Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
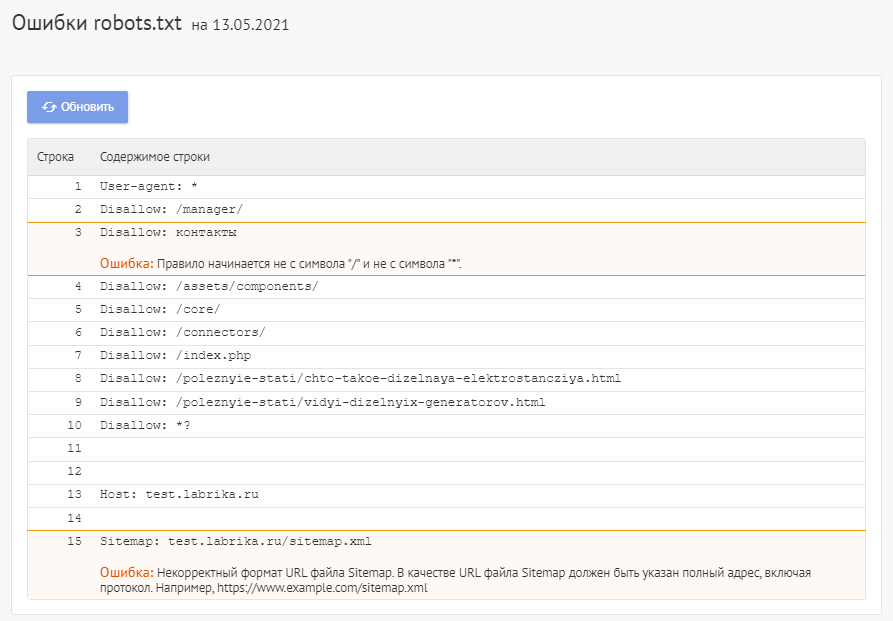
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Обеспечьте поисковым роботам доступ ко всем материалам на вашем сайте. Это позволит вам увеличить доход от своего контента. Ниже описано, как оптимизировать ваш сайт для сканирования и устранить возможные проблемы с доступом роботов Google к вашим страницам.
Настройки в файле robots.txt, обеспечивающие возможность сканирования
Чтобы поисковые роботы Google могли сканировать ваш сайт, убедитесь, что вы предоставили им доступ.
Если вы указали в файле robots.txt, что робот Менеджера рекламы не должен сканировать ваши страницы, то объявления Google не смогут на них показываться. Чтобы наши роботы смогли обрабатывать ваш сайт, внесите изменения в файл robots.txt.
Вам потребуется удалить из файла robots.txt следующие строки:
User-agent: Mediapartners-Google
Disallow: /
После этого наш поисковый робот сможет индексировать контент, опубликованный на ваших страницах, и на них будут показываться объявления Google.
Изменения в файле robots.txt могут не отражаться в нашем индексе до тех пор, пока роботы Google не попытаются снова проиндексировать ваш сайт.
Доступ к контенту, защищенному паролем
Если для доступа к какому-либо контенту на вашем сайте требуется пароль, настройте вход для роботов.
Если эта функция не используется, сайты иногда перенаправляют роботов на страницу входа (это может привести к нарушению правил, связанному с отсутствием контента) или передают им сообщение об ошибке 401 («Неавторизованный запрос») либо 407 («Требуется проверка подлинности на прокси-сервере»). В результате сайт не будет просканирован.
Ошибки категории «Страница не найдена»
Если URL, отправленный в Google, указывает на страницу, которой не существует на сайте, или приводит к появлению сообщения об ошибке 404 («Страница не найдена»), роботы Google не смогут просканировать контент.
Переопределение URL
Если вы переопределяете используемые на сайте URL в ваших тегах объявлений, то у роботов Google могут возникнуть проблемы при попытке получить контент страницы, с которой поступил запрос объявления.
Обычно URL страницы в запросе объявления, который вы отправляете в наши сервисы, должен совпадать с URL страницы, где вы хотите показывать рекламу. Это необходимо для того, чтобы сервисы Google могли получать достоверную информацию о содержании страницы.
Ошибки, связанные с DNS-серверами
Роботам Google не удастся обнаружить ваш контент, если DNS-серверы вашего домена или субдомена некорректно выполняют переадресацию на нужные материалы или если заданы ограничения в отношении источников запросов.
Неработающие или повторяющиеся переадресации
Если на вашем сайте используются переадресации, у роботов Google могут возникнуть проблемы с переходом по ним. Например, если в цепочке переадресаций много шагов и на одном из них произойдет сбой или если в процессе переадресации будут утеряны важные параметры, такие как файлы cookie, то качество сканирования может ухудшиться.
Старайтесь использовать меньше переадресаций на страницах, где размещен код объявлений, и тщательно проверять, правильно ли они работают.
Проблемы с хостингом
Иногда при попытке просканировать сайт серверы не реагируют вовремя, потому что вышли из строя, работают с задержками, перегружены запросами и т. д.
Убедитесь, что ваш поставщик услуг хостинга надежен, а сервер функционирует корректно.
Ограничения, относящиеся к региону, сети или IP-адресу
На некоторых сайтах запрещен доступ для пользователей из отдельных регионов или с определенными IP-адресами. Также бывает, что контент сайта размещен в сети или диапазоне IP-адресов с ограниченным доступом (например, 127.0.0.1).
Рекомендуем снять все ограничения, не позволяющие роботам Google получить доступ к вашим материалам.
Контент, опубликованный совсем недавно
После публикации новой страницы роботы Google могут не успеть просканировать ее, прежде чем она начнет отправлять запросы объявлений. Например, это может относиться к сайтам, на которых регулярно публикуется много нового (в том числе созданного пользователями) контента, такого как новости, выпуски прогноза погоды, а также большие списки товаров.
Обычно при отправке запроса объявления, связанного с новым URL, сканирование контента выполняется в течение нескольких минут. Однако на протяжении этого времени рекламный трафик может быть низким.
Персонализированные страницы, на которых используются параметры URL или динамически создаваемые пути URL
В URL некоторых сайтов добавляется информация, которая имеет отношение только к текущему сеансу. Это могут быть специальные параметры, связанные с выполнившим вход пользователем, например SessionID. В этом случае роботы Google могут посчитать, что URL относится к новой странице, даже если размещенный на ней контент не изменился. Это может привести к тому, что страница будет просканирована спустя несколько минут после первого запроса объявления, а нагрузка на сервер возрастет.
Если контент ваших страниц не зависит от значений URL-параметров, рекомендуем вам удалить эти параметры из URL и передавать информацию на веб-сервер другим способом.
Чем проще структура URL на сайте, тем эффективнее его сканирование.
Данные POST
Если вместе с URL ваш сайт передает данные POST (например, отправляет данные форм в запросе POST), он может отклонять запросы, которые не содержат таких данных. Поскольку роботы Google не предоставляют данные POST, в этом случае у них не будет доступа к вашей странице.
Если контент страницы зависит от данных, указанных пользователем в форме, рекомендуем применять запрос GET.
Robots.txt — это текстовый файл, который показывает поисковым роботам, как сканировать ваш сайт. Он защищает сайт и сервер от перегрузки из-за запросов поисковых роботов.
Если вы хотите заблокировать работу поисковых роботов, важно убедиться в корректности настроек. Это особенно важно, если вы используете динамические URL или другие методы, которые в теории генерируют бесконечное количество страниц.

В этом гайде рассматриваются самые распространенные проблемы с файлом robots.txt, их влияние на сайт и ранжирование в поисковой выдаче, а также способы решения.
Но для начала поговорим подробнее о robots.txt и его альтернативах.
Что такое файл robots.txt
Robots.txt — это файл в простом текстовом формате. Он размещается в корневом каталоге сайта (самый верхний каталог в иерархии). Если файл размещен в другом каталоге, поисковые роботы будут его игнорировать. Несмотря на всю мощь robots.txt, выглядит он как простой текстовый документ. А создать его можно за пару секунд в любом текстовом редакторе.
Выполнять функции robots.txt могут и его альтернативы. Например, метатеги. Их можно размещать в код отдельной страницы.
Можно использовать и HTTP-заголовок X-Robots-Tag, который задает настройки на уровне страницы.
Что делает robots.txt
Файл robots.txt можно использовать для множества целей. Вот несколько самых популярных.
Блокировка сканирования поисковыми роботами определенных страниц
Они все еще могут появляться в поисковой выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
Блокировка медиафайлов для отображения в результатах поиска
Под медиафайлами понимаются изображения, видео и аудиофайлы. Если для файла предусмотрен общий доступ, он будет отображаться, но приватный контент не попадет в поисковую выдачу.

Блокировка файлов ресурсов с неважными внешними скриптами
Если у страницы заблокирован файл ресурсов, поисковые роботы посчитают, что его не существовало вовсе. Это может сказаться на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах поиска. Для этого придется добавить метатег noindex в верхнюю часть страницы.
Насколько опасны ошибки с Robots.txt
Ошибки в robots.txt приводят к определенным последствиям, но обычно не трагичным. А приведение файла в порядок позволит быстро и полностью восстановиться.
Как отмечает сам Google, у поисковых роботов достаточно гибкие алгоритмы. Поэтому незначительные ошибки в файле robots.txt никак не сказываются на их работе. В худшем случае неправильная или неподдерживаемая директива будет проигнорирована. Но если вы знаете, что в файле есть ошибки, их стоит исправить.
Шесть главных ошибок robots.txt
Если ранжирование сайта в поисковой выдаче изменилось странным образом, стоит проверить файл robots.txt. Рассмотрим шесть популярных ошибок подробно.
Ошибка № 1. Robots.txt находится не в корневом каталоге
Поисковые роботы могут найти файл robots.txt только если он расположен в корневом каталоге. Поэтому домен, например, .ru, и название файла robots.txt в URL должна разделять одна косая черта.
Если есть дополнительная папка, скорее всего, поисковые роботы не увидят файл. Сайт в этом случае функционирует так, как будто файла robots.txt нет совсем.
Чтобы исправить эту ошибку, перенесите robots.txt в корневой каталог. Для этого потребуется доступ к серверу. Некоторые системы управления содержимым по умолчанию загружают файл в подпапку с медиафайлами или подобные. Чтобы файл попал в нужное место, придется обойти эту настройку.
Ошибка № 2. Неправильное использование символа-джокера или символа подстановки
Символ-джокер — это символ, используемый для замены других символов или их последовательностей. Robots.txt поддерживает два символа-джокера:
- Звездочка, или астериск (*). Она представляет любые варианты допустимого символа. Своего рода аналог карты джокера.
- Значок доллара $. Обозначает конец URL, позволяет добавлять правила к последней части URL, например, файловое расширение.
При использовании символов-джокеров стоит придерживаться минимализма. Они могут потенциально наложить ограничения на большую часть сайта. Неправильное использование астерикса может привести к блокировке поискового робота. Чтобы решить проблему с неправильным символом-джокером, нужно его найти и переместить или удалить.
Ошибка № 3. Тег noindex в robots.txt
Эта ошибка часто встречается у сайтов, которым уже несколько лет. Google в сентябре 2019 года перестал выполнять команды метатега noindex в файле robots.txt.

Если ваш файл был создан до этой даты или содержит метатег noindex, скорее всего, страницы будут индексироваться Google.
Чтобы решить проблему, примените альтернативный метод. Вы можете добавить метатег robots в элемент страницы <head>, чтобы остановить индексацию.
Ошибка № 4. Блокировка скриптов и страниц стилей
Ограничение доступа к внутреннему JavaScript коду и Cascading Style Sheets (CSS) для поисковых роботов кажется логичным шагом. Однако поисковым роботам Google требуется доступ к CSS и JavaScript файлам, чтобы корректно сканировать HTML и PHP страницы.
Если страницы сайта странно отображаются в поисковой выдаче, проверьте, не заблокирован ли доступ поискового робота к этим внутренним файлам. Удалите соответствующую строку из файла robots.txt.
Если же вам нужна блокировка определенных файлов, вставьте исключение, которое даст поисковым роботам доступ только к нужным материалам.
Ошибка № 5. Отсутствует ссылка на файл sitemap.xml
Этот пункт относится к SEO больше всего. Файл sitemap.xml дает роботам информацию о структуре сайта и его главных страницах. Поэтому есть смысл добавить его в файл robots.txt. Его поисковые роботы Google сканируют в первую очередь.
Строго говоря, это не ошибка, и в большинстве случаев отсутствие ссылки на sitemap в robots.txt не должно влиять на функциональность и внешний вид сайта. Но если вы хотите улучшить продвижение, дополните файл robots.txt
Ошибка № 6. Доступ к страницам в разработке
Запрет сканирования поисковыми роботами рабочих страниц — серьезная ошибка. Как и предоставление им доступа к страницам, находящимся в разработке. Включите запрещающие инструкции в файл robots.txt, если сайт находится на реконструкции. Тогда пользователи не увидят «сырой» вариант.
Кстати, не забудьте убрать соответствующую строчку из файла, когда закончите. Это довольно распространенная ошибка, которая не позволит поисковым роботам правильно сканировать и индексировать сайт
Если ваш сайт еще находится в разработке, но вы видите реальный трафик, или, наоборот, запущенный сайт плохо ранжируется, проверьте строчку User-Agent в файле robots.txt.
User-Agent: *
Disallow: /
Наличие косой черты в строке Disallow делает сайт невидимым для поисковых роботов. Корректируйте строку в соответствии с нужным вам эффектом.
Как восстановиться после ошибок в robots.txt
Если ошибка в файле robots.txt повлияла на отображение в поисковой выдаче, самое главное — скорректировать файл и подтвердить, что новые правила дают нужный эффект. Проверить это можно с помощью инструментов для сканирования, например, Screaming Frog.

Когда убедитесь, что robots.txt работает верно, запросите повторное сканирование поисковыми роботами. В этом поможет Google Search Console. Добавьте обновленный файл sitemap и запросите повторное сканирование страниц, которые пострадали.
К сожалению, нет конкретного срока, в который поисковый робот проведет сканирование и страницы начнут нормально отображаться в поисковой выдаче. Все, что остается — быстро выполнить необходимые шаги и ждать, когда поисковый робот просканирует сайт.
Профилактика важнее всего
Ошибки с файлом robots.txt решаются относительно просто, но лучшим лекарством от них станет профилактика. Редактируйте файл аккуратно, привлекая опытных разработчиков, дважды все проверяйте и, если это актуально, послушайте мнение второго специалиста.
Если есть возможность, протестируйте изменения в песочнице, прежде чем применять их на реальном сервере.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
Это позволит избежать непроизвольных ошибок. И помните, если самое страшное уже случилось, не поддавайтесь панике. Проанализируйте проблему, внесите необходимые изменения в файл robots.txt и отправьте запрос на повторное сканирование. Скорее всего, нескольких дней будет достаточно, чтобы вернуться на прежние позиции в поисковой выдаче.
Поисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots.txt.
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”. В тексте нужно будет прописать страницы, которые можно и нельзя индексировать, указать нужные директивы.
Затем установить галочку в строке «Включить robots.txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.
Содержание:
- Как обнаружить и исправить ошибки в файле robots.txt
- Самые частые ошибки файла robots.txt
- Принципы, которым нужно следовать, чтобы предотвратить ошибки в файле robots.txt
- Проверка robots.txt на ошибки
Каждый уважающий себя веб-мастер должен иметь хотя бы общее представление о том, как управлять процессом индексации страниц и файлов сайта в поисковых системах.
Не будем тянуть резину и сразу отметим, что для нахождения общего языка с поисковыми роботами достаточно правильно настроить robots.txt. Ключевое слово – «правильно». Ведь если допустить в robots.txt ошибки, последствия могут быть довольно неприятными.
Получить бесплатную консультацию от SEO-эксперта по вашему сайту
Самые частые ошибки файла robots.txt
- Перепутанные значения директив (по незнанию или по недосмотру).

- Перечисление нескольких URL в одной директиве Disallow.
- Название файла robots.txt с ошибками.
- В названии файла robots.txt присутствуют заглавные буквы.
- Пустое поле в User-agent.
- Отсутствующая директива Disallow.
![]()
- Неправильный формат URL в директиве Disallow.Ошибка в файле robots.txt на левой половине скриншота приведет к тому, что от индексации будут закрыты все страницы и файлы, в начале URL которых содержится «admin».Все будет указано правильно, если использовать символы «$» и «/» для указания «разрыва».
- Перечисление всех файлов директории. В принципе это не совсем ошибка. Просто рациональнее в этом случае закрыть от индексации всю директорию целиком.
Принципы, которым нужно следовать, чтобы предотвратить ошибки в файле robots.txt
- Прописанные в robots.txt директивы являются рекомендациями, которых придерживаются лишь роботы крупных поисковых систем. Сторонние боты чаще всего на них внимания не обращают. Поэтому их лучше блокировать по IP.
- Заблокированные в robots.txt страницы все еще продолжают быть доступными интернет-пользователям. Поэтому если цель – скрыть веб-страницу не только от роботов, но и от пользователей, на нее нужно установить пароль.
- Поддомены рассматриваются поисковиками как отдельные сайты. Поэтому рекомендации по их индексации следует прописывать в отдельных robots.txt в корне каждого поддомена.
- robots.txt нечувствителен к регистру. Поэтому директивы можно писать как строчными, так и прописными. Но имена файлов и директорий должны прописываться только так, как они выглядят в адресной строке браузера.
- Указанный в директиве User-agent реагирует на все указанные под ним директивы вплоть до следующей строки с User-agent. Поэтому не стоит надеяться, что директивы под вторым User-agent будут выполнены роботом, указанным в первом User-agent. Для каждого робота указания нужно дублировать.
Проверка robots.txt на ошибки
Чтобы проверить robots.txt на ошибки, проще всего воспользоваться предназначенными для этого инструментами от поисковых систем.
В случае с Google нужно зайти в Search Console/Сканирование и выбрать «Инструмент проверки файла robots.txt».
![]()
Под окном с содержимым искомого файла можно увидеть количество ошибок и предупреждений.
В Яндекс.Вебмастере имеется аналогичный функционал (Инструменты/Анализ robots.txt).
![]()
Также имеется возможность узнать, сколько в проверяемом robots.txt ошибок.
Правда, если обе проверки покажут, что ошибок нет, это еще не повод радоваться. Это лишь значит, что прописанные в файле инструкции соответствуют стандартам.
Но в нем вполне могут быть многие из вышеописанных ошибок, которые приведут к проблемам с индексацией сайта. Поэтому при проверке robots.txt на ошибки не стоит полагаться лишь на подобные автоматизированные инструменты – нужно и самому все внимательно проверять.
Чувствуете что бизнесу нужен апгрейд?
Получить бесплатную консультацию от специалиста по вашему проекту
Подробнее