Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
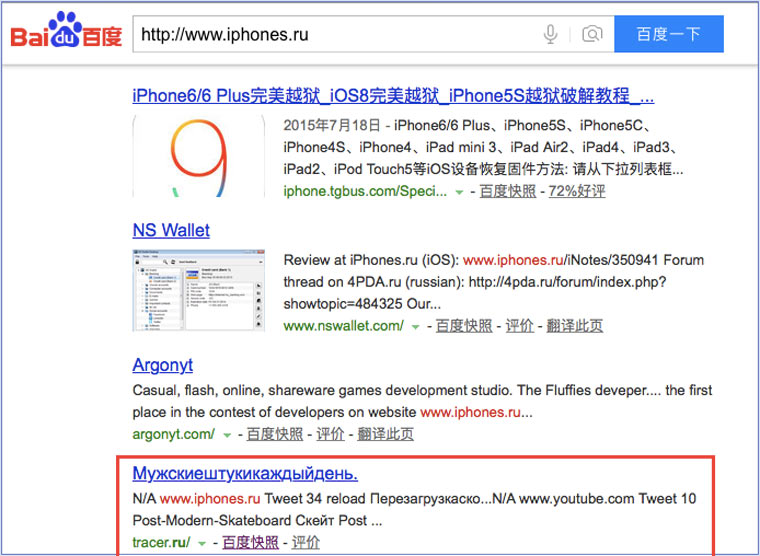
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
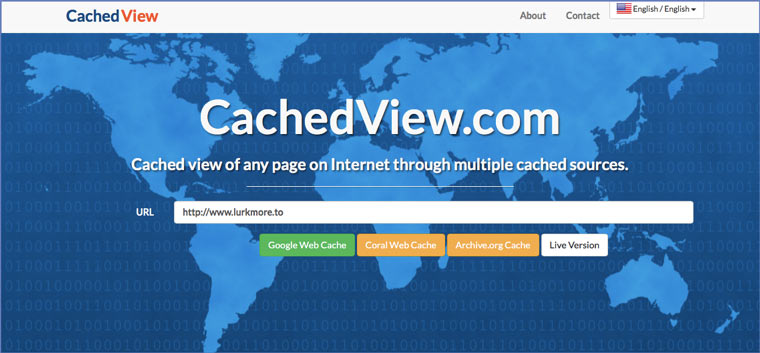
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
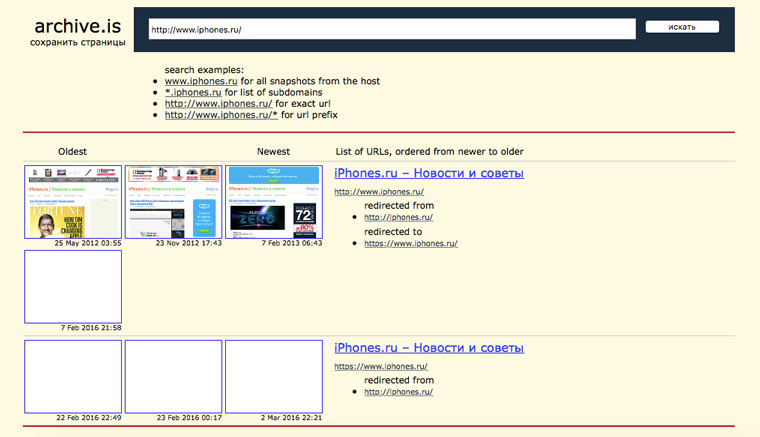
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
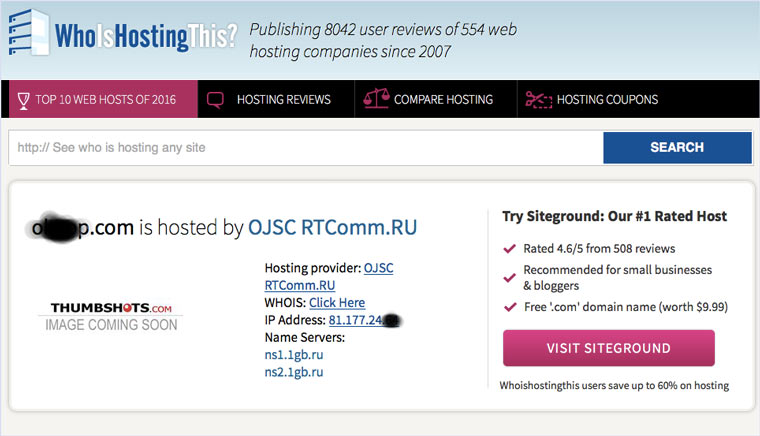
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
навигация по статье
- Что такое веб-архив
- Зачем нужен web archive и как его можно использовать
- Как просмотреть старые версии сайтов на Wayback Machine
- Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
- Уникальный контент из веб-архива
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.



Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.

Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.

Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |

Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:
- Наберите в поисковой строке адрес https://web.archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.

Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.

Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |


Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
![]()
Загрузить PDF
![]()
Загрузить PDF
Вы когда-нибудь задумывались, как некоторый сайт выглядел в прошлом? Хотите посмотреть сайт Microsoft на момент выпуска Windows XP? Тогда вперед! Wayback Machine — это архив старых версий сайтов. В этой статье мы расскажем вам, как на Wayback Machine найти заархивированную версию сайта, а также как добавить сайты в этот архив.
-

1
Перейдите на страницу https://web.archive.org в веб-браузере. Это можно сделать на компьютере или мобильном устройстве. Заархивируйте текущую версию сайта, чтобы ссылаться на него в будущем.[1]
-
2
Введите URL-адрес сайта, который хотите добавить в архив. Сделайте это в поле «Save Page Now» (Сохранить страницу сейчас). Оно находится в правой нижней части страницы.
- Чтобы скопировать полный URL-адрес сайта, который будет заархивирован, откройте этот сайт в веб-браузере, а затем скопируйте адрес из адресной строки в верхней части экрана.
- На компьютере выделите URL-адрес и нажмите ⌘ Cmd+C (Mac) или Ctrl+C (PC), чтобы скопировать его. Теперь щелкните правой кнопкой мыши по полю «Save Page Now» и в меню выберите «Вставить», чтобы вставить скопированный URL-адрес.
- На мобильном устройстве выделите URL-адрес, нажмите и удерживайте его, а затем в меню выберите «Копировать». Чтобы вставить скопированный URL-адрес в поле «Save Page Now», нажмите и удерживайте его, а затем в меню нажмите «Вставить».
Совет: будьте внимательны при вводе адреса. Wayback Machine заархивирует контент только на одной странице, а не на других связанных страницах. Например, чтобы заархивировать страницу с данной статьей, введите https://www.wikihow.com/Use-the-Internet-Archive%27s-Wayback-Machine. Если же ввести адрес https://www.wikihow.com, будет заархивирована только главная страница wikiHow.
- Чтобы скопировать полный URL-адрес сайта, который будет заархивирован, откройте этот сайт в веб-браузере, а затем скопируйте адрес из адресной строки в верхней части экрана.
-
3
Нажмите SAVE PAGE (Сохранить страницу). Эта кнопка находится справа от текстового поля с адресом. В верхнем левом углу появится миниатюра веб-сайта и текст «Saving page now» (Сохранение страницы). Текст исчезнет, когда страница будет добавлена в архив.
- Некоторые веб-сайты нельзя заархивировать на Wayback Machine из-за их конфигурации. Если появилась ошибка, владелец сайта запретил Wayback Machine работать с сайтом.
Реклама



-
1
Перейдите по адресу https://web.archive.org в веб-браузере. С помощью Wayback Machine старые версии веб-сайтов можно просматривать на любом компьютере и мобильном устройстве.
-
2
-
3
Нажмите ↵ Enter или ⏎ Return. Отобразятся результаты поиска в виде гистограммы и календаря.
- Если вы искали сайт по его имени или ключевому слову, появится список сайтов. Нажмите на URL-адрес сайта, а затем перейдите к следующему шагу.
-
4
Выберите год на гистограмме. По умолчанию на гистограмме, которая расположена в верхней части страницы, будет выбран текущий год. Черные полосы указывают, сколько раз страница была заархивирована Wayback Machine за этот год. Щелкните по области над годом, чтобы открыть 12-месячный календарь.
Примечание: если в нужном вам году черных полос нет, в этом году страница ни разу не сохранялась.
-
5
Нажмите на число (дату) в календаре. В зависимости от сайта вокруг некоторых чисел в календаре отобразятся зеленые и/или синие кружки. Если число обведено, в этот день сайт был заархивирован. Щелкните по числу, чтобы открыть заархивированную версию веб-сайта.
- Если в какой-то день сайт был заархивирован несколько раз, диаметр кружка будет больше. Наведите курсор мыши на число, чтобы просмотреть список заархивированных версий, а затем нажмите на время архивирования, чтобы открыть нужную версию сайта.
- Если появилась ошибка, сайту запрещено работать с Wayback Machine. Также ошибка может означать, что сайт был недоступен во время архивирования.
- В зависимости от метода архивирования сайта можно щелкнуть по ссылке на странице, чтобы просмотреть другой заархивированный контент. Но, как правило, переход по ссылке на заархивированном сайте приводит к ошибке.
-
6
Просмотрите другие заархивированные версии сайта. Вверху заархивированного сайта отображается гистограмма — используйте ее, чтобы просматривать версии сайта, заархивированные в других числах. С помощью значков в виде синих стрелок перейдите к предыдущей или следующей заархивированной версии сайта, или щелкните по другой дате.
Реклама






Советы
- В некоторых старых архивах контента нет. В этом случае выберите другое число и посмотрите, есть ли на сайте контент.
- Авторизоваться на заархивированном сайте не получится. Это сделано для того, чтобы предотвратить комментирование старых версий сайтов и чтобы защитить скриншоты, так их редактирование сродни внесению изменений в историю.
Реклама
Об этой статье
Эту страницу просматривали 26 549 раз.