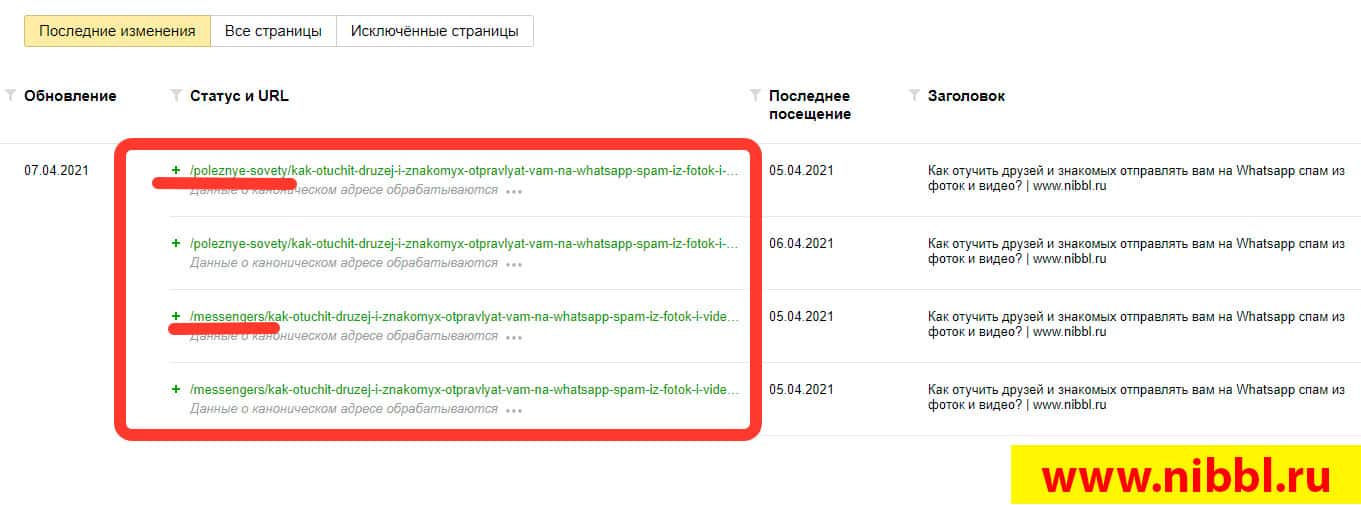
Я быстро пошел в Яндекс вебмастер и в разделе Страницы в поиске меня ждал еще один “сюрприз”. Несколько дней назад я опубликовал статью в которой рассказывал как отучить родных и близких отправлять вам в Whatsapp разные приколы которые отвлекают вас и одновременно засоряют телефон ненужным хламом!
В вебмастере эта статья проходила под двумя разными URL и имела неприятную запись:
Данные о каноническом адресе в процессе обработки. Они появятся в течение нескольких дней.
Как сделать основную категорию в WordPress
Самый прикол в том, что на данный момент в WordPress 5.7 при выборе нескольких категорий для материала вы можете принудительно указать какая категория будет основной. Я честно поверив в этот функционал и не додумавшись проверить это через код, думал до сегодняшнего дня, что если указать, что данная категория главная, все остальные будут ссылаться на нее как на основную, но как я ошибался(
В итоге получилось так, что с января когда я создал свой канал в Гугл новостях (мой канал) я каждую статью теперь добавляю дополнительно в раздел news которая транслируется у меня в Гугл новости (у меня есть статья где я рассказываю как добавить сайт в гугл новости ) и с того момента у меня все статьи которые имеют более одной категории не правильно индексируются поисковыми системами и я теряю трафик!!!!
Поиск дублей страниц на сайте
Дубли страниц – это страницы с разными URL адресами находящиеся в рамках одного домена которые имеют одинаковое содержимое.
Для того чтобы найти дубли страницы, как вы поняли достаточно просто зайти в раздел Записи и найти все статьи которые имеют более одной категории: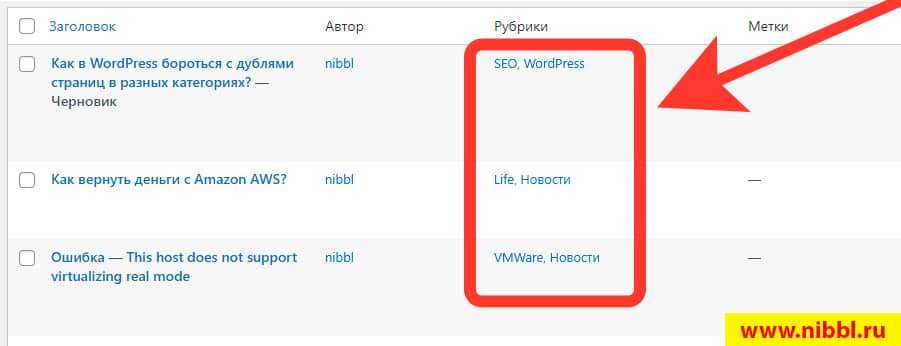
Как видите я не использую крауд программы такие как Screaming Frog SEO Spider или им подобные для поиска дублей страниц на сайте, а использую самую примитивную и очевидную технологию которая уже четыре месяца режет мне трафик на сайте(
Как убрать дубли страниц на сайте?
Большое кол-во дублей на сайте это не только возможность словить фильтр, но и запутать поискового робота который может повести себя не так как вы планируете.
Почему дубли страниц надо убирать? – самое опасное в дублях страниц это ухудшение ваших СЕО показателей при выдаче в серпе. Например, когда поисковые роботы объединяют несколько страниц с одним содержимым и привольно выбирают из них главную и эта рулетка будет постоянно.
Это приведет как минимум к скачкам позиций в поиске, как максимум к фильтру!
Для того чтобы убрать дубли, для любой CMS есть куча SEO плагинов или модулей которые как уверяют разработчики помогут с данной проблемой. (но в нашем случае лучше проверить и убедиться самому)
Убираем дули в WordPress
Я покажу технологию как убрать дубли на своем блоге под управление CMS WordPress но суть и смысл применим для любого сайта и интернет магазина.
Единственная палочка выручалочка для нас это использование тега canonical с помощью которого мы будет принудительно указывать главную категорию.
Что такое canonical – это специальный тег который имеет конструкцию <link rel=”canonical” href=”https://адрес_страницы” /> и говорит поисковой машине, что у данной страницы есть основная категория которая находится по такому то адресу. Данный тег используется в том случае если для страницы используется более одной категории.
Я на блоге недавно делал переезд с All In One Seo Pack на Yoast SEO и на сегодняшний день мой блог работает с СЕО плагином Yoast и с помощью его мы и будем бороться с дублями.
Главный секрет при борьбе с дублями на сайте – указываем принудительно каноническую страницу сами!
давайте все рассмотрим на примере этой статьи
- Мы пишем статью как бороться дублями
- в нашем сео плагине YOAST который предоставляет функционал ручного указания канонической страницы

- мы вставляем тот URL страницы какой мы хотим чтобы был основным для данной статьи. Данная статья у меня размещена в трех категориях: WordPress, SEO и Новости и после того как мы сами вручную указали для данной статьи канонический адрес на всех страницах с другими категориями она будет все равно указывать что у данной статьи есть основной канонический адрес.
- Указав канонический адрес мы решили огромную проблему с дублями.

Пример разбора с каноническими ссылками
т.е. рассмотрим для примера опять мою статью которую вы сейчас читаете, она находится в трех категориях
- www.nibbl.ru/wordpress/адрес_стать
- www.nibbl.ru/seo/адрес_стать
- www.nibbl.ru/news/адрес_стать
Статья будет доступна по трем адресам и если посмотреть код то у каждой будет стоять canonical на саму себя, т.е. каждая статья в своей категории будет считать, что она главная!
В этот момент приходит на нее паук от Яндекса или Гугла находит три одинаковых статьи и склеивает эти статьи в одну и сам назначает по своему усмотрению и выбирает допустим www.nibbl.ru/news/адрес_стать.
Потом приходит на сайт через месяц находит снова три страницы, а также на основе своих алгоритмов видит, что с момента первого индексирования в сети интернет кто то поделился ссылкой на данную статью в которой url категории /seo/ и теперь считает главную страницу www.nibbl.ru/seo/адрес_стать и меняет в поиске страницу. В этот момент ваш сайт мог быть на 5 позиции, а стал на 10 или 15 ))) и так вот у вас начинают скакать позиции сайта!
Вот таким нехитрым способом я наконец таки победил проблему дублей страниц на своем сайте, но эта же технология применима и для интернет магазинов с товарами, но там кончено все немного по другому наверное будет, но принцип тот же!
Видео инструкция
Итого
на этом я заканчиваю статью и надеюсь я полностью раскрыл тему на такие вопросы как:
- Что такое канонические страницы сайта?
- Как дубли страниц влияют на продвижение сайта?
- Как использовать тег Canonical на сайте и интернет магазине?
- Как найти и удалить дубли страниц?
- Как дубли влияют на ранжирование сайта в поиске?
И многие другие вопросы на эту тему! Вы можете поставить лайк или отписать коммент, а я пошел дальше колдовать над блогом чтобы вывести его к моей заветной цифре в 10 тыс уников в сутки!
Пока писал эту статью, на почту поступило приглашение поучаствовать в проводимом на сайте 9seo.ru марафоне по увеличению посещаемости сайта. Некоторое время я размышлял, что мне это может дать и как правильно поступить. В итоге решил, что со своим режимом дня и загруженностью на основной работе вряд ли смогу участвовать в интенсивной борьбе за призовые места. К тому же, основная моя цель – не обеспечение дохода стороннему ресурсу (участие в марафоне на 9seo стоит 999 рублей), а развитие собственных блогов на WordPress.
Поэтому буду набивать шишки и получать опыт продвижения в том ритме и с той скоростью, которую способен осилить. Возвращаюсь к собственному марафону, замечу, что для многих блогеров какая-то (возможно, подавляющая) часть шагов, которые я буду предпринимать и подробно описывать – этап давно пройденный. Так что, буду ориентироваться на то, что информация может оказаться полезной для новичков и профессиональных «чайников», пытающихся разобраться в теме «Развитие блога на WordPress». Итак, шаг первый:
Устранение дублей страниц
Оптимизация индексации – важная часть работ по внутренней оптимизации ресурса. Для роботов поисковых систем страницы с частично или полностью одинаковым содержанием и различающимися адресами представляют дублированный контент. По какой бы причине – недосмотру или халатности вебмастера – ни появились дубли страниц, их необходимо выявлять и устранять.
Неуникальный дублированный контент, кроме того, что не приносит блогу на WordPress особой пользы, еще и способствует занижению основных страниц сайта в поисковой выдаче и опасен наложением фильтров от ПС. Другой негативный момент заключается в том, что при дублировании страниц дублируются и ссылки, расположенные на них, следовательно, поисковики видят уже не одну ссылку с вашего блога, а столько, сколько найдено было дублей страницы.
Главный инструмент для борьбы с дубликатами – файл robots.txt, позволяющий исключать из поиска все ненужные страницы. В репозитории WordPress при желании можно найти различные плагины для выполнения этой задачи. Но мы легких путей не ищем, будем избавляться от мусора в поиске классическими методами.
Откуда берутся дубли страниц
Дубли в выдаче – результат архитектуры движка WordPress, особенностей формирования и представления информации в этой CMS. В оправдание WordPress можно лишь сказать, что эта болезнь преследует и другие системы управления контентом с динамическим представлением. Дубли могут быть как полными – когда страницы отличаются лишь адресом, так и неполными – когда контент на страницах дублируется частично. Источниками дублированного контента в WordPress служат теги, категории, RSS-лента, трэкбэки, комментарии, печатные версии страниц, неудачные реализации шаблонов.
Как найти дубли страниц на сайте
Проверить свой сайт на дубли страниц можно по-разному. Самый простой способ увидеть свой блог глазами поисковой системы – воспользоваться инструментами вебмастера от Гугл или Яндекс. Вот что показывал Яндекс Вебмастер до проведения работ по удалению дублей страниц.

Как видим, среди проиндексированного материала достаточно много мусора — при том, что основную часть дублей Яндекс отсеял самостоятельно.
Проверить дубли страниц онлайн в Google-поиске можно, вбив в строку поиска этой ПС запрос «site:mysite.ru – site:mysite.ru/&», подставив в него вместо mysite.ru адрес своего блога. Здесь, как на ладони, видно все неполные дубли и бесполезные страницы, которые мешают основным страницам блога ранжироваться выше.

Еще один способ проверки на дубли страниц – небольшая десктопная программа Xenu. Вбив адрес своего блога в специальном поле, достаточно быстро можно его проанализировать. Отфильтровав полученные результаты по заголовкам, можно будет визуально выделить дубли страниц. Но этим способом не удастся обнаружить частичные дубликаты.

Как избавиться от дублей страниц
Увидеть и осознать ситуацию – недостаточно, ее необходимо исправлять. Как убрать дубли страниц «легким движением руки»? Для этого существует простое и элегантное решение, о котором было сказано выше – файл robots.txt, позволяющий поставить запрет на индексацию всего того мусора, который вылезает в поиск.
Следует упомянуть, что robots.txt должен существовать в единственном экземпляре и размещаться в корне сайта – в папке на хостинге, в которой физически расположен ваш блог. Отсутствие файла robots.txt в корне блога на WordPress предполагает полное отсутствие ограничений на его индексацию. Создать этот файл можно в текстовом редакторе типа Notepad++, при этом необходимо соблюдать определенную структуру и синтаксис.
Настройка файла robots.txt для WordPress
В справке Яндекс Вебмастера собрана подробная информация о файле robots.txt. Дабы не повторять уже сказанное, отмечу кратко основные моменты.
Файл robots.txt предназначен исключительно для поисковых роботов, имеет текстовый формат и заполняется вебмастером на свой страх и риск директивами для этих роботов.
Основные директивы robots.txt:
User-agent – может содержать имя конкретного бота, для которого предназначены инструкции или * («звездочку»), если инструкции предназначены для всех. Поисковых роботов великое множество, у одного Яндекса их больше десятка, но в качестве значений директивы User-agent обычно указывают *, Yandex и Googlebot.
Allow разрешающая и Disallow запрещающая директивы, служащие для ограничения доступа поисковых роботов к контенту сайта. С их помощью можно ограничить доступ ко всему сайту, к отдельным его категориям или страницам. При конфликте между разрешающей и запрещающей директивой в пределах директивы User-agent приоритет имеет Allow.
Host – значением для этой директивы является имя главного зеркала сайта, например, доменное имя с www или без www. Эта директива добавляется непосредственно после директив Allow и Disallow. Некорректные директивы Host игнорируются роботами, причиной этого может стать элементарная ошибка – например, лишняя точка или пробел в имени сайта.
Sitemap – служит для указания пути к файлу, содержащему описание структуры сайта – к карте сайта. Поисковые роботы запоминают результаты обработки этой директивы и используют их при следующем сканировании.
Подробнее использование этих директив можно рассмотреть в приведенном ниже готовом файле robots.txt для сайта на WordPress.
Символ #, используемый в синтаксисе файла robots.txt, предназначен для написания комментариев для людей, информация после этого символа роботами не учитывается.
Мы запрещаем индексацию папок с темами и плагинами, запрещаем индексацию фида и кэша, запрещаем категории, теги, пагинацию. Но разрешаем индексацию папок с картинками. Во избежание недопонимания со стороны основных роботов Яндекса и Гугла, прописываем конкретные инструкции для каждого. Правильный файл robots.txt для WordPress в моем случае выглядит так:
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /download Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /download Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag Sitemap: http://vervekin.ru/sitemap.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /download Disallow: /category/ Disallow: /author/ Disallow: /page/ Disallow: /tag/ Host: vervekin.ru User-agent: YandexImages Allow: /wp-content/uploads/
Можно использовать его, заменив в нем все адреса адресами собственного блога. Другой простой вариант – позаимствовать готовый robots.txt у ресурса на WordPress, который высоко ранжируется поисковыми системами и которому вы доверяете – тоже с заменой данных на собственные. Увидеть robots.txt, если он имеется на сайте, легко. Для этого достаточно вбить в адресной строке браузера: mysite.ru/robots.txt (подставив вместо mysite.ru нужный адрес).
Файл .htaccess и дубли страниц
Убрать дубли можно и через файл .htaccess в корне сайта, прописав 301-й редирект с неуникальных «хвостов» на «чистые» адреса страниц. Об этом есть топик практически на каждом seo-форуме. Поэтому, чтобы не изобретать велосипед, возьмем готовый файл .htaccess для устранения дублей в WordPress. Выглядит он так:
# BEGIN WordPress
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule (.+)/feed /$1 [R=301,L]
RewriteRule (.+)/comment-page /$1 [R=301,L]
RewriteRule (.+)/trackback /$1 [R=301,L]
RewriteRule (.+)/comments /$1 [R=301,L]
RewriteRule (.+)/attachment /$1 [R=301,L]
RewriteCond %{QUERY_STRING} ^attachment_id= [NC]
RewriteRule (.*) $1? [R=301,L]
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
Дополнительные шаги для избавления от дублей страниц
В Инструментах Вебмастера Google выбираем раздел «Сканирование — Параметры URL«. Значение параметра replytocom следует в соответствии с показанными на рисунке ниже. Это даст указание Гуглу не индексировать частичные дубли страниц.



Осталось применить изменения, сделанные в Google Webmaster Tools, закачать оба созданных файла (robots.txt и .htaccess) в корень сайта и дожидаться поисковых роботов.
Расскажите об этой статье в соцсетях:
Дубли страниц — это страницы, где похожая или полностью повторяющаяся информация доступна по разным URL-адресам. Это плохо для SEO, так как поисковые системы могут снизить ранг сайта за неуникальность контента, а также разбросать вес ссылок между дублирующими страницами. Кроме того, дубли могут сбивать с толку пользователей и ухудшать конверсию сайта. В этой статье мы расскажем, какие бывают дубли страниц, как их обнаружить и как с ними бороться с помощью различных методов.
Оглавление
- 1 Какие бывают дубли страниц на сайте
- 2 Как обнаружить дубли на сайте
- 3 Как бороться с дублями страниц на WordPress
- 3.1 Используйте плагины для управления дублями
- 3.2 Настройте перенаправления в файле .htaccess
- 3.3 Запретите индексацию дублирующих страниц
- 3.4 Следите за структурой и навигацией сайта
Какие бывают дубли страниц на сайте
Дубли страниц бывают полными и частичными. Полные дубли — это страницы, которые полностью совпадают по содержанию и доступны по разным URL-адресам. Частичные дубли — это страницы, которые совпадают на 80% и более.
Самые распространенные типы дублей страниц на сайте:
- Два сайта с разными доменными именами, один из которых начинается на www, а другой — нет. Например: https://example.com и https://www.example.com
- Дубли страниц с протоколами http и https. Например: http://example.com и https://example.com
- Два разных файла с HTML разметкой. Например: https://example.com/index.html и https://example.com/home.html
- Страницы с обратным слешем и без. Например: https://example.com/page и https://example.com/page/
- Дубликаты с множественными слешами в середине либо в конце URL-адреса. Например: https://example.com/page// или https://example.com///
- Дубли в верхнем и нижнем регистре. Например: https://example.com/page и https://example.com/PAGE
- Страницы с разными параметрами в URL. Например: https://example.com/page?sort=asc и https://example.com/page?sort=desc
Как обнаружить дубли на сайте
Для поиска дублей на сайте можно использовать различные инструменты, например:
- Вебмастер Яндекс и Google Search Console — позволяют увидеть, какие страницы сайта проиндексированы поисковиками и какие из них являются дублями.
- Сервисы для проверки уникальности текстов — позволяют сравнить контент двух или нескольких страниц и определить процент совпадения. Например: Advego Plagiatus или Text.ru.
- Сервисы для проверки сайта на дубли онлайн — позволяют найти дубликаты страниц по разным адресам URL, например: Liftweb.
WordPress — одна из самых популярных CMS для создания сайтов и блогов. Однако, как и любая другая система, она не застрахована от появления дублей страниц, которые могут негативно сказаться на SEO и пользовательском опыте. Как же найти и устранить дубли на WordPress? Вот несколько советов:
Используйте плагины для управления дублями
Самый простой и удобный способ бороться с дублями на WordPress — это использовать специальные плагины, которые помогут вам обнаружить и устранить дублирующие страницы. Например, вы можете использовать такие плагины:
- Yoast SEO — один из самых популярных и мощных плагинов для SEO-оптимизации сайта на WordPress. С его помощью вы можете не только настраивать мета-теги, карту сайта, хлебные крошки и другие параметры, но и убирать дубли страниц с помощью атрибута rel=»canonical». Также вы можете указать канонический URL для каждой страницы вручную в редакторе записей или страниц.
- All In One SEO Pack — еще один популярный плагин для SEO-оптимизации сайта на WordPress. Он также позволяет вам убирать дубли страниц с помощью атрибута rel=»canonical». Также вы можете указать канонический URL для каждой страницы вручную в редакторе записей или страниц.
Настройте перенаправления в файле .htaccess
Если вы не хотите использовать плагины или хотите иметь больше контроля над перенаправлениями, вы можете настроить 301 редиректы в файле .htaccess, который находится в корневой папке вашего сайта. В этом файле вы можете прописать различные правила для перенаправления URL-адресов. Например, если вы хотите перенаправить все страницы с www на без www, то вы можете добавить такой код:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.site.ru [NC]
RewriteRule ^(.*)$ https://site.ru/$1 [L,R=301]Если вы хотите перенаправить все страницы с http на https, то вы можете добавить такой код:
RewriteEngine On
RewriteCond %{HTTPS} off
RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]Если вы хотите перенаправить конкретную страницу на другую, то вы можете добавить такой код:
Redirect 301 /old-page https://site.ru/new-pageЗапретите индексацию дублирующих страниц
Еще один способ борьбы с дублями на WordPress — это запретить поисковым системам индексировать дублирующие страницы с помощью специальных мета-тегов или файла robots.txt. Например, если вы хотите запретить индексацию всех страниц с параметрами, например, replytocom, sortby и т.д., то вы можете добавить в тег каждой страницы мета-тег robots со значением noindex. Например:
<meta name=“robots” content=“noindex” />
Таким образом, вы сообщаете поисковикам, что эти страницы не нужно индексировать и показывать в результатах поиска. Добавить этот тег можно как вручную, так и с помощью SEO плагинов, описанных выше.
Если вы хотите запретить индексацию определенных разделов сайта, например, архивов, категорий или тегов, то вы можете использовать файл robots.txt, который находится в корневой папке вашего сайта. В этом файле вы можете прописать различные правила для запрета индексации URL-адресов. Например, если вы хотите запретить индексацию всех архивов по месяцам и годам, то вы можете добавить такой код:
User-agent: *
Disallow: /20*/Таким образом, вы сообщаете поисковикам, что не нужно индексировать все URL-адреса, начинающиеся с /20 (например, /2021/04/).
Следите за структурой и навигацией сайта
Наконец, один из лучших способов предотвратить появление дублей на WordPress — это следить за структурой и навигацией сайта. Старайтесь делать ваш сайт логичным и удобным для пользователей и поисковых роботов. Избегайте излишней вложенности и дублирования разделов. Используйте хлебные крошки для обозначения положения страницы на сайте. Удаляйте или объединяйте старые или неактуальные страницы. Ссылайтесь на свои страницы с правильными URL-адресами и анкорами. Используйте карту сайта для облегчения индексации и ориентации на сайте.
На чтение 2 мин Опубликовано 11.03.2016
Привет! С помощью плагина — Trash Duplicate and 301 Redirect вы сможете найти и удалить дубли записей и страниц сайта wordpress. Данный плагин довольно простой он ищет и показывает дубли на вашем сайте, если они есть. Если дубли есть, то вы сможете очень просто удалить их, нажав на кнопку. Всё очень просто и быстро! Смотрите далее!
Как убрать дубли страниц WordPress
Установить данный плагин вы сможете прямо из админ-панели wordpress. Перейдите на страницу: Плагины — Добавить новый, введите название плагина в форму поиска, нажмите Enter, установите и активируйте плагин.

После установки и активации плагина, перейдите на страницу: Trash Duplicates. Если на вашем сайте есть дубли, то они сразу же отобразятся на данной странице. Вверху страницы будет показано количество дублей и общее количество записей.

Чтобы удалить дубль записи, нажмите рядом с названием записи на кнопку — Apply. Если вы хотите удалить одновременно несколько записей, то поставьте слева вверху галочку возле значения All и нажмите рядом на кнопку Apply. Удалённые дубли переместятся в корзину, не забудьте потом очистить корзину на странице всех записей.
![]() Внимание! Перед тем как удалять дубли, сделайте резервную копию своего сайта! Обязательно!!!
Внимание! Перед тем как удалять дубли, сделайте резервную копию своего сайта! Обязательно!!!

У плагина есть функция редиректа, то есть, на все имеющиеся у вас на сайте дубли будет создан автоматический 301 редирект. После удаления дублей редирект останется, вы можете оставить его на некоторое время, 1-2 месяца. На сайте у вас больше не будет дублей, но в поисковой системе останутся URL адреса дублей, для этого и нужен редирект, хотя и не обязательно. Чтобы удалить редирект для дубля, нажмите рядом с ссылкой на вкладку — Delete.

Если на вашем сайте нет дублей, но вы заметили, что дубли есть в поисковой системе, то есть в поиске, то возможно вы стали жертвой вируса replytocom.
Остались вопросы? Напиши комментарий! Удачи!

От автора: дубли страниц – одна из самых распространенных технических проблем, которая может ухудшить позиции сайта в поиске. Как с ней разобраться? Невозможно в одной статье рассказать о всех видах дублей на всех движках, давайте сосредоточимся на чем-то одном. Например, на cms WordPress, так как это самый популярный движок. Как убрать дубли страниц в wordpress? Давайте рассмотрим самые основные.

Самое большое зло WordPress
В этом движке есть один вид дублей, который особенно опасен и от него в свое время страдали очень многие сайты. Это так называемый replytocom. Появится он только в том случае, если включить в настройках обсуждения древовидные комментарии. Таким образом, появится возможность ответить на комментарий какого-то человека. Это очень удобно, если только не одно но.
Если присмотреться к url-адресу на кнопке “Ответить”, то можно найти там тот самый злосчастный отросток – replytocom. Ну и что? А то, что чем больше комментариев теперь у вас будет на странице, тем больше дублей. Причем 1 новый комментарий породит не 1 дубль, а много.
Все это происходит потому, что к странице теперь можно будет обратиться не только так: //site.ru/название-записи

Профессия Frontend-разработчик PRO
Готовим Frontend-разработчиков с нуля
На курсе вы научитесь создавать интерфейсы веб-сервисов с помощью языков программирования и
дополнительных технологий. Сможете разрабатывать планировщики задач, мессенджеры, интернет-магазины…
Узнать подробнее
До 10 проектов в портфолио для старта карьеры
Подходит для новичков без опыта в программировании
Практика на вебинарах с разработчиками из крупных компаний
Профессия Frontend-разработчик PRO
Готовим Frontend-разработчиков с нуля
На курсе вы научитесь создавать интерфейсы веб-сервисов с помощью языков программирования и
дополнительных технологий. Сможете разрабатывать планировщики задач, мессенджеры, интернет-магазины…
Узнать подробнее
До 10 проектов в портфолио для старта карьеры
Подходит для новичков без опыта в программировании
Практика на вебинарах с разработчиками из крупных компаний
Но и так: //site.ru/название-записи?replytocom=…
Таким образом, если к статье оставили 100 комментариев, то появится как минимум 100 дублей, но на самом деле гораздо больше. Я часто анализирую различные сайты с помощью специальных сервисов вроде pr-cy. Так вот, там можно наблюдать историю количества проиндексированных страниц.
Так вот, в 2012-13 годах, когда решение проблемы знали немногие, у многих сайтов было 100 тысяч – 10 миллионов страниц в индексе! Сейчас их в тысячи раз меньше, хотя с тех пор на сайтах появилось намного больше контента.
Как раз все эти тысячи и даже миллионы дублей в основном были из-за дублей replytocom. Когда же владельцы сайтов узнали о проблеме и о ее решении, они избавились от дублей и со временем из поисковой выдаче исчезли сотни миллионов мусорных страниц!
Лечение или как избавиться от replytocom
Вариантов тут есть несколько. Во-первых, можно установить плагин Yoast SEO, который используют тысячи веб-мастеров для поисковой оптммизации своих записей. Если хорошенько покопаться в его настройках, то можно найти там пункт “Убрать replytocom”. Ставим галочку и спим спокойно.
Во-вторых, можно просто не включать древовидные комментарии, если вы в них не нуждаетесь. Конечно, будет не так удобно, но это самый простой способ никогда не сталкиваться с этими дублями.
В-третьих, поставить какой-то другой плагин. В частности, не так давно нашел плагин Ark hidecommentslinks, который делает сразу 2 полезных дела: заменяет ссылки в комментариях на кликабельный текст, а заодно и убирает replytocom. Но плагин приведен только в пример, потому что я уверен, что это не единственное расширение, которое справляется с этой проблемой.
Четвертый способ более сложен – замена кнопки ответить. Эта кнопка должна выводиться не стандартными средствами wordpress, а с помощью скрипта. Обычно эту работу делает программист, либо вы можете найти готовое решение в каком-нибудь шаблоне, где стоит самописная система комментариев.
Думаю, этих способов вам хватит, тут еще нужно сказать о том, что чем раньше вы сделаете что-либо для устранения дублей, тем лучше. Самое главное, чтобы ваши статьи не были доступны по такому адресу: //site.ru/название-записи?replytocom=какое-то число
Потому что если они недоступны (вылазит 404 ошибка) то со временем все дубли, если они уже попали в выдачу, пропадут. Если они еще не успели попасть в выдачу, то еще лучше.
Простой способ проверить дубли
Самый простой способ – воспользоваться сервисом, который покажет вам, сколько страниц вашего сайта проиндексировано поисковиком. Для этой цели я использую pr-cy.ru/analysis, так как уже очень привык к нему.
В WordPress на главной странице вы можете видеть, сколько на вашем блоге на данный момент записей, а также сколько страниц. Вот вы и можете примерно прикинуть, сколько страниц должно быть в индексе. Вводим адрес своего сайта в сервис для проверки этих показателей.
Там вы увидите данные для Яндекса и Гугла. Если они примерно отвечают вашим подсчетам и отличаются незначительно, значит, на данный момент все в порядке. Если же вы видите существенную разницу между количеством страниц в Индексе поисковиков, либо в обоих поисковиках это количество сильно превышает кол-во реальных записей, нужно начинать бить тревогу и принимать меры по борьбе с дублями.

Дубли на страницах рубрик
На странице рубрики обычно содержится анонс статьи и кнопка на нее полное прочтения. Так вот, хотя это и не полный дубль, но все же какая-то часть текста может совпадать на обеих страницах (300-600 символов). Таким образом, вы сами у себя понижаете уникальность. Чтобы этого не допустить, желательно закрывать текст в анонсах в теги noindex.
Хорошо, но из-за этого страницы рубрик вообще могут не проиндексироваться? Если вы хотите все-таки их индексировать, рекомендую добавить для каждой рубрики ее уникальное описание в 150-250 символов и выводить его в шаблоне рубрик – category.php.
Дубли в архивах
По умолчанию в wordpress есть архивы по дате и архивы по автору. На этих страницах также выводится описание статей, а еще одинаковые title. Если вы в них не нуждаетесь, можно просто отключить. Это можно сделать с помощью seo-плагина. Например, Yoast SEO.
Дубль на уровне домена
По умолчанию при создании сайта он доступен по двум адресам: site.ru и www.site.ru. По сути, для поисковой системе это 2 разных сайта. Чтобы контент не дублировался, нужно явно указать главное зеркало. Это можно сделать с помощью файла robots.txt, прописав в нем следующее:
|
User—Agent: * Host: site.ru |
Со временем поисиковые роботы поймут, что вариант без www является основным зеркалом. Теперь, если кто-то наберет www.site.ru, его будет редиректить на вариант без www. Также настроить главное зеркало можно в новом Бета-вебмастере Яндекса.

Профессия Frontend-разработчик PRO
Готовим Frontend-разработчиков с нуля
На курсе вы научитесь создавать интерфейсы веб-сервисов с помощью языков программирования и
дополнительных технологий. Сможете разрабатывать планировщики задач, мессенджеры, интернет-магазины…
Узнать подробнее
До 10 проектов в портфолио для старта карьеры
Подходит для новичков без опыта в программировании
Практика на вебинарах с разработчиками из крупных компаний
Профессия Frontend-разработчик PRO
Готовим Frontend-разработчиков с нуля
На курсе вы научитесь создавать интерфейсы веб-сервисов с помощью языков программирования и
дополнительных технологий. Сможете разрабатывать планировщики задач, мессенджеры, интернет-магазины…
Узнать подробнее
До 10 проектов в портфолио для старта карьеры
Подходит для новичков без опыта в программировании
Практика на вебинарах с разработчиками из крупных компаний
Итак, мы с вами рассмотрели самые основные дубли в wordpress, а также как от них можно избавиться. Но это далеко не все дубли. Вообще, если вы хотите провести тотальную зачистку блога на wordpress и избавиться абсолютно от всех видов дублей, я рекомендую к просмотру наш курс о продвижении и монетизации блогов. Вы получите такие знания, которые пригодятся вам, когда вы решите зарабатывать серьезные деньги на сайтах.