Большинство ошибок, возникающих при валидации кода можно свести к набору типовых вариантов, зная которые легко понять, на что «намекает» валидатор. В качестве образца возьмем расширение HTML Validator для браузера Firefox, предназначенное для проверки кода и рассмотрим список ошибок и замечаний по коду.
Посмотреть все возможные сообщения валидатора можно по адресу http://www.htmlpedia.org/wiki/HTML_Tidy, далее приведены основные ошибки с их описанием и решением. Зеленым цветом выделен корректный вариант, другой цвет используется для обозначения ошибки.
Notice: entity «…» doesn’t end in «;»
Это замечание возникает при использовании спецсимволов вроде < при отсутствии на конце точки с запятой.
 
Решение
Добавьте в конце спецсимвола точку с запятой.
Notice: numeric character reference «…» doesn’t end in ‘;’
Возникает при использовании числовых спецсимволов вроде — когда в конце забыли добавить точку с запятой.
™
™
Решение
Добавьте в конце спецсимвола точку с запятой.
unescaped & or unknown entity «&…»
Символ амперсанда (&) часто применяется в адресах ссылок (атрибут href тега <a>), поскольку он разделяет несколько параметров. Однако амперсанд зарезервирован для спецсимволов вроде поэтому в ссылках необходимо указывать & вместо &.
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
Решение
Замените & на &.
missing </…>
Отсутствует обязательный закрывающий тег.
<head><title>Заголовок</title></head>
<head><title>Заголовок</head>
Решение
Добавьте закрывающий тег.
missing </aaa> before <bbb>
Ошибка возникает при нарушении порядка тегов, когда блочный тег располагается внутри встроенного. В данном случае блочный тег <bbb> находится внутри встроенного тега <aaa>.
<p><span>Текст</span></p>
<span><p>Текст</p></span>
Решение
Поменяйте расположение тегов — перенесите встроенный тег внутрь блочного.
discarding unexpected <…>
Обнаружен открывающий или закрывающий тег, у которого нет пары. Подобная ошибка возникает в двух случаях: есть открывающий тег, но нет закрывающего; имеется закрывающий тег, которому не соответствует открывающий.
<div><div>Текст</div></div>
<div>Текст</div></div>
<div><div>Текст</div>
Решение
В зависимости от ситуации добавьте или удалите открывающий или закрывающий тег.
Notice: nested emphasis …
Контейнер содержит аналогичный тег физического форматирования, который не должен повторяться.
<p><b>Текст</b></p>
<p><b><b>Текст</b></b></p>
Решение
Удалите один из тегов.
replacing unexpected … by </…>
Закрывающий тег не соответствует открывающему тегу.
<p><b>Текст</b></p>
<p><b>Текст</span></p>
Решение
Замените открывающий или закрывающий тег на парный.
… isn’t allowed in <…> elements
Обнаружены теги, которые запрещено размещать внутри указанных элементов.
<head><title>Заголовок</title></head>
<head><body>Текст</body></head>
Решение
Переместите HTML-элемент в правильный раздел.
missing <…>
Нет обязательного тега в структуре элементов. Ошибка, к примеру, может возникнуть при формировании таблицы, когда пропущен тег <tr> и сразу же после <table> следует <td>.
<ol><li>Список</li></ol>
<ol>Список</ol>
Решение
Проверить правильность вложения тегов в текущем элементе и наличие обязательных элементов.
Notice: inserting implicit <…>
Сообщение возникает из-за предыдущей ошибки на странице.
Решение
Исправьте предыдущие ошибки.
Insert missing <title> element
В коде не вставлен тег <title>.
<head><title>Заголовок</title></head>
<head></head>
Решение
Добавьте контейнер <title>.
Multiple <frameset> elements
Тег <frameset> используется в документе более одного раза без вложения. Допускается вставлять несколько элементов <frameset>, но вложенных один в другой.
<frameset …><frame …>
<frameset …><frame …></frameset>
</frameset>
<frameset …><frame …></frameset>
<frameset …><frame …></frameset>
Решение
Используйте вложенные теги <frameset>.
<…> is not approved by W3C
Указанный тег не входит в спецификацию HTML.
<span style=»white-space: nowrap;»>текст без переносов</span>
<nobr>текст без переносов</nobr>
Решение
Удалите тег или замените его подходящим эквивалентом.
Error: <…> is not recognized!
Тег не распознан и не входит в спецификацию HTML.
Правильно: <p>Текст</p>
Неверно: <p><adres>Текст</adres></p>
Решение
Удалите неизвестный тег.
Trimming Empty Tag
Контейнер пустой или содержит только пробел.
<p>Текст</p>
<p> </p>
<p></p>
Решение
Удалите тег или добавьте внутрь контейнера текст.
<a> is probably intended as </a>
В закрывающем теге <a> отсутствует слэш.
<a href=»http://htmlbook.ru»>Ссылка на сайт</a>
<a href=»http://htmlbook.ru»>Ссылка на сайт<a>
Решение
Добавьте слэш к закрывающему тегу.
… shouldn’t be nested
Некоторые теги вроде <form> не могут содержать сами себя. Это сообщение также возникает из-за предыдущей ошибки.
<form action=»gb.php» name=»guestbook»></form>
<form action=»gb2.php» name=»guestbook2″></form>
<form action=»gb.php» name=»guestbook»>
<form action=»gb2.php» name=»guestbook2″></form>
</form>
Решение
Удалите вложенные теги или исправьте предыдущую ошибку.
Text found after closing </body>-tag
Теги или текст добавляется после закрывающего тега </body>.
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
</html>
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
<b>Привет!</b>
</html>
Решение
Удалите текст после тега </body> или перенесите этот тег в конец текста.
Adjacent hyphens within comment
Комментарии в коде HTML определяются конструкцией вида <!— комментарий —>. Если в тексте комментария подряд идет два и более дефиса, возникает ошибка.
<!— Комментарий — заголовок —>
<!— комментарий —>
<!— Комментарий — тело документа —>
Решение
Удалите лишние дефисы.
SYSTEM, PUBLIC, W3C, DTD, EN must be upper case
Элемент <!DOCTYPE> указан неверно, в частности следующие атрибуты необходимо писать в верхнем регистре: SYSTEM, PUBLIC, W3C, DTD, EN.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01 Transitional//EN» «http://www.w3.org/TR/html4/loose.dtd»>
<!doctype html public «-//w3c//dtd html 4.01 Transitional//en» «http://www.w3.org/TR/html4/loose.dtd»>
Решение
Пишите <!DOCTYPE> корректно.
Warning: missing <!DOCTYPE> declaration
Не указан элемент <!DOCTYPE>.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
<html>
<head>
<title>Заголовок</title>
</head>
<body>
<p>Основной текст</p>
</body>
</html>
<html>
<head>
<title>Untitled Document</title>
</head>
<body>
</body>
</html>
Решение
Поместите элемент <!DOCTYPE> в самую первую строку кода документа.
Too much <…>-elements
Повторяется тег, который в коде должен быть только один. К таким тегам относится <html>, <head>, <title> и <body>.
<head>
<title>Заголовок</title>
</head>
<head>
<title>Заголовок</title>
<title>Название статьи</title>
</head>
Решение
Удалите повторяющийся тег.
<…> inserting «…» attribute
Не указан обязательный атрибут для данного тега.
<style type=»text/css»>
<style>
Решение
Проверьте тег и добавьте недостающие атрибуты.
… attribute … lacks value
Атрибут тега не содержит обязательное значение или оно написано с синтаксической ошибкой.
<a href=»link.html»>Ссылка</a>
<a href>Ссылка</a>
Решение
Проверьте атрибуты тега и добавьте недостающие значения.
… attribute «…» has invalid value «…»
Атрибут содержит некорректное значение. Ошибка проявляется в тех случаях, когда в значении вместо текста пишется число и наоборот. Так, атрибуты id и name должны начинаться с символа ([A-Za-z]) и могут содержать цифры ([0-9]), дефис (-), подчеркивание (_), двоеточие (:) и точку (.). Значение ширины и высоты в атрибутах тегов не должно содержать ничего, кроме цифр ([0-9]) и процентов (%).
<div id=»layer1″>Слой 1</div>
<img src=»images/pic.gif» width=»200″ height=»120″>
<div id=»2layer»>Слой 2</div>
<img src=»images/pic.gif» width=»200px» height=»120px»>
Решение
Проверьте атрибут тега и измените его значение.
<…> missing > for end of tag
Ошибка может возникать в двух случаях: некорректно написан тег, что происходит, когда забыли добавить закрывающую скобку и применение > вместо использования спецсимвола.
<p>Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
<p Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
Решение
Вставьте отсутствующую закрывающую скобку.
Замените < на <.
<…> proprietary attribute «…»
Тег содержит атрибут, специфичный только для браузера Internet Explorer или другого и не входящий в спецификацию. Примером является атрибут height тега <table>.
Список всех атрибутов, входящих в спецификацию HTML приведен по адресу http://www.w3.org/TR/html4/index/attributes.html
<table style=»height: 100%»>
<table height=»100%»>
Решение
Список наиболее характерных атрибутов тегов приведен в табл. 14.1.
| Тег | Устаревший атрибут | Стандартный атрибут |
|---|---|---|
| <body> | marginwidth=0, marginheight=0, leftmargin=0, topmargin=0 | style=»margin: 0″ |
| <table> | height=100% | style=»height: 100%» |
| <table> | nowrap | style=»white-space: nowrap» или <td nowrap> |
| <td> | background=»abc.gif» | style=»background-image:url(abc.gif)» |
… proprietary attribute value «…»
Значение атрибута не входит в спецификацию HTML и является специфичным для браузера Internet Explorer или другого. Например, значение align=»absmiddle» тега <img> недопустимо.
<p><img src=»hello.gif» alt=»Привет» align=»middle»></p>
<p><img src=»hello.gif» alt=»Привет» style=»vertical-align: middle»></p>
<p><img src=»hello.gif» alt=»Привет» align=»absmiddle»></p>
Решение
Используйте стандартные значения атрибутов тегов или используйте стилевой эквивалент.
… dropping value «…» for repeated attribute «…»
Атрибут применяется в теге больше одного раза.
<img src=»image.jpg»>
<img src=»image.jpg» src=»image.jpg»>
Решение
Удалите повторяющийся атрибут.
… unexpected or duplicate quote mark
Отсутствует открывающая или закрывающая кавычка в атрибуте тега.
<img src=»image.jpg»>
<img src=image.jpg»>
Решение
Добавьте парную кавычку к значению атрибута.
… attribute with missing trailing quote mark
Тег содержит атрибут, в котором задано неверное количество кавычек.
<p id=»my_id»>
<p id=»my_id»»>
Решение
Добавьте или удалите одну из кавычек.
… id and name attribute value mismatch
Ошибка возникает, когда значения атрибутов id и name не совпадают между собой, что приводит к конфликту при обращении к свойствам элемента через скрипты.
<a name=»elm» id=»elm»>
<a id=»elm»>
<a name=»abcdef» id=»db1″>
Решение
Удалите один из атрибутов или сделайте значения атрибутов name и id одинаковыми.
Notice: replacing <…> by <…>
Ошибка возникает в следующих случаях:
- неверный порядок тегов;
- добавлен лишний закрывающий тег;
- имеется открывающий тег без наличия обязательного закрывающего.
<p>Текст</p><br>
<p>Текст</p></p>
<p>abc<br><table>…</table></p>
Решение
Измените порядок тегов или удалите один из открывающих или закрывающих тегов.
… anchor «…» already defined
Значения атрибута name у различных тегов совпадает между собой. Значение name должно быть уникальным.
<form name=»my_form1″ action=»test1.php»></form>
<form name=»my_form2″ action=»test2.php»></form>
<form name=»my_form» action=»test1.php»></form>
<form name=»my_form» action=»test2.php»></form>
Решение
Выберите другое имя или измените предыдущие имена таким образом, чтобы они не совпадали.
<…> is probably intended as </…>
Тег повторяется дважды в коде HTML, тогда как подобный тег не должен содержать сам себя.
<em>Привет, мир!</em>
<em>Привет<em>, мир!</em></em>
Решение
Удалите один из тегов.
<…> lacks «…» attribute
Требуется обязательный атрибут тега, который, тем не менее, отсутствует.
<form action=»my_action.php»>
<form>
Решение
Добавьте недостающий атрибут к тегу.
В этой статье мы рассмотрим, как с помощью сервиса Labrika обнаружить и исправить на сайте HTML-ошибки. Информация о таких ошибках будет полезна как для владельца веб-ресурса, который контролирует работу своего SEO-специалиста и хочет знать, какие нерешенные проблемы есть на сайте, так и для оптимизаторов, поскольку им нужно оперативно обнаружить и исправить все изъяны, мешающие продвижению ресурса.
HTML (от англ. HyperText Markup Language) — это язык гипертекстовой разметки, который применяется на каждой веб-странице в интернете и состоит из множества элементов (тегов). Как правило, ошибками в коде HTML являются незакрытые или дублированные элементы, неправильный порядок их расположения, неверные атрибуты или их отсутствие.
На примере ниже в коде страницы присутствует закрывающий тег ссылки </a> без открывающего тега <a>:

Для проверки валидности кода (то есть соответствия стандартам HTML) используются специальные инструменты. Они проверяют:
- Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
- Нарушения вложенности тэгов: незакрытые и неправильно закрытые теги. По правилам теги закрываются так же, как их открыли, только в обратном порядке.
- Соответствие кода указанному DTD (Document Type Definition): правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов.
Как HTML-ошибки влияют на продвижение сайта?
Как отмечал представитель Google Джон Мюллер, валидность кода HTML не является прямым фактором ранжирования, однако критические ошибки в HTML мешают:
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- отображению на мобильных устройствах и кроссбраузерности.
В первую очередь наличие ошибок в коде HTML может привести к тому, что часть контента страницы не будет проиндексирована.
О том, что следует использовать действительный HTML, сказано в Рекомендациях Google для веб-мастеров. Среди авторитетных SEO-источников бытует мнение, что фильтр Google Panda может быть наложен на сайт за большое количество таких ошибок (отдельную статью об алгоритме Google Panda вы можете прочитать на нашем сайте).
Официальные источники Яндекса также сообщают, что подобного рода ошибки на сайте нежелательны, а верстка страниц должна соответствовать принятым стандартам.
Почему важно проверять наличие HTML-ошибок?
Ошибки в коде HTML могут быть критическими и несущественными, которые не ведут к серьезным потерям. Что касается критических, то одни из них отрицательно сказываются на функционировании сайта, а другие — на работе поисковых систем.
Современные браузеры автоматически исправляют 99% критических ошибок при загрузке сайта. Однако некоторые из них браузер исправить не может. Например, если тег <а> для создания ссылки не содержит адреса, то браузер не сможет определить, куда её направить. Или в теге <img> для размещения картинки не указан путь к ней, тогда браузер не сможет её подгрузить. Наличие таких ошибок в коде может привести к серьезным последствиям — например, не загрузятся фото товара или не будет работать корзина.
Поисковые системы также автоматически исправляют часть HTML-ошибок, но у них возникает следующая проблема: если браузеры в состоянии потратить несколько секунд на исправление ошибок, то у поисковых роботов нет такой возможности. Им приходится сканировать сотни миллиардов страниц ежемесячно, поэтому боты не могут тратить время на устранение всех ошибок. Некоторые из них поисковые системы игнорируют, а также могут не включать в индекс содержащие их страницы или проиндексировать только часть контента таких страниц.
Веб-мастера и пользователи просматривают сайты в браузере, где большая часть HTML-ошибок исправляется автоматически, и поэтому не придают им большого значения. Зачастую даже разработчики не исправляют элементарных грубых ошибок в разметке. Это приводит к тому, что критические для поисковых систем ошибки остаются на сайтах и могут стать причиной неправильной индексации страниц. В результате бюджеты на продвижение будут потрачены неэффективно, а источник проблемы так и остается неустановленным.
Как обнаружить HTML-ошибки с помощью сервиса Labrika
Labrika проверяет данные ошибки двумя способами:
- С помощью валидатора W3C, который проверяет наличие всех HTML-ошибок.
- С использованием валидатора Labrika «Критические ошибки HTML». Он устанавливает только те ошибки, которые могут повлиять на сбор данных поисковыми системами или привести к некорректному отображению сайта и нарушениям в его работе. определяет порядка 15 видов таких ошибок.
Отчет » Критические ошибки HTML» вы сможете найти в левом боковом меню в разделе «Технический аудит».
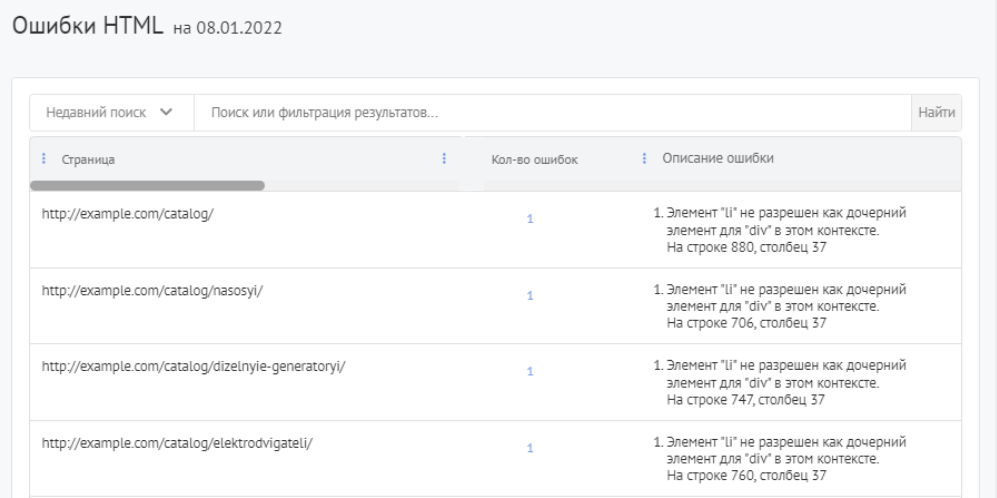
Актуальные данные в отчете вы сможете увидеть после запуска проверки сайта.
Отчет показывает:
- Страницы, которые содержат критические ошибки HTML.
- Количество и описание критических HTML-ошибок на данной странице.
При клике по их числу осуществляется переадресация на валидатор W3C, в котором вы сможете найти подробную информацию обо всех имеющихся в коде страницы ошибках.
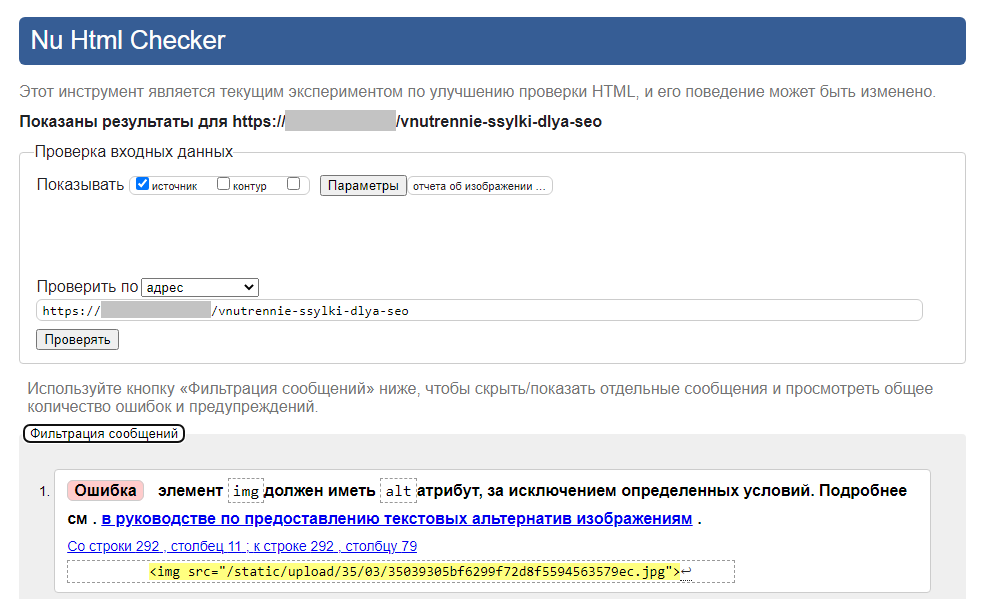
Как исправлять HTML-ошибки?
Критические HTML-ошибки необходимо исправлять в первую очередь, так как поисковые системы могут отреагировать на них отрицательно. Влияние прочих ошибок на продвижение в поиске не доказано.
Если для исправления ошибок требуется передать их список специалисту по верстке, с помощью кнопок в правой части страницы отчета вы можете скачать его данные в формате таблицы Excel или поделиться ссылкой на отчет по HTML-ошибкам с другими пользователями.

После нажатия на значок ссылки появится следующее всплывающее окно:
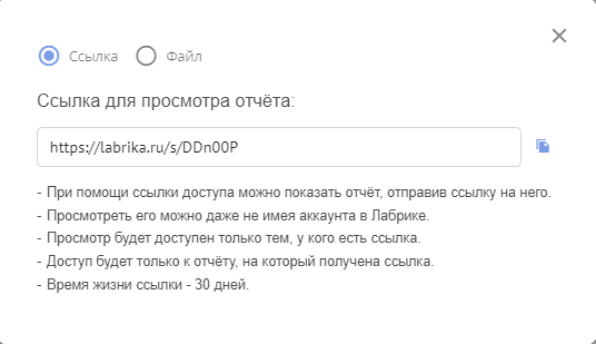
Кнопка, которая расположена справа от ссылки, позволяет скопировать её в буфер обмена. Отчет по ссылке будет доступен даже тем, кто не имеет аккаунта в Labrika.
Для ускорения работы по исправлению HTML-ошибок можно воспользоваться редакторами, которые автоматически создают закрывающие теги для документов HTML (например, Bluefish, Notepad++).
2018/06/10
Марат
2
0
html |
Иногда, бывает такое, что достаточно нехватки закрывающего тега либо наоборот лишний тег просочился, то ваша страница превращается в что-то непонятное и кривое!
Об оишибке синтаксиса в html
- Что такое Ошибка синтаксиса html
- Исключение ошибок синтаксиса на вашем сайте
- Как найти синтаксическую ошибку в коде html
- Бесплатный совет -> о синтаксических ошибках
Что такое Ошибка синтаксиса html
Предполагается, что синтаксис в html — это строгий синтаксис! Вообще, по идее браузер сам должен достроить дерево html(Честно признаюсь, что никогда не задумывался над всеми этими механизмами!), если не хватает какого-то из тегов! Но… кривизна все равно вылазит… знаю по собственному сайту! Как только вот прямо здесь я вставлю открывающийся тег -> div весь правый сайд бар улетит в футер… 
смайлы
Единственное и главное правило не создавать ошибки синтаксиса в html — писать правильный код!
Так…
Что же такое Ошибка синтаксиса html
Ошибка синтаксиса html — это нарушение правильной структуры каркаса html дерева, от которой визуальное представление сайта на мониторе выглядит не так, как оно задумывалось!
Исключение ошибок синтаксиса на вашем сайте
Для того, чтобы исключить появление ошибок синтаксиса на вашем сайте вам потребуется всего-то правильно сделать html + каркас сайта — да это звучит банально ничего умнее я не придумал, потому, что это азы! И без этого вы просто обречены каждый раз мучаться с ошибками синтаксиса в html!
Да я буду много сейчас говорить банальностей и эти банальности нужно делать, как ходить на работу, любить своих родителей и своих детей и т.д. можно продолжать до бесконечности!
Создавайте структуру сайта именно деревом, когда вложенный тег отодвигается на шаг вправо.
<div class=»div1″>
<div class=»div2″>
<div class=»div3″>
<div class=»div4″>
данные
</div>
</div>
</div>
</div>
Старайтесь делать код html простым(краткость сестра таланта), чтобы его можно было понять! Избегайте применять по поводу и без повода лишние теги!
Делайте ваш код html блоками, например блок menu -> блок futer
Добавляете описание в началу блока и и к концу блока:
<!— menu —>
здесь menu
<!— /menu —>
<!— futer —>
здесь futer
<!— /futer —>
Как найти синтаксическую ошибку в коде html
К сожалению, в html в отличии к примеру от php не указывается на какой строке ошибка! Но нам все равно от этого не легче и нам нужно
найти синтаксическую ошибку в коде html — как это сделать!?
Как я уже говорил, у вас должен быть html каркас создан по неким правилам, которые я немного озвучил выше!
Как раньше я искал синтаксическую ошибку в коде html!? Брал файл, в котором, есть основные блоки… удаляем блок меню… загружаем на сервер… смотрим пропала ошибка синтаксическая или нет… если пропала, то ошибка в блоке меню. Если нет, то меню возвращаем на место! Но и не забываем, что может быть сразу несколько ошибок…
Если в меню синтаксическая ошибка. не найдена идем в тело страницы… далее футер…и далее сайд бар… никто, ничего умнее еще не придумал…
Нашлась ошибка в блоке? … разбираем блок построчно! До тех пор, пока не найдем синтаксическую ошибку html!
Есть еще возможность проверять код в программах о которых вы знаете редакторы кода… Sublime + Notepad(не нравятся эти -> открываем поисковик ищем редактор кода…), открываем код html в этой программе и проверяем по тегам… если мы поставим мышку на один из тегов, то второй тег будет подсвечен аналогично, в sublime — это полоса снизу…
Нажмите, чтобы открыть в новом окне.

Бесплатный совет -> о синтаксических ошибках
Как я уже говорил и повторюсь! Делайте html код блоками!
Чем меньше тегов, тем лучше!
Длинный код, вас должен напрягать! Чем длиннее код, тем возможностей появления синтаксических ошибок и не только, возрастает!
Если у вас html и php перемешан и находится в разных файлах, то найти ошибку вообще будет сложно! Выделяйте html код в отдельный файл
Это… какие-то совсем простые советы, но я их говорю не просто так, а потому, что делаю это давно и у меня уже есть какие-то свои наработки и правила, которым я следую!
Выработайте свои правила и придерживайтесь их и у Вас больше никогда не будет синтаксических ошибок в html!
Не благодарите, но ссылкой можете поделиться!
COMMENTS+
BBcode
HTML — это язык гипертекстовой разметки. Благодаря ему мы видим не просто текст, а полноценные страницы с интерактивным контентом. Сегодня он поддерживается организацией W3C — World Wide Web Consortium. Она разрабатывает принципы и стандарты, в соответствии с которыми делаются все современные сайты.
Что такое ошибки HTML? Это несоответствие кода разметки общепринятым стандартам, руководству W3C. А код с ошибками иначе называют невалидным (с английского Invalid code).
Невалидный код работает (да!)
В отличие от языков программирования, где любая пропущенная ошибка останавливает программу, HTML очень даже неплохо работает с невалидным кодом. Его основная цель — отобразить страницу “как есть”. Однако тут и возникает заметная проблема.
Если часть тегов не закрыта, а другие находятся в неправильном месте с неверными атрибутами, компьютер все равно выводит страницу на экран. Но у разных браузеров это получится по-разному, а поисковик может совсем не найти часть вашей статьи. И вы вряд ли узнаете об этом, а SEO продвижение сайта в Google и Яндекс значительно замедлится.

Как проверить ошибки HTML
Какая ошибка выкинет сайт из поисковой выдачи, а на какую не обращать внимания? Ответ на этот вопрос хочет знать каждый. Конечно, основные факторы ранжирования поисковиков известны, но реальные алгоритмы остаются в тайне даже для большинства разработчиков Google и Яндекс. Поэтому самое надежное решение — полностью устранять невалидный код. А проверить ошибки HTML кода на странице удобнее всего на официальном сайте W3C.

Расшифровка ошибок на сайте validator.w3.org

Валидатор не выявил ошибок на странице
Откуда берутся ошибки HTML и невалидный код
В современном мире большинство сайтов создаются на CMS — системах управления контентом. А значит разметку HTML больше не приходится писать вручную. Такой подход сильно ускоряет и упрощает процесс разработки, но не без ложки дегтя.
При верстке страниц вручную любые ошибки легко устраняются, а код остается легко читаемым и полностью валидным. Но CMS, например, самый популярный движок WordPress, генерируют код автоматически. А значит уследить за ним на порядок сложнее, такой HTML трудно поддается корректировке.
И редко какие недостатки можно устранить из меню настроек. Почти всегда за этим надо лезть в библиотеки CMS, либо применять самописные плагины.
Если исправить все ошибки, сайт сразу попадет в ТОП? Никто не может давать гарантий, являлась ли конкретная ошибка причиной плохих позиций сайта или страницы. Поэтому стоит комплексно подходить к поисковому продвижению, исправляя и улучшая множество параметров.
Итоги
Летом 2021 года ведущий аналитик Google Джон Мюллер заявил, что ошибки HTML прямо не влияют на ранжирование. Но они точно играют свою косвенную роль в жизни каждого веб-сайта. В частности, невалидный код HTML может ломать сайт на некоторых устройствах (телефоны, планшеты и т.д.) и блокировать текст для поисковых роботов. А если поисковики не найдут часть контента на странице, о дальнейшем SEO продвижении сайта можно забыть.
Привет. Сразу отвечу на ваш вопрос: стоит ли читать Вам этот урок? Перейдите на весьма полезный и бесплатный сервис validator.w3.org, вбейте туда адрес своего сайта и, если вы видите, что на Вашем сайте есть ошибки, то урок прочитать стоит. Примеры отображения ошибок с помощью данного онлайн валидатора:
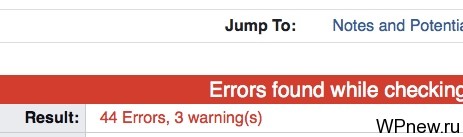
На моем же блоге сейчас нет подобных ошибок, я от них избавился (всего было более 70 ошибок и более 80-ти предупреждений). Чтобы внести ясность, расскажу, что такое валидный код и зачем он нам необходим.
Валидный код — это код, который соответствует стандартам.
На валидность можно проверить HTML, CSS, всяческие микроразметки и другое. Сегодня я расскажу про валидность в HTML.
- Валидный код необязателен, но количество ошибок должно быть минимальным, иначе ваш сайт не будет кроссбраузерным. Валидность кода нужна в прежде всего для того, чтобы ваш сайт отображался правильно во всех браузерах.
- Поисковые роботы «разговаривают» с вашим сайтом на языке HTML, поэтому важно отдавать четко и ясно контент на сайте со всеми «закрытыми тегами» и прочее.
- Валидность HTML влияет на SEO, но довольно незначительно (если, конечно, у вас не сотни, а то и тысячи ошибок). Рекомендую почитать интересные наблюдения Деваки «Влияние качества HTML на их ранжирование».
- Когда я делал на своем сайте код валидным, я нашел и исправил свои глупые ошибки (повторение тегов, пропущенная буква и т.п.).
- Не стоит «рвать себе *опу», если какую-то ошибку сложно исправить, либо ее исправление принесет вред функциональности сайта. Главное, чтобы было удобно пользователю.
Ниже я разберу основные ошибки, на которые указывал валидатор. Если вдруг в списке ниже не окажется вашей ошибки, впишите ее в комментариях, попробуем вместе разобраться и я добавлю решение данной проблемы в данный урок. Кстати, да, ошибки, на которые указывает валидатор w3c смотрим тут:
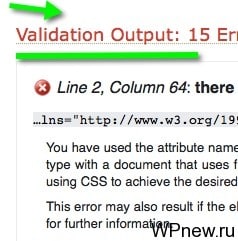
В каждой ошибке есть подсказка — это номер строки в исходном коде странице, а из нее уже можно определить примерно в каком файле темы расположена данная строка. Исходный код страницы смотрим с помощью CTRL+U (в основных браузерах).

Перед тем, как приступить к работе, сделайте резервную копию шаблона вашего сайта.
Также для упрощения нахождения ошибок в исходном коде, можете использовать HTML валидатор для Mozilla Firefox. Установив его, перейдя в исходный код страницы, вы увидите те же самые ошибки, что указывает сервис validator.w3.org. Кликнув по названию ошибки (в левом нижнем углу), вас автоматически перебросит на ту строчку, где находится данный невалидный код.
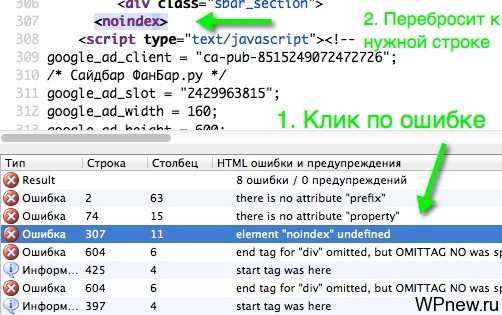
Нахождение ошибок в HTML с помощью валидатора w3c и их исправление
Ищите в списке ниже свою ошибку и кликнуть по ней, вас автоматически «прокрутит» куда надо.
- No space between attributes.
- The width attribute on the td element is obsolete. Use CSS instead.
- An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images.
- Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
- The hgroup element is obsolete. To mark up subheadings, consider either just putting the subheading into a p element after the h1-h6 element containing the main heading, or…
- Element «noindex» undefined.
- End tag for element «div» which is not open
- Document type does not allow element «li» here; missing one of «ul», «ol», «menu», «dir» start-tag.
- End tag for «div» omitted, but OMITTAG NO was specified.
- There is no attribute «border».
- Character «<» is the first character of a delimiter but occurred as data.
- Saw » when expecting an attribute name. Probable cause: = missing immediately before.
- The align attribute on the img element is obsolete. Use CSS instead.
- Bad value Блог Алексея Смирнова for attribute href on element link: Illegal character in path segment: not a URL code point.
1. No space between attributes.
…rel=»shortcut icon» href=»http://arbero.ru/favicon.ico» ; type=»image/x-icon» Просто убираем «точку с запятой».
2. The width attribute on the td element is obsolete. Use CSS instead.
td valign=»center» width=»80″ height=»80″ >
Подобное преобразуем к виду
td style=»align:center; width:80; height: 80;»>
3. An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images.
Одна из самых частых ошибок. Просто не хватает альтернативного текста для картинки. Прописываем тег alt.
4. Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
section id=»comments» >
Внутри блока section должны содержаться что-то из тегов h2-h6, если их нет, просто переименовываем слово section на div
5. The hgroup element is obsolete. To mark up subheadings, consider either just putting the subheading into a p element after the h1-h6 element containing the main heading,
or else putting the subheading directly within the h1-h6 element containing the main heading, but separated from the main heading by punctuation and/or within, for example, a span class=»subheading» element with differentiated styling. To group headings and subheadings, alternative titles, or taglines, consider using the header or div elements.
Аналогично предыдущему пункту. Просто меняем фразу hgroup на div. Вы можете использовать инструмент «Найти/заменить все» в текстовом редакторе, чтобы ускорить подобные процессы.
6. Element «noindex» undefined
Чтобы тег noindex стал валидным, пишем его в виде комментирования, то есть так:
<!--noindex-->Неиндексируем<!--/noindex-->
7. End tag for element «div» which is not open
Закрывающий тег div лишний. Убираем его.
8. Document type does not allow element «li» here; missing one of «ul», «ol», «menu», «dir» start-tag
Неправильное использование тега «li»: отсутствует тег «ul», «ol» и др. Проверьте.
9. End tag for «div» omitted, but OMITTAG NO was specified
Не хватает закрывающего тега div.
10. There is no attribute «border»
alt=»» width=»1″ height=»1″ border=«0″/>
Просто удаляем фразу border=»0″.
11. Character «<» is the first character of a delimiter but occurred as data
Не используйте тег «<» перед обычными словами, используйте лучше разные кавычки.
12. Saw » when expecting an attribute name. Probable cause: = missing immediately before.
Лишняя кавычка, удалите ее.
13. The align attribute on the img element is obsolete. Use CSS instead.
Не используйте значение align внутри тега img. Пропишите ее отдельно, в таком виде:
<div align='center'>тут картинка (img src)</div>
14. Bad value for attribute href on element link: Illegal character in path segment: not a URL code point.
То, что идет в href должно быть ссылкой, начинаться с http, но никак не слово.
Заключение
Если у вас на сайте есть какая-то ошибка, которой нет в этом списке — пишите в комментариях. Разберемся, а я дополню статью. Повторюсь, если какую-то ошибку не получается исправить, не стоит заморачиваться.
У меня на блоге осталась ошибка (хотя еще вчера почему-то код был без ошибок):
The text content of element script was not in the required format: Expected space, tab, newline, or slash but found < instead.
Если в курсе, как исправить ее, буду признателен. Я немножко перфекционист. 🙂
Будете ли вы делать HTML код сайта валидным?
Пожелаю вам получить валидный HTML код на вашем сайте, уведомление которого выглядит так:
 P.s. Вы часто перегружаете свой организм? Тогда вам нужна программа детоксикации. Восстановите силы и энергетический баланс.
P.s. Вы часто перегружаете свой организм? Тогда вам нужна программа детоксикации. Восстановите силы и энергетический баланс.